
Chapter 1. 강화 학습이란
바둑에서 시작하여 게임, 금융, 로봇까지 수많은 분야에서 강화학습을 통해 전례 없는 수준의 AI가 만들어졌습니다. 기존 학습 방법론과 어떤 차이가 있었기에 이런 도약이 가능했을까요? 그에 대한 답은 강화 학습이 무엇인가라는 작은 이야기부터 시작합니다.
1.1. 지도학습과 강화학습
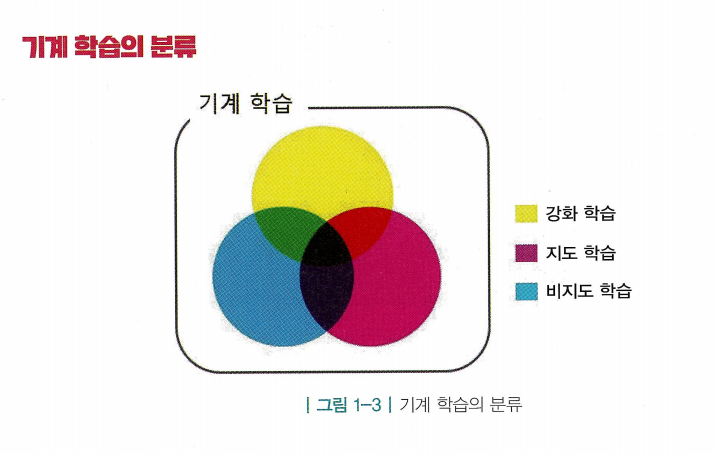
- 인공지능&AI(Artificial Learning) : 학술적으로 엄밀히 정의되지 않는, 대중적인 용어. 따라서 경계가 명확하지않음
- 기계 학습(Machine Learning) : 기계에게 무언가를 배우게 하는 것, 인공지능을 구현하는 하나의 방법론
- 지도 학습(Supervised Learning) : 지도자(supervisor)혹은 정답이 있는 상태에서 학습(learning)
- 정답이 주어져 있는 학습 데이터(training data)를 사용하여 데이터 안의 input과 output 사이 관계를 학습하여 예측 모델을 만듬
- 이런 특징(feature)을 이용하여 모델을 만들 수도 있지만 딥러닝(Deep Learning)을 통해 자동으로 feature를 추출하여 학습할 수도 있음
- 테스트 데이터(test data) : 정답을 모르지만 궁극적으로 맞히고자 하는 데이터
- 지금까지 한번도 본적이 없는 데이터여야함
- 지금까지 한번도 본적이 없는 데이터여야함
- 정답이 주어져 있는 학습 데이터(training data)를 사용하여 데이터 안의 input과 output 사이 관계를 학습하여 예측 모델을 만듬
- 비지도 학습(Unsupervised Learning) : 학습데이터의 특징(분포)를 학습
- ex) 군집화 (Clustering) : 주어진 데이터 중에서 성질이 비슷한 것들끼리 묶음
- ex) 군집화 (Clustering) : 주어진 데이터 중에서 성질이 비슷한 것들끼리 묶음
- 강화학습(Reinforcement Learning) : 시행착오(trial and error)를 통해 학습
- “순차적 의사결정 문제에서 누적 보상을 최대화 하기 위해 시행착오를 통해 행동을 교정하는 학습 과정”
1.2. 순차적 의사결정 문제
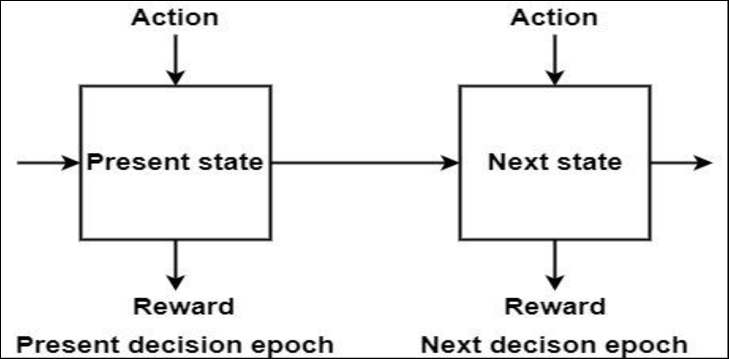
- 순차적 의사결정(sequential decision making) : 각 상황에 따라 하는 행동이 다음 상황에 영향을 주며, 결국 연이은 행동을 잘 선택해야 하는 문제
- ex) 주식투자, 운전하는 상황, 게임
- ex) 주식투자, 운전하는 상황, 게임
- 세상에는 순차적 의사결정 문제가 많은 상황에서 발생함. 강화학습은 이런 중요한 문제를 풀기 위해 고안된 방법론임
1.3. 보상
- 보상(reward) : 의사결정을 얼마나 잘하고 있는지 알려주는 신호
- 강화 학습의 목적은 과정에서 받는 보상의 총합, 즉 누적 보상(cumulative reward)을 최대화하는 것
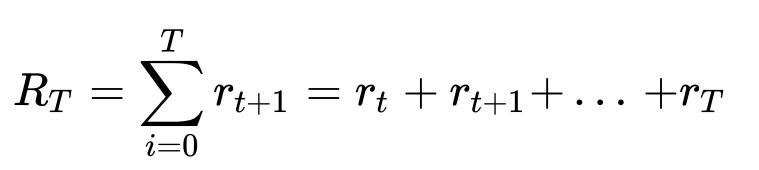
- 여기서 는 환경을 최종 상태 로 이끄는 행동의 보상
- 여기서 는 환경을 최종 상태 로 이끄는 행동의 보상
- 강화 학습의 목적은 과정에서 받는 보상의 총합, 즉 누적 보상(cumulative reward)을 최대화하는 것
- 보상의 특징
- 보상은 “어떻게”에 대한 정보를 담지 않고 있음. 어떠한 행동을 하면 그것에 대해 “얼마나” 잘 하고 있는지 평가해줄 뿐, 어떻게 해야 높은 보상을 얻을 수 있는지 알려주지 않음
- 그렇기 때문에 수많은 시행착오를 통해 사후적으로 보상이 낮았던 행동을 덜 하고, 보상이 높았던 행동을 더 하면서 보상을 최대화하도록 행동을 수정함
- 그렇기 때문에 수많은 시행착오를 통해 사후적으로 보상이 낮았던 행동을 덜 하고, 보상이 높았던 행동을 더 하면서 보상을 최대화하도록 행동을 수정함
- 보상은 스칼라(scalar)값이다. 벡터(vector)값과 다르게 크기를 나타내는 값 하나로 이루어져 있음
- 보상이 벡터라면 동시에 2개이상의 값을 목표로 할 수 있지만 스칼라이기 때문에 오직 하나의 목적만을 가져야함
- 즉, 목표(x,y,z)에 대한 가중치값(w1,w2,w3)를 통해 최종적으로 라는 식으로 표현됨
- 강화학습은 스칼라 형태의 보상이 있는 경우에만 적용할 수 있음 > 문제를 단순화하여 하나의 목표로 설정해야함
- 강화학습은 스칼라 형태의 보상이 있는 경우에만 적용할 수 있음 > 문제를 단순화하여 하나의 목표로 설정해야함
- 보상이 희소(sparse)할 수 있으며 또 지연(delap)될 수 있음.
- 보상은 선택했던 행동의 빈도에 비해 훨씬 가끔 주어지거나, 행동이 발생한 후 한참 뒤에 나올 수 있고 이 때문에 행동과 보상의 연결이 어려워짐 > 어떤 행동에 의한 보상인지 불분명해짐
- 이런 문제를 해결하기 위해 벨류 네트워크(value network)등의 아이디어가 등장함
- 이러한 특성은 지도학습과 강화학습의 본질적 차이임. 강화학습에서 다루는 문제는 순차적 의사결정 문제이기 때문에 순차성, 즉 시간에 따른 흐름이 중요하고 이 흐름에서 보상이 뒤늦게 주어지는 것이 가능하기 때문
- 보상은 “어떻게”에 대한 정보를 담지 않고 있음. 어떠한 행동을 하면 그것에 대해 “얼마나” 잘 하고 있는지 평가해줄 뿐, 어떻게 해야 높은 보상을 얻을 수 있는지 알려주지 않음
1.4. 에이전트와 환경
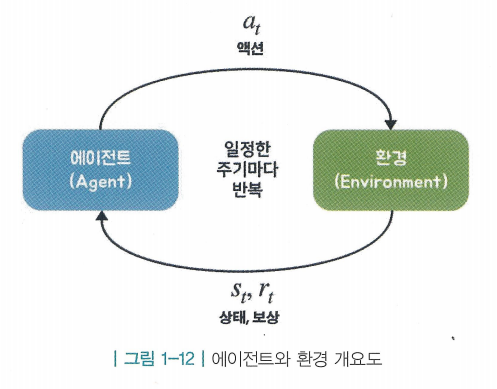
-
순차적 의사결정 문제를 도식화 한것
- 에이전트(Agent)가 행동(action)을 하고 그에 따라 상황이 변하는 것을 하나의 루프(loop)라 했을 때 이 루프가 끊임없이 반복되는 것이 순차적 의사결정 문제임
- 에이전트(Agent)가 행동(action)을 하고 그에 따라 상황이 변하는 것을 하나의 루프(loop)라 했을 때 이 루프가 끊임없이 반복되는 것이 순차적 의사결정 문제임
-
에이전트 : 강화학습의 주체, 학습하는 대상이며 동시에 환경(Environment) 속에서 행동을 하는 개체임
- 에이전트는 어떤 액션을 할지 정하는 것이 가장 주된 역할임. 에이전트 입장에서의 루프는 다음 3단계로 이루어져 있음
- 현재 상황 에서 어떤 액션을 해야 할지 를 결정
- 결정된 행동 를 환경으로 보냄
- 환경으로부터 그에 따른 보상과 다음 상태의 정보를 받음
- 에이전트는 어떤 액션을 할지 정하는 것이 가장 주된 역할임. 에이전트 입장에서의 루프는 다음 3단계로 이루어져 있음
-
환경 : 에이전트를 제외한 모든 요소. 에이전트가 어떤 행동을 했을 때, 그 결과에 영향을 주는 모든 요소들임
- 상태(state) : 현재 상태에 대한 모든 정보를 숫자로 표현하여 기록한 것
- 현재의 위치, 정도, 각도 등을 숫자로 엮은 하나의 벡터
- 현재의 위치, 정도, 각도 등을 숫자로 엮은 하나의 벡터
- 상태 변화(state transition) : 환경 속에서 에이전트가 어떤 행동을 하고 나면 에이전트의 상태가 바뀌는것, 즉 행동의 결과를 알려줌
- 환경이 하는 일은 다음과 같은 단계로 이루어짐
- 에이전트로부터 받은 액션 를 통해서 상태 변화를 일으킴
- 그 결과 상태는 → 로 바뀜
- 에이전트에게 줄 보상 도 함께 계산됨
- 과 을 에이전트에게 전달
- 상태(state) : 현재 상태에 대한 모든 정보를 숫자로 표현하여 기록한 것
- 이처럼 에이전트가 에서 를 시행하고, 이를 통해 환경이 로 바뀌면, 즉 에이전트와 환경이 한 번 상호 작용하면 하나의 루프가 끝남. 이를 한 틱(tick)이 지났다고 표현함
- 실제 세계는 앞의 그림과 다르게 시간의 흐름이 연속적(continuous)이겠지만 순차적 의사결정 문제에서는 시간의 흐름을 이산적(discrete)으로 생각함
- 이산적이란, 뚝뚝 끊어져서 변화가 발생한다는 뜻. 그리고 그 시간의 단위를 틱 혹은 타임 스텝(time step)이라고 함
1.5. 강화 학습의 위력
- 병렬성의 힘 : 강화학습은 경험을 쌓는 부분의 병렬성을 쉽게 증가시킬 수 있음
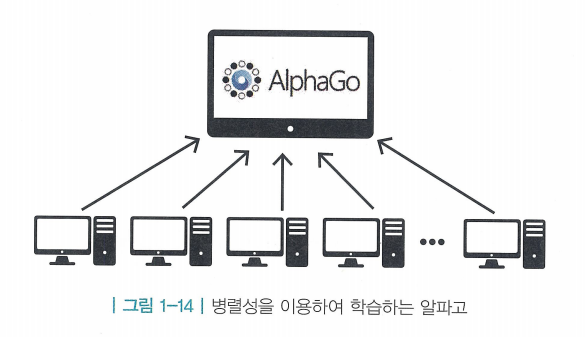
- 시뮬레이터(simulator) : 경험을 쌓는 부분
- 중앙에 뇌에 해당하는 부분이 있고, 이와 연결된 수백, 수천 대의 컴퓨터에서 병렬적으로 시뮬레이션이 진행됨. 그리고 각 컴퓨터에서 진행된 시뮬레이션 결과는 모두 중앙으로 모여서 결과적으로 cumulative reward가 증가하는 방향으로 진행함
- 자가 학습(self-learning)
- 지도 학습은 무언가 자꾸 정답을 알려주는 반면, 강화 학습은 혼자 놔두고 알아서 성장하길 기다림. 그러다 보니 굉장히 유연하고 자유로우며 성능면에서 뛰어남
- 알파고가 사람을 뛰어넘는 것이 가능했던 이유는 자가 학습에 기반을 둔 강화 학습 덕분임. 승리라는 목표만 알려줬을 뿐 그 과정은 알아서 찾도록 했기 때문에 충분한 계산 능력(computational power)과 어우러져 사람이 생각해낼 수 없는 수를 찾아냄
- 지도 학습은 무언가 자꾸 정답을 알려주는 반면, 강화 학습은 혼자 놔두고 알아서 성장하길 기다림. 그러다 보니 굉장히 유연하고 자유로우며 성능면에서 뛰어남
<번외>
지도 학습 + 강화학습 : 역강화학습(Inverse Reinforcement Learning)
비지도 학습 + 강화학습 : 표현기반 강화학습(Representation-Driven Reinforcement Learning)
지도 학습 + 비지도 학습 + 강화학습 : 자기지도 강화학습(Self-Supervised Reinforcement Learning)

AI & Robotics