코사인 유사도(Cosine Similarity)
- Similarity를 객관적으로 판단하는 지표 : 코사인 유사도
- 벡터의 크기(스케일)를 무시하고, 오직 벡터 간의 방향에만 초점을 맞춤
- 단어 임베딩이나 문서 임베딩과 같은 고차원 벡터 표현에서 두 벡터 간의 각도를 기반으로 유사도를 계산하는 데 유용함
- 곱하기 / 나누기 개념, 벡터 사이의 각도를 측정해서 두 벡터가 얼마나 유사한지 측정
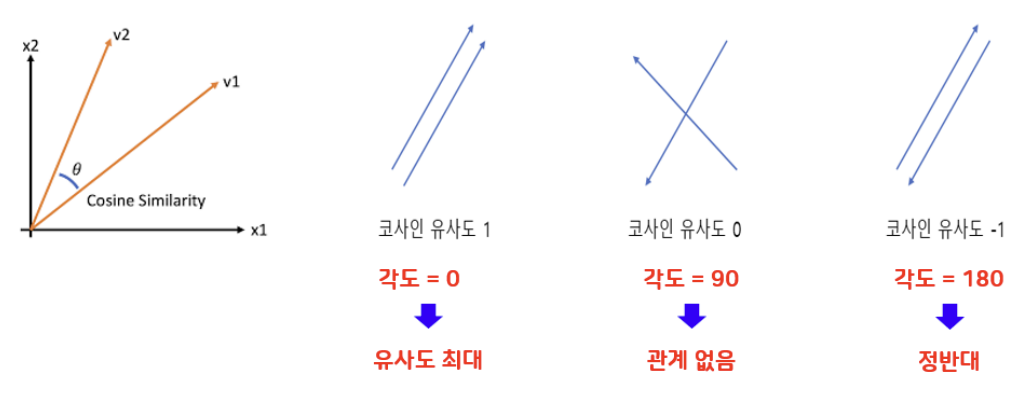
- 두 벡터 사이의 각도 : 0 ~ 180
- 1: 두 벡터가 동일한 방향을 가리키며, 완벽하게 유사함
- 0: 두 벡터가 직교하며, 유사도가 없음
- -1: 두 벡터가 정반대 방향을 가리키며, 완전히 반대됨
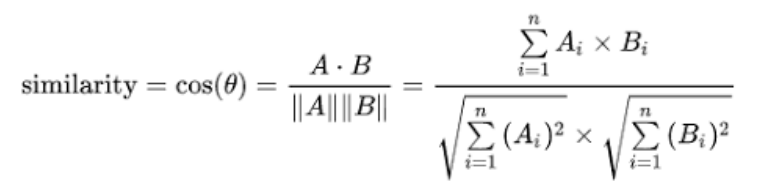
코사인 유사도(Cosine Similarity) 구현
- sklearn.metrics.pairwise.cosine_similarity 사용
- 필요한 라이브러리 임폴트
- from sklearn.metrics.pairwise import cosine_similarity
- similarity = cosine_similarity (X, Y)
- 적용 : 유사도 기반 챗봇 개발, 유사도 기반 추천 함수 구현
(이 시리즈의 모든 코드는 코랩환경에서 Python으로 작성하였습니다)
(코드가 이해가 안간다면 참고하세요)
[NLP 4] tokenization 2 : mecab & kiwipiepy
[NLP 6] Embedding 1 : BoW - CountVectorizer
Cosine Similarity Code 1 (텍스트 데이터 및 모델 생성)
# 필요한 함수 임폴트
from sklearn.metrics.pairwise import cosine_similarity
# 유사도 측정할 텍스트 데이터 생성
en_sentences = ["What should I do to be a great scientist?",
"How can I be a good scientist?"]
ko_sentences = ["직원이 무단 퇴사를 했는데 손해 배상 청구할 수 있나요?",
"무단 퇴사한 직원에 대한 손해 배상 청구가 가능한가요?"]# CountVectorizer 함수 호출, 모델 생성
ko_cv = CountVectorizer(token_pattern=r"(?u)\b\w+\b")
en_cv1 = CountVectorizer()
en_cv2 = CountVectorizer(stop_words='english')Cosine Similarity Code 2 (영어 텍스트 데이터에 대한 유사도 측정)
# 영어 텍스트 데이터에 대한 단어 사전 생성
# 불용어 제거 X
en_lower = []
for sent in en_sentences:
en_lower.append(sent.lower())
en_cv1.fit(en_lower)
en_voca1 = en_cv1.vocabulary_
sorted_voca = sorted(en_voca1.items(), key=lambda item: item[1])
en_voca1 = {word: index for index, (word, _) in enumerate(sorted_voca)}
print(en_voca1)
# 불용어 제거 O
en_cv2.fit(en_lower)
en_voca2 = en_cv2.vocabulary_
sorted_voca = sorted(en_voca.items(), key=lambda item: item[1])
en_voca2 = {word: index for index, (word, _) in enumerate(sorted_voca)}
print(en_voca2)# 임베딩할 영어 텍스트 데이터 생성
en_sentences1 = [en_lower[0]]
en_sentences2 = [en_lower[1]]
# 불용어 제거 X
x1 = en_cv1.transform(en_sentences1).toarray()
y1 = en_cv1.transform(en_sentences2).toarray()
print(x1)
print(y1)
print(f'\n{"-"*80}\n')
# 불용어 제거 O
x2 = en_cv2.transform(en_sentences1).toarray()
y2 = en_cv2.transform(en_sentences2).toarray()
print(x2)
print(y2)# 영어 텍스트에 대한 코사인 유사도 확인
# 불용어 제거 X
en_cs1 = cosine_similarity(x1, y1)
print(en_cs1)
# 불용어 제거 O
en_cs2 = cosine_similarity(x2, y2)
print(en_cs2)Cosine Similarity Code 3 (한글 텍스트 데이터에 대한 유사도 측정)
# 한글 텍스트 데이터 불용어 처리
import kiwipiepy
kw2 = kiwipiepy. Kiwi()
stopword2 = kiwipiepy.utils.Stopwords()
ko_list = []
for sent in ko_sentences:
sentence = []
morphs_list = kw.tokenize(sent, stopwords=stopword)
for morph, _, _, _ in morphs_list:
sentence.append(morph)
string = ' '.join(sentence)
ko_list.append(string)
print(ko_list)# 한글 텍스트 데이터에 대한 단어 사전 생성
ko_cv.fit(ko_list)
ko_voca = ko_cv.vocabulary_
sorted_voca = sorted(ko_voca.items(), key=lambda item: item[1])
ko_voca = {word: index for index, (word, _) in enumerate(sorted_voca)}
print(ko_voca)# 임베딩할 한글 텍스트 데이터 생성
ko_sentences1 = [ko_list[0]]
ko_sentences2 = [ko_list[1]]
# transform 함수 호출
x = ko_cv.transform(ko_sentences1).toarray()
y = ko_cv.transform(ko_sentences2).toarray()
print(x)
print(f'\n{"-"*80}\n')
print(y)# 한글 텍스트에 대한 코사인 유사도 확인
ko_cs = cosine_similarity(x, y)
print(ko_cs)Q1) 코사인 유사도를 구할때 의미적으로 가까운 단어는 결과에 영향을 주는가?
- 코사인 유사도는 단순히 벡터 간의 각도를 계산하는 방식이기 때문에 의미적 유사성은 직접적으로 반영되지 않는다. 즉, 문장을 벡터변환 했을때 얼마나 유사한지만 측정함
Q2) CountVectorizer를 활용하여 코사인 유사도를 구할때 음수값을 나오게 하려면?
- CountVectorizer는 0과 1로 임베딩하기 때문에 코사인 유사도의 최소값이 0이다 즉, 코사인 유사도가 음수가 나오려면 다른 방식으로 임베딩 해야한다
참고자료
sklearn.metrics.pairwise.cosine_similarity 공식 문서
+ (좋은 글인거 같아 추가 했습니다)
코사인 유사도를 함부로 사용하지 말것

AI & Robotics