신경망을 이용해 액션 밸류 네트워크를 학습하면 그게 곧 하나의 애이전트가 될 수 있습니다. 아타리 게임을 플레이 하던 DQN이 바로 이 방식입니다. 이번 챕터에서는 가치 함수만을 가지고 움직이는 에이전트, 즉 가치 기반 에이전트에 대해 알아보겠습니다.
- 이번 문제는 더이상 제약 조건이 없는 상황임
- 여전히 Model-free이며
- 상태공간(state space)과 액션 공간(ation space)이 매우 커서 밸류를 테이블에 담지 못하는 상황 → 신경망 사용
- 강화학습에 신경망을 사용하는 대표적인 2가지 방법론
- 나 를 신경망으로 표현 하는 방식
- 함수 자체를 신경망으로 표현하는 방식
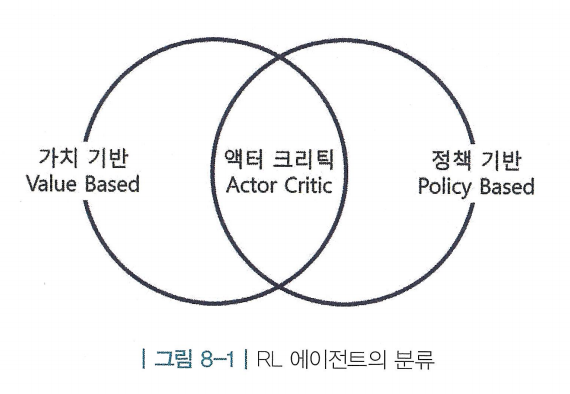
- 가치 기반(value-based) : 에이전트가 가치 함수에 근거하여 액션을 선택함
- 즉, q(s, a)의 값을 통해 액션을 선택하는 것
- 가치 기반 에이전트는 액션을 선택할 때 가치 함수만 있으면 되므로, 정책 함수를 따로 정의 하지않음
- ex) SARSA, Q-Learning
- ex) SARSA, Q-Learning
- 정책 기반(policy-based) : 에이전트가 정책함수 를 보고 직접 액션을 선택함
- 밸류를 통해서 액션을 선택하지 않으며, 가치 함수를 따로 정의하지 않음
- 만을 통해 MDP에서 경험을 쌓고 활용하며, 학습 과정에서 를 강화함
- 액터-크리틱(actor-critic) : 가치 함수와 정책 함수를 모두 사용함
- actor는 “행동하는 주체”, 즉 정책 를 의미하며, critic은 “비평가”, 즉 v(s) 또는 q(s,a)를 의미함
- 이름 그대로 행동하는 와 평가하는 v(혹은 q)가 함께 존재함
8.1 밸류 네트워크의 학습
- 밸류 네트워크(value-network) : 뉴럴넷으로 이루어진 가치 함수
- : 뉴럴넷의 파라미터. 만약 뉴럴넷에 포함된 파라미터가 100개 라면 세타는 길이가 100인 벡터임 (처음엔 랜덤으로 초기화 되어있음)
- : 뉴럴넷의 파라미터. 만약 뉴럴넷에 포함된 파라미터가 100개 라면 세타는 길이가 100인 벡터임 (처음엔 랜덤으로 초기화 되어있음)
- 상태별 별류의 값을 라고 가정했을 때 손실함수를 다음과 같이 표현 할 수 있다
- 이는 어떤 s에 대해 위 값을 계산할 것인지에 대해 정의를 하지 않았기 때문에 엄밀한 정의는 아님
- 모든 상태 s에 대해서 를 최소화하기 매우 어렵기 때문에 다음과 같이 정의함
- 여기서 기댓값 연산자 는 정책 함수 를 이용해 방문했던 상태 s에 대해 를 계산하라는 뜻
- 를 이용해 데이터를 모으고 그 데이터를 이용해 학습하면, 손실 함수에서 가 자주 방문하는 상태의 가중치는 더 높아지고, 가 거의 방문하지 않는 상태의 가중치는 낮아지는 성질이 추가됨
- 는 상수이기 때문에 체인 룰(chain rule)을 사용하여 얻을 수 있는 식인 임을 이용
- (앞에 곱해지는 상수 2는 생략) → 상수값은 나중에 를 이용해 조절 가능
- (앞에 곱해지는 상수 2는 생략) → 상수값은 나중에 를 이용해 조절 가능
- 는 상수이기 때문에 체인 룰(chain rule)을 사용하여 얻을 수 있는 식인 임을 이용
- 의 값을 실제로 계산하려면 를 이용하여 움직이는 에이전트를 통해 샘플을 뽑아야함
- 가 상태 s를 방문했다고 가정하고, 이 과정을 여러 번 반복하면 우변이 좌변으로 수렴함
- 가 상태 s를 방문했다고 가정하고, 이 과정을 여러 번 반복하면 우변이 좌변으로 수렴함
- 이후 업데이트 진행
- 가 없으면 손실 함수를 정의할 수 없어 그라디언트 계산이 불가능함 → MC, TD 활용하여 해결
첫 번째 대안 : 몬테카를로 리턴
- MC : 시점 t에서 시작하여 에피소드가 끝날 때까지 얻은 감쇠된 누적 보상을 리턴 를 이용하여 업데이트하는 방식
- 실제 가치 함수의 정의가 곧 의 기대값이기 때문에 대신 사용 가능
- 실제 가치 함수의 정의가 곧 의 기대값이기 때문에 대신 사용 가능
- 뉴럴넷을 업데이트하려면 손실 함수를 정의해야함 → 대신 사용
- 뉴럴넷을 업데이트하려면 손실 함수를 정의해야함 → 대신 사용
- 이후 업데이트 진행
두 번쨰 대안 : TD 타깃
- TD : 한 스텝 더 진행해서 추측한 값을 이용하여 현재의 추측치를 업데이트하는 방식
- TD 타깃인 활용
- TD 타깃인 활용
- 이후 업데이트 진행
- 이후 업데이트 진행
- 여기서 값은 변수가 아닌 상수임 (MC도 동일)
- 항이 포함되어 있지만, 업데이트 시점의 를 이용하여 의 값을 계산할 경우 상수로 취급됨 → 편미분 값 : 0
- 만약, 상수로 취급하지 않을 경우 업데이트 되는 값과 목표가 함께 움직이기 때문에 학습이 매우 불안정해짐
8.2 딥 Q러닝
- 가치 기반 에이전트는 명시적 정책(explicit policy)이 따로 존재하지 않음
- 를 사용하지 않고, q(s, a)를 활용하여 액션을 선택하기 때문
- 즉, 정책은 암묵적 정책(implicit policy)임
- 를 사용하지 않고, q(s, a)를 활용하여 액션을 선택하기 때문
이론적 배경 - Q러닝
- Q러닝 : 벨만 최적방정식을 이용해 최적의 를 학습함
- 딥 Q러닝은 Q러닝에 뉴럴넷으로 환장한것
- 즉, Q(s,a)가 아닌 로 표기
- 즉, Q(s,a)가 아닌 로 표기
- 를 정답으로, 이것과 사이 차이의 제곱을 손실 함수로 정의함
- 손실 함수를 정의할 때에는 기댓값 연산자()가 반드시 필요
- 같은 s에서 같은 a를 선택한다 하더라도 매번 다른 상태에 도달할 수 있기 때문
- 같은 s에서 같은 a를 선택한다 하더라도 매번 다른 상태에 도달할 수 있기 때문
- 실제 뉴럴넷을 업데이트할 때는 샘플 기반 방법론으로 를 무시하고 계산함
- 이 식을 통해 를 계속해서 업데이트해 나가면 는 에 가까워짐
- 기댓값 연산자를 없애기 위해 여러 개의 샘플을 뽑아서 그 평균을 이용해 업데이트를 진행하는데, 이처럼 복수의 데이터를 모아 놓은 것을 미니 배치(mini-batch)라고 함
- 미니 배치 업데이트 : 미니 배치를 이용해 업데이트 하는 방식
- 미니 배치 업데이트 : 미니 배치를 이용해 업데이트 하는 방식
- “하나의 미니 배치를 구성하는 데 몇 개의 데이터를 사용할 것인가”를 미니 배치 사이즈(mini-batch size)라고 함
- 미니 배치의 크기가 커질수록 더 정확한 그라디언트를 계산할 수 있지만, 한 번에 소모해버리는 데이터가 많아짐
딥 Q러닝 pseudo code
- 의 파라미터 를 초기화
- 에이전트의 상태 s를 초기화
- 에피소드가 끝날 때까지 다음(A~E)를 반복
A. 에 대한 -greedy를 이용하여 액션 a를 선택
B. a를 실행하여 r과 s'을 관측
C. s'에서 에 대한 greedy를 이용하여 액션 a'을 선택
D. 업데이트:
E.- 에피소드가 끝나면 다시 2번으로 돌아가서 가 수렴할 때까지 반복
- 환경에서 실제로 액션을 선택하는 부분 : 3-A
- TD 타깃의 값을 계산하기 위한 액션을 선택하는 부분 : 3-C
- 실제로 실행되지 않고, 업데이트를 위한 계산에만 사용
- 행동 정책(-greedy )과 타깃 정책(greedy )는 서로 다름
- 손실함수에서 한 번 미분된 형태 : 3-D
- 라이브러리를 사용할 경우 계산할 필요없이, 손실함수만 정의함
- 라이브러리를 사용할 경우 계산할 필요없이, 손실함수만 정의함
익스피리언스 리플레이와 타깃 네트워크
- DQN(Deep Q-Network)
- DQN paper (nature)
- 본질은 뉴럴넷을 활용하여 Q함수를 강화하는것
- 논문에서는 학습을 안정화하고 성능을 끌어 올리기 위해 2가지 방법을 사용함
- 익스피리언스 리플레이(Experience Replay)와 타깃 네트워크(Target Network)
익스피리언스 리플레이(Experience Replay)
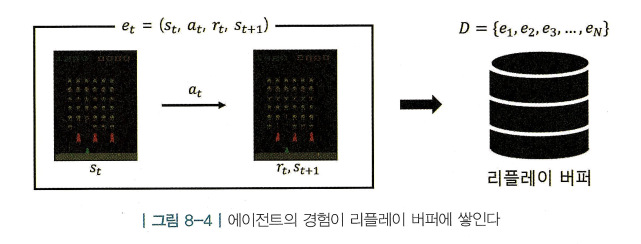
- Experience Replay는 과거의 겪었던 경험을 재사용하는것
- 경험은 여러 개의 에피소드로 이루어져 있고, 에피소드는 여러 개의 상태 전이(transition 또는 트랜지션)로 이루어져있음
- 경험은 여러 개의 에피소드로 이루어져 있고, 에피소드는 여러 개의 상태 전이(transition 또는 트랜지션)로 이루어져있음
- 하나의 상태 전이 는 ()로 표현 가능
- “상태 에서 액션 를 했더니 보상 을 받고 다음 상태 에 도착 하였다” → 하나의 상태 전이가 곧 하나의 데이터임
- “상태 에서 액션 를 했더니 보상 을 받고 다음 상태 에 도착 하였다” → 하나의 상태 전이가 곧 하나의 데이터임
- 낱개의 데이터를 재사용하기 위해 리플레이 버퍼(replay buffer)사용
- 버퍼에 가장 최근 데이터 n개를 저장하는 것
- 학습할 때는 이 버퍼에서 임의의 데이터를 뽑아서 사용함 → 랜덤하게 뽑다 보면 각각의 데이터가 여러 번 재사용될 수 있음 (데이터 효율성 증가)
- 또한 랜덤하게 데이터를 뽑다 보면 하나의 미니 배치 안에서 서로 다른 데이터들이 섞이게됨
- 연속된 데이터를 사용할 때 보다 각각의 데이터 사이 상관성(correalation)이 작아서, 더 효율적으로 학습할 수 있음
- 버퍼에 가장 최근 데이터 n개를 저장하는 것
별도의 타깃 네트워크(Target Network)
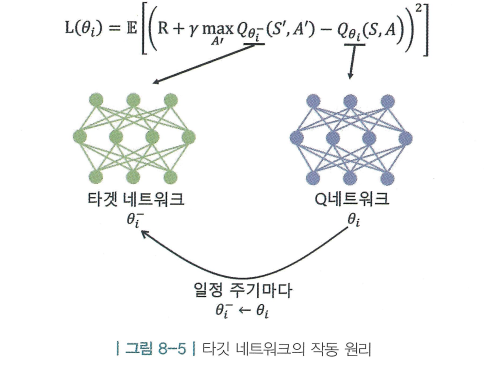
- 손실 함수 의 직관적 의미는 정답과 추측 사이의 차이이며, 이 차이를 줄이는 방향으로 가 업데이트 됨
- 하지만, Q러닝에서는 이 정답으로 사용되기 때문에 정답이 에 의존적임
- 가 업데이트 될 때마다 정답에 해당하는 값이 계속해서 변함
- 뉴럴넷을 학습할 때 정답지가 자주 변하는 것은 학습의 안정성을 매우 떨어뜨림
- 타겟 네트워크의 아이디어 : 정답을 계산할 때 사용하는 네트워크인 타깃 네트워크와 학습을 받고 있는 Q 네트워크, 이렇게 두 개의 네트워크를 준비하고, 정답지를 계산할 때 사용하는 네트워크의 파라미터를 잠시 얼려두는 것
- 변하지 않도록 얼린 파라미터 를 고정해놓고 정답지를 계산하면 정답이 안정적인 분포를 가지게 됨
- 그 사이 학습을 받고 있는 네트워크의 파라미터는 이렇게 계속해서 업데이트 됨
- 그리고 일정 주기마다 얼려 놓았던 를 최신 파라미터로 교체함
- 변하지 않도록 얼린 파라미터 를 고정해놓고 정답지를 계산하면 정답이 안정적인 분포를 가지게 됨
- 즉, 학습 도중에는 똑같이 생긴 두 쌍의 파라미터가 사용됨
- 학습 대상이 되는 Q네트워크의 파라미터 와 정답지 계산에 쓰이는 파라미터 가 공존하게됨
DQN 구현
- OpenAI Gym 카트폴 구현
- 오른쪽, 왼쪽 항상 2가지의 액션
- 스텝마다 +1의 보상을 받으며, 막대를 넘어뜨리지 않고 오래 균형을 잡아야 보상이 최대가 됨
- 막대가 수직으로 부터 15도 이상 기울어지거나, 카트가 화면 끝으로 나가면 종료
- 카트의 상태 s는 길이 4의 벡터
- s = (카트의 위치, 카트의 속도, 막대의 각도, 막대의 각속도)
- 오른쪽, 왼쪽 항상 2가지의 액션
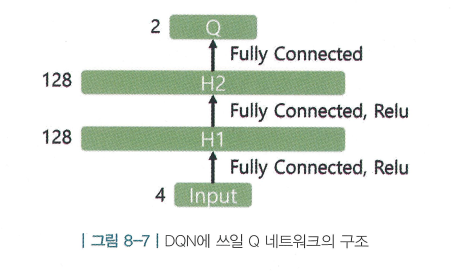
- forward 함수의 뉴럴넷 구조
- 상태 s를 의미하는 길이 4의 인풋 벡터가 들어가며, 모든 액션에 대한 각 액션의 밸류인 Q(s,a)를 리턴함
- 카트폴에서 선택할 수 있는 액션은 2개이기 때문에 아웃풋의 차원은 2임
- Q함수 구현하는 방식
- s와 a를 한번에 인풋으로 받아 그 밸류를 리턴하는 형태
- s만 인풋으로 받아 모든 액션에 대한 밸류값들을 한 번에 리턴하는 형태 → 원래 DQN 논문의 구현 방식
- 결과

AI & Robotics