Chapter 2. 마르코프 결정 프로세스
문제를 풀기 위해서는 먼저 문제가 잘 정의되어야 합니다. 강화 학습에서 문제를 잘 정의하려면 주어진 문제를 MDP(Markov Decision Process)의 형태로 만들어야 합니다. 이번 챕터에서는 MDP에 대해 자세히 알아보겠습니다.
2.1. 마르코프 프로세스 (Markov Process)
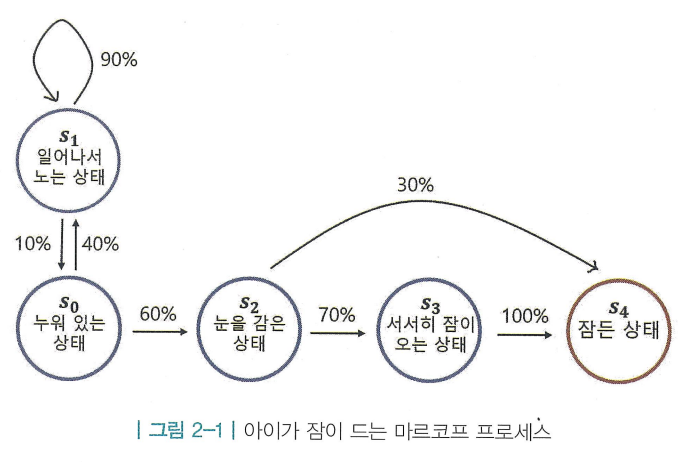
- 마르코프 프로세스 (Markov Process, MP) : 미리 정의된 어떤 확률 분포를 따라서 상태와 상태 사이를 이동하며, 각각에 해당하는 확률이 있고, 그 확를에 따라 다음 상태가 정해지는 프로세스
- 상태(state) : ~
- 상태 전이(state transition) : 현재 상태에서 다음 상태로 전이되는 것
- 종료 상태(terminal state) : 도달하는 순간 마르코프 프로세스가 끝이 나는 상태
- 상태의 집합( ) : 가능한 모든 상태들의 집합
- 전이 확률 행렬( ) : 전이 확률(transition probability) 는 상태s에서 다음 상태 로 전이될 확률
- 를 조건부 확률이라는 개념을 이용해서 다른 방식으로 표현이 가능함
- 시점 에서 상태 에 있을 때, 다음 시점 에서 상태 이 될 확률
- 를 조건부 확률이라는 개념을 이용해서 다른 방식으로 표현이 가능함
- 전이 확률 행렬 (Transition Probability Matrix) : 마르코프 프로세스에서 전이 확률 은 모든 상태쌍 에 대해 정의되므로, 이를 행렬 형태로 표현할 수 있기 때문에 전이 확률이 아닌 ‘전이 확률 행렬’이라고 부름

- 상태 공간 의 크기가 이라면, 는 행렬임
- 전이 확률 행렬의 각 행은 확률 분포이므로, 각 행의 원소 합은 1이 됨
마르코프 성질(Markov Property)
-
- “미래는 오로지 현재에 의해 결정된다”
- 마르코프 프로세스의 모든 상태는 마르코프 성질을 따름
- 현재 상태 이전에 방문했던 상태들 에 대한 정보는 미래 상태 를 결정하는 데에 아무런 영향을 주지 못함
- 마르코프한 상태 : 과거와 무관하게, 현재 상태만으로 다음 행동(수)을 결정할 수 있는 상태
- 마르코프 하지 않은 상태 : 현재 상태만으로는 충분하지 않고, 과거 정보(속도, 방향 등)가 추가로 필요해 다음 행동을 결정할 수 없는 상태
2.2. 마르코프 리워드 프로세스 (Markov Reward Process, MRP)
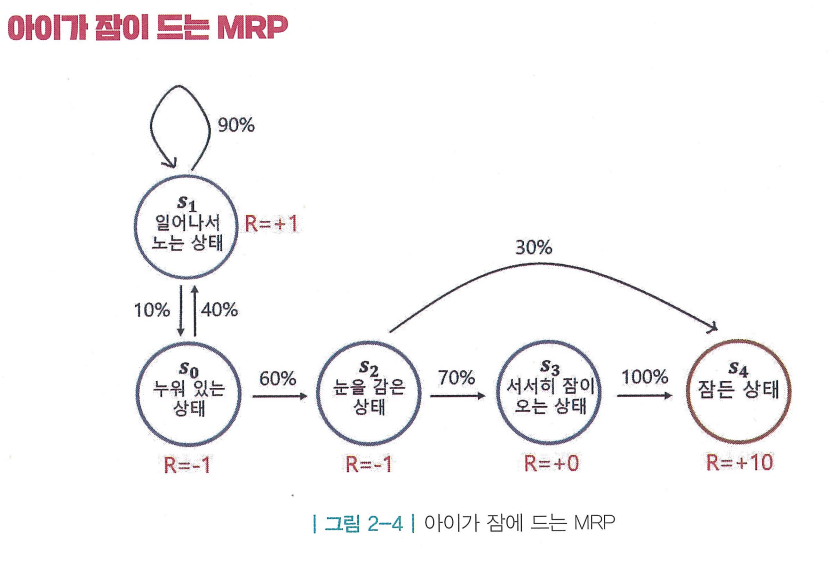
- 마르코프 리워드 프로세스(Markov Reward Process, MRP) : 마르코프 프로세스에 보상의 개념이 추가된 것. 어떤 상태에 도착하게 되면 그에 따른 보상을 받게됨
- 상태의 집합( ) : 가능한 모든 상태들의 집합 (MP의 와 같음)
- 전이 확률 행렬( ) : 상태 s에서 다음 상태 로 전이될 확률을 행렬로 표현 (MP의 와 같음)
- 보상 함수( ) : 은 어떤 상태 s에 도착했을 때 받게 되는 보상
- 기대값( : expectation)이 등장한 이유는 특정 상태에 도달했을 때 받는 보상이 매번 다를 수도 있기 때문에 고정된 값이 필요함
- 기대값( : expectation)이 등장한 이유는 특정 상태에 도달했을 때 받는 보상이 매번 다를 수도 있기 때문에 고정된 값이 필요함
- 감쇠 인자( ) : (Gamma)는 0에서 1사이의 숫자이며, 강화 학습에서 미래에 얻을 보상에 비해 당장 얻는 보상을 얼마나 더 중요하게 여길 것인지를 나타내는 파라미터
- 미래에 얻을 보상의 값에 가 여러번 곱해지며, 그 값을 작게 만듬
감쇠된 보상의 합, 리턴(Return) : “강화학습은 리턴을 최대화하도록 학습하는 것”
- MRP에서는 MP와 다르게 상태가 바뀔 때마다 해당하는 보상을 얻음
- 상태 에서 보상 를 받고 시작하여 종료 상태인 에 도착할 때 보상 를 받으며 끝이남
- (아래 첨자는 타임 스텝, 즉 시간을 의미함)
- (아래 첨자는 타임 스텝, 즉 시간을 의미함)
- 에피소드(episode) : 시작 상태 에서 부터 종료상태 까지의 전체 경로를 의미함
- 이런 표기법을 이용하여 바로 리턴 를 정의하게됨
-
- 리턴 : 시점 t부터 미래에 받을 감쇠된 보상의 합
- 이면 단기 보상을, 이면 장기 보상을 중시함
- 이런 표기법을 이용하여 바로 리턴 를 정의하게됨
- 리턴은 과거의 보상을 고려하지 않고 미래의 보상을 통해서 정의된다
가 필요한 이유
- =0일 경우, 미래의 보상이 모두 0이되기 때문에 탐욕적(greedy)인 에이전트가 됨
- =1일 경우, 현재희 보상과 미래의 보상이 완전히 대등하기 때문에 장기적인 시야를 가진 에이전트가 됨
- 수학적 편리성 : 이기 때문에 MRP를 무한한 스텝동안 진행하더라도 가 무한한 값이 될 수 없음
- 사람의 선호 반영: 가까운 시점의 보상에 더 높은 가치를 부여
- 미래에 대한 불확실성 반영: 시간이 지날수록 다양한 확률적 요소들에 의해 예측이 어려워지는 리스크를 반영
에피소드의 샘플링
- 하나의 에피소드 안에서 방문하는 상태들은 매번 다름. 즉 매번 에피소드가 어떻게 샘플링(sampling)되는 지에 따라 리턴이 달라지게 됨
- 샘플링 : 어떤 확률 분포가 존재할 때 해당 분포에서 샘플을 뽑아보는 것
- 많은 경우 실제 확률 분포를 잘 모르는 경우가 대부분이기 때문에 샘플링을 통해서 어떤 값을 유추하는 방법론을 사용함 > Monte-Carlo 접근법
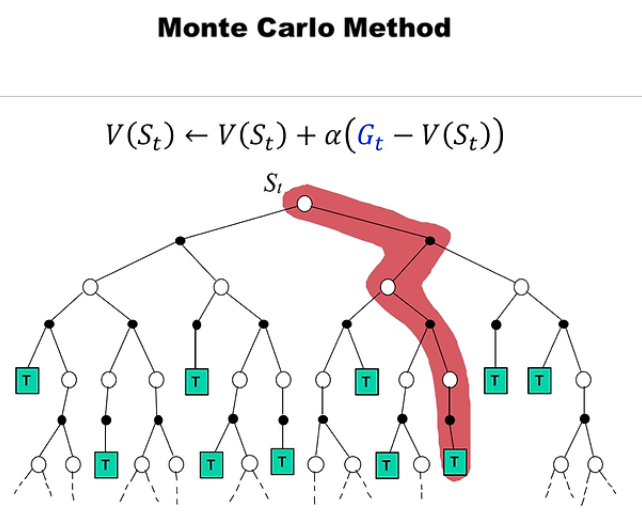
- 많은 경우 실제 확률 분포를 잘 모르는 경우가 대부분이기 때문에 샘플링을 통해서 어떤 값을 유추하는 방법론을 사용함 > Monte-Carlo 접근법
상태 가치 함수(State Value Function)
- MRP의 목표는 특정 상태 s의 밸류(value)혹은 가치를 평가하는 것. 이는 상태 s에서 시작했을 때 받을 리턴의 기댓값으로 측정할 수 있음
- 상태 가치 함수(v(s)) : 상태를 인풋으로 넣으면 그 상태의 밸류를 아웃풋으로 출력하는 함수. 에피소드마다 리턴이 다르기 때문에 어떤 상태 s의 밸류 v(s)는 기댓값을 이용하여 정의함
- : 상태 s로부터 시작하여 얻는 리턴의 기댓값
- 시점 t에서 상태 s부터 시작하여 에피소드가 끝날 때까지의 리턴을 계산함

- 시점 t에서 상태 s부터 시작하여 에피소드가 끝날 때까지의 리턴을 계산함
2.3 마르코프 결정 프로세스 (Markov Decision Process, MDP)
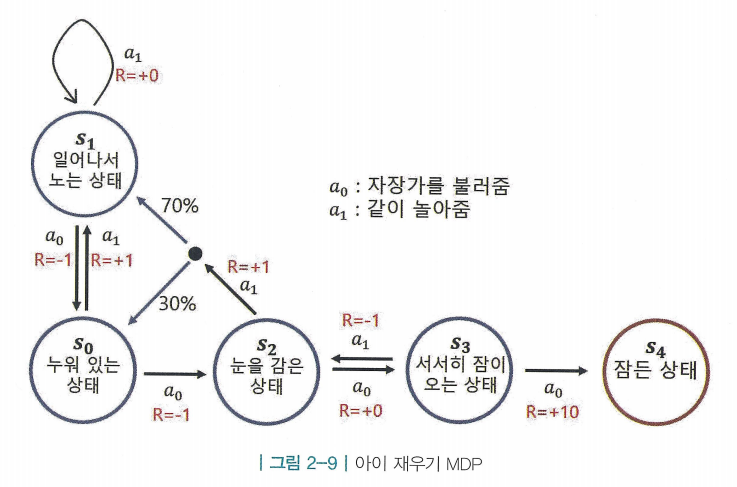
- MP와 MRP에 경우 상태 변화가 자동으로 이루어짐. 즉, 순차적 의사결정 문제를 모델링 할 수 없음
- 마르코프 결정 프로세스 (Markov Decision Process, MDP) : 순차적 의사결정 문제의 핵심인 의사결정(decision)을 모델에 포함 시키기 위해, 자신의 의사를 가지고 행동하는 주체인 에이전트를 포함함
- MDP를 정의하기 위해 액션의 집합 A를 추가함. A가 추가되면서 기존의 P, R의 정의도 MRP와 달라짐
- 상태(s)는 환경의 일부이며, 에이전트가 조절할 수 없음. 즉, 확률 값을 바꿀 수는 없음
- 상태의 집합( ) : 가능한 모든 상태들의 집합 (MP와 MRP의 와 같음)
- 액션의 집합( ) : 에이전트가 취할 수 있는 액션들을 모아놓은 것. 에이전트는 스텝마다 액션의 집합 중에서 하나를 선택함
- 전이 확률 행렬( ) : 전이 확률 는 현재 상태가 s이며 에이전트가 액션 a를 선택했을 때 다음 상태가 이 될 확률
- 주의) 같은 상태 s에서 같은 액션 a를 선택해도 매번 다른 상태에 도착할 수 있음. 즉, 액션 실행 후 도달하는 상태 에 대한 확률 분포가 있고 그것이 전이 확률 행렬( )임
- 조건 : 현재 상태 s에서, 액션 a를 했을때
- 조건 : 현재 상태 s에서, 액션 a를 했을때
- 보상 함수( ) : 는 상태 s에서 액션 a를 선택하면 받게 되는 보상
- 현재 상태 s에서 어떤 액션을 선택하느냐에 따라 받는 보상이 달라짐
- 받는 보상은 확률적으로 매번 바뀔 수 있기 때문에 기대값을 이용하여 표기함
- 받는 보상은 확률적으로 매번 바뀔 수 있기 때문에 기대값을 이용하여 표기함
- 감쇠 인자( ) : 미래에 얻을 보상에 비해 당장 얻는 보상을 얼마나 더 중요하게 여길 것인지를 나타내는 파라미터 (MRP의 와 같음)
정책 함수와 2가지 가치 함수
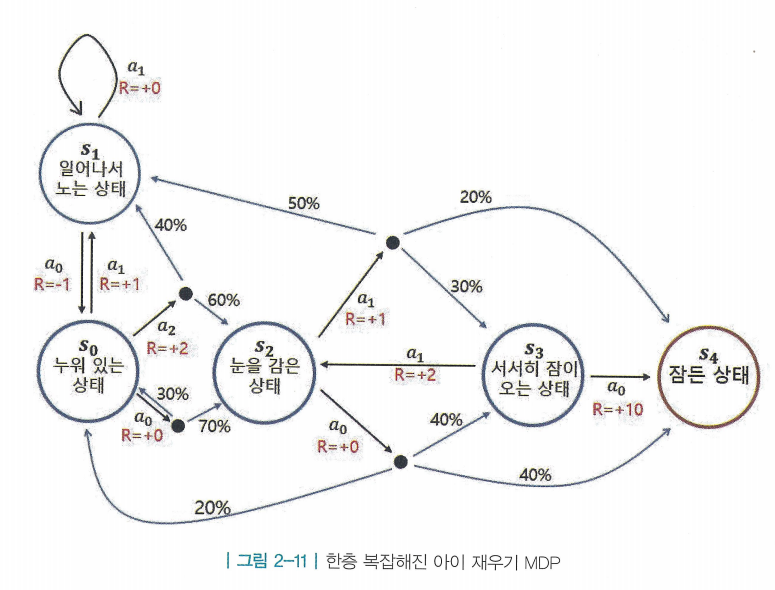
- MDP가 복잡해지면 최적 행동을 찾는 것이 어려워짐. 핵심은 “각 상태 s에 따라 어떤 액션 a를 선택해야 보상의 합을 최대로 할 수 있는가” > 이를 정책(policy)라고 함
- 정책 혹은 정책 함수(Policy Function) ( ) : 각 상태에서 어떤 액션을 선택할지 정해주는 함수. 에이전트의 목적은 보상의 합을 최대화하는 정책을 찾는것
- : 정책 함수를 확률을 이용하여 정의
- 상태 s에서 액션 a를 선택할 확률
- (이를 확률적 정책이라 하며, 결정론적 정책은 로 정의한다)
- 각 상태에서 할 수 있는 모든 액션의 확률 값을 더하면 1이 되어야 함
- 주의) 정책 함수는 에이전트 안에 존재함. 즉, 환경에 대한 그림에선 정책에 대한 내용(상태별 액션을 얼마큼의 확률로 고를지에 대한 내용)이 포함 되지 않음
- : 정책 함수를 확률을 이용하여 정의
- 환경은 변하지 않지만 에이전트는 자신의 정책을 언제든 수정할 수 있으며, 더 큰 보상을 얻기 위해 계속해서 정책을 교정해 나가는 것이 곧 강화학습임
- MDP에서의 상태 가치 함수 : 에이전트의 정책 함수에 따라서 얻는 리턴이 달라지기 때문에 가치 함수는 정책 함수에 의존적임
- 가치 함수를 정의하기 위해서는 먼저 정책 함수 가 정의되어야 함
- ( 가 주어졌다고 가정 했을 때 가치 함수의 정의)
- s부터 끝까지 를 따라서 움직일 때 얻는 리턴의 기대값
- 가치 함수를 정의하기 위해서는 먼저 정책 함수 가 정의되어야 함
- 상태-액션 가치 함수(State-Action Value Function) ( ): 어떤 상태에서 특정 행동을 했을 때 앞으로 얼마나 보상을 받을지를 나타내는 함수
- 상태에 따라 액션의 결과가 달라지기 때문에 함수에 상태와 액션이 동시에 인풋으로 들어감.
- s에서 a를 선택하는 것의 밸류가 나옴. a를 선택하고 나면 상태를 진행하기 위해 액션을 선택해야 하는데, 그 역할을 정책 함수 에게 맡김
- s에서 a를 선택하는 것의 밸류가 나옴. a를 선택하고 나면 상태를 진행하기 위해 액션을 선택해야 하는데, 그 역할을 정책 함수 에게 맡김
- 상태-액션 가치 함수는 상태와 액션의 페어, 즉 (s, a)를 평가하는 함수임
- ( 와 동일하게 미래에 얻을 리턴 를 통해 밸류를 측정하며, 정책 에 따라 이후의 상태가 달라지므로 를 고정시키고 평가함)
- s에서 a를 선택하고, 그 이후에는 를 따라서 움직일 때 얻는 리턴의 기댓값
- 상태에 따라 액션의 결과가 달라지기 때문에 함수에 상태와 액션이 동시에 인풋으로 들어감.
- 와 는 “s에서 어떤 액션을 선택하는가”하는 부분만 차이가 존재함
- 를 계산할 때는 s에서 가 액션을 선택함
- 를 계산할 때는 s에서 강제로 a를 선택함 > 액션을 선택한 이후에는 2가지 가치 함수 모두 정책 함수 를 따라서 에피소드가 끝날 때까지 진행됨
- 를 계산할 때는 s에서 가 액션을 선택함
MP, MRP, MDP 요약 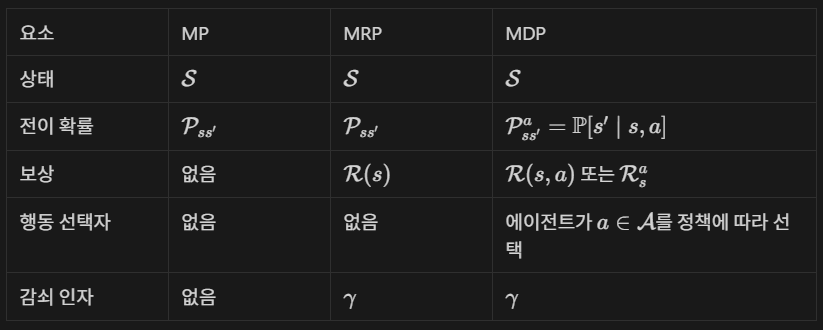
2.4 Prediction과 Control
- 큰 흐름에서 강화 학습은 문제와 솔루션으로 나눌 수 있고, 문제의 세팅이라 함은 주어진 상황이 있을 때 이를 MDP의 형태로 만들어서, MDP를 풀고자 하는 것임
- MDP가 주어 졌을때, 즉 이 주어졌을 때 task는 크게 Prediction과 Control로 볼 수 있음
1. Prediction: 정책 가 주어졌을 때, 각 상태의 값을 평가하는 문제
2. Control: 최적의 정책(optimal policy) 를 찾는 문제
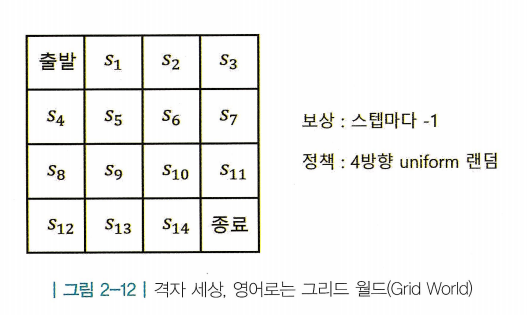
- Prediction : 특정 상태 s의 밸류 의 값을 구하는 문제. 즉, 해당 상태의 밸류를 예측하는것이 목표
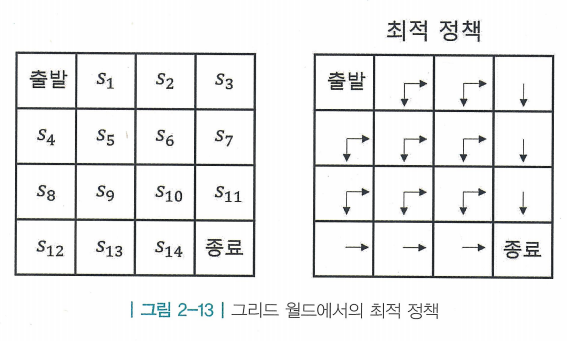
- Control : 최적의 정책 를 찾는 것이 목표. 최적의 정책이란 이 세상에 존재하는 모든 중에서 가장 기대 리턴이 큰 를 뜻함
- 최적 정책 를 따를 때의 가치 함수를 최적 가치 함수(optimal calue function)이라고 하며 로 표기함
- 와 를 찾았다면 “이 MDP는 풀렸다”라고 함.
"강화 학습을 이용해 실생활의 어떤 문제를 MDP 형태로 만들고, 그 MDP의 최적 정책과 최적 가치 함수를 찾아내어 MDP를 푸는 것이 목적이다"

AI & Robotics