커다란 MDP의 세계를 항해하기 위해서 우리에게는 또 다른 무기가 하나 필요합니다. 바로 “딥러닝”입니다. 딥러닝과 강화 학습이 만나 Deep RL이라는 유연하고도 범용적인 방법론이 탄생합니다. 이번 챕터에서는 먼저 딥러닝에 대한 이야기부터 시작합니다.
7.1 함수를 활용한 근사
- 테이블 기반 방법론으로 학습을 하려면 상태 s마다 그에 해당하는 밸류를 적어 놓기 위해, 총 상태의 개수만큼 테이블이 커져야함
- ex) 체스 : , 바둑 : → 10의 170승만큼의 상태가 존재
- 상태의 개수가 무한해지는 경우도 있음 (ex- 속도)
- 연속적인 상태 공간(continuous state space) : 상태값이 바둑이나 체스처럼 이산적(discrete)일 수도 있지만, 실수 범위 내에서 연속적인 값을 가질 수도 있음
- 상태 공간이 연속적이면 테이블을 만들기 불가능함
함수의 등장
- 함수 에 v(s)나 q(s, a)를 저장한다고 가정했을때, (100, 1), (200, -10)은
- 로 표현 가능함
- 이를 통해 a와 b의 값을 추정하면 a = -0.11, b = 12임
- s와 v(s)의 쌍의 데이터를 통해서 파라미터 a,b의 값을 조정하는 것임
- 즉, 는 상태 값을 인풋으로 받아 가치 값을 내놓는 함수가 되므로, 이를 실제 가치 함수의 근사 함수(function approximator)라고 할 수 있음
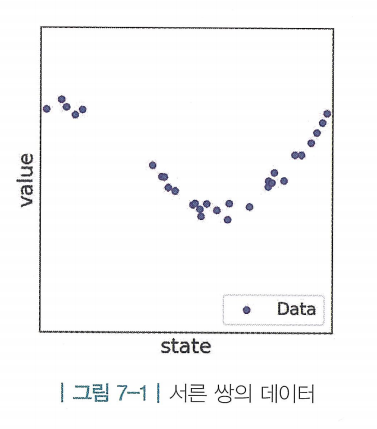
- 데이터가 많아지면 모든 선을 지나는 직선을 그릴 수 없음 → 모든 점들을 가장 “가깝게” 지나는 선으로 표현함
- 최소제곱법(least squares) : 각각의 데이터를 이라고 표현한다면
-
- 위의 식(=오차의 제곱의 합)을 최소화하는 a와 b를 찾는 방법론
- 데이터의 개수와 무관하게 표현한다면 각 오차의 제곱 합을 평균내고, MSE(Mean Squared Error(평균제곱오차))를 최소화하는 것
- 데이터의 개수와 무관하게 표현한다면 각 오차의 제곱 합을 평균내고, MSE(Mean Squared Error(평균제곱오차))를 최소화하는 것
-
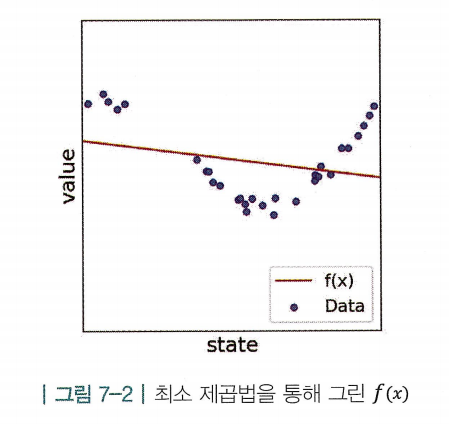
- MSE를 최소화하는 a와 b를 구하여 그린
- 함수의 곡선이 데이터에 가깝게 지나도록 피팅(fitting)해야함 → 선형식 만이 최선은 아님
함수의 복잡도에 따른 차이
- 1차 함수에서 n차 함수로 차수가 점점 올라갈수록 함수는 더 유연해지고, 더 복잡한 데이터에도 피팅할 수 있음
- “함수를 피팅한다”의 의미
- 함수에 데이터를 기록한
- 데이터 점들을 가장 가깝게 지나도록 함수를 그려본다
- 함수 의 파라미터 의 값을 찾는다.
- 함수 를 학습한다
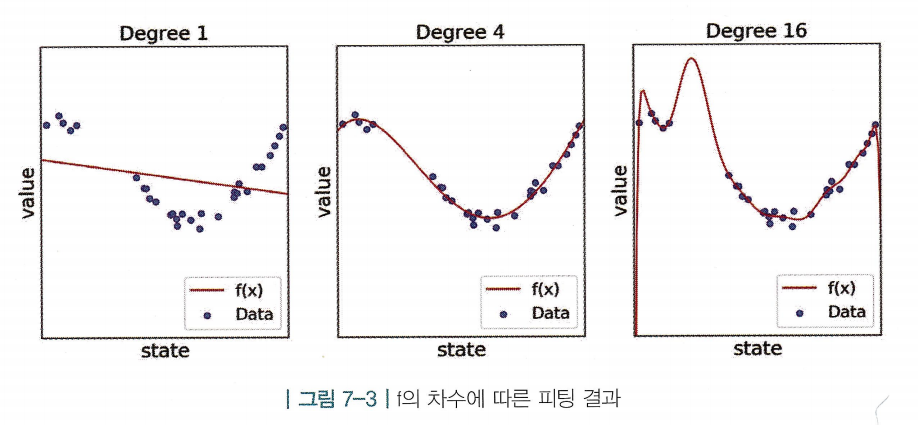
- 1차, 4차, 16차 함수를 이용한 피팅 결과의 평균 에러(MSE)는 각각 0.3, 0.03, 0.00000002임
- 하지만, 데이터에는 노이즈(noise)가 섞여있기 때문에 무조건 차수가 높은 함수가 좋은 것은아님
오버 피팅과 언더 피팅
- 오버 피팅(over fitting) : 를 정할 때, 너무 유연한 함수를 사용하여 가 노이즈에 피팅해버리는 것
- 언더 피팅(under fitting) : 실제 모델을 담기에 함수 의 유연성이 부족하여 주어진 데이터와의 에러가 큰 상황
- MDP에서도 똑같은 정책 로 똑같은 상태 s에서 출발하여도 매번 다른 리턴을 받음 → 노이즈
- 데이터를 생성하는 함수 F를 찾는것이 목표임
- 상태에 따른 리턴의 쌍이 모두 데이터가 되며 여기서 데이터를 생성해준 함수 F는 가치함수 가 됨
- 상태에 따른 리턴의 쌍이 모두 데이터가 되며 여기서 데이터를 생성해준 함수 F는 가치함수 가 됨
- 임의의 F에 대한 식
-
- 실제 데이터를 생성하는 함수 도 F에 노이즈 을 추가하여 정의함
- , ()
- 은 표준 정규 분포에서 샘플링된다고 가정
- , ()
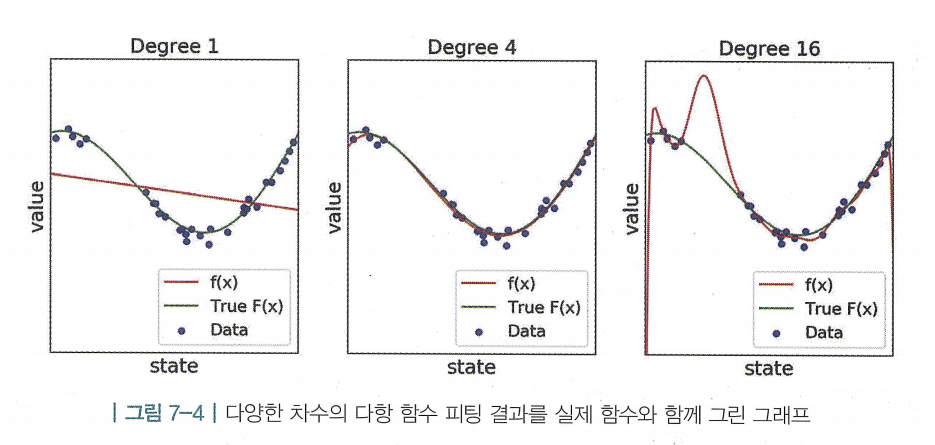
- 30개의 쌍를 통해 표현함
- 빨간색 선 : 1차~16차함수까지의 f를 설정하여 학습시킴
- 초록색 선 :
- 파란색 점 : 로부터 샘플링된 값
- 목표 :초록색 선과 가장 가까워지도록 하는 빨간 선을 찾는것
- 1차 함수는 프리 파라미터(free-parameter)가 적기 때문에 유연하지 못함 → 언더 피팅
- 16차 함수는 모든 데이터를 가장 에러 없이 학습했지만, 과하게 유연하여 이 가지고 있는 노이즈까지 모두 정확하게 학습하게됨 → 오버 피팅
함수의 장점 - 일반화
- 문제가 커질 경우, 테이블에 모든 v(s)나 q(s,a)를 저장할 수 없음
- 그렇기 때문에 실제 v(s)를 모방하는 함수 를 학습 시킨것
- 그렇기 때문에 실제 v(s)를 모방하는 함수 를 학습 시킨것
- 즉, 함수를 통해 일반화(generalization)를 잘 해야함
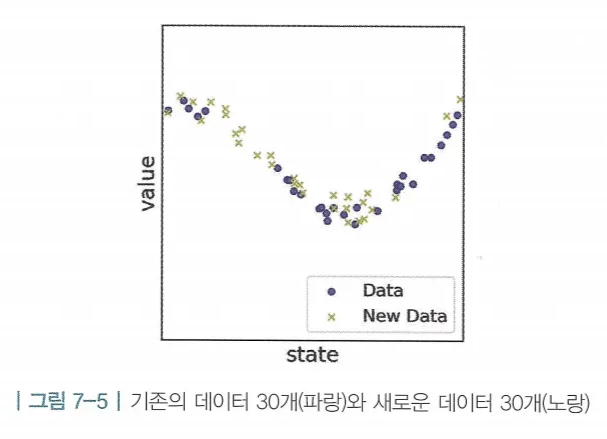
- 새로운 데이터가 추가된 경우, 테이블 기반 방법론을 사용하면 새로운 상태에 대한 값이 비어있기 때문에 어떤 밸류를 갖게 될지 알 수 없음
- 하지만 함수를 통해 일반화를 진행할 경우(일반화가 잘 된 경우) 처음 보는 데이터에 대해서도 예측을 통해 알 수 있음
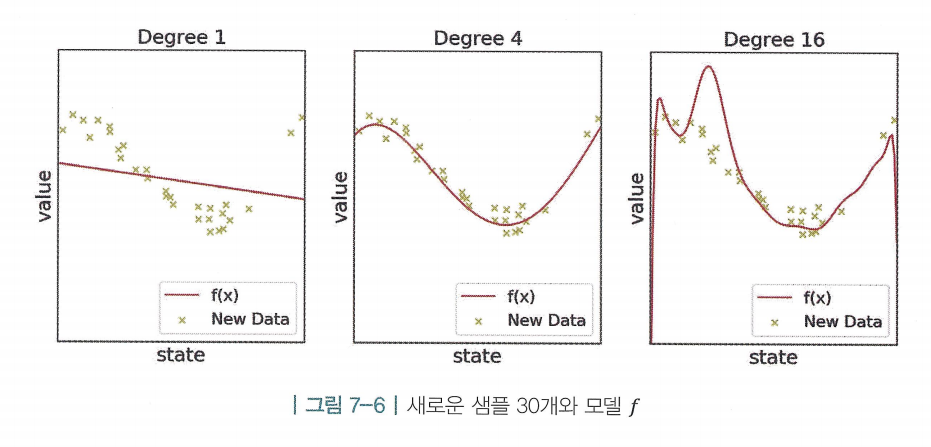
- 언더 피팅된 1차 함수와 오버 피팅된 16차 함수 모두 새로운 데이터를 일반화하여 표현하는 성능이 매우 부족함
- 여기서 빨간 선을 그리는 데에 노란색 데이터는 아예 사용되지 않음
7.2 인공 신경망의 도입
신경망
- 인공 신경망(Artificial Neural Network) : 신경망의 본질은 매우 유연한 함수인 것 → 매우 유연하기 때문에 세상의 어떤 복잡한 관계에도 피팅할 수 있음
- 함수에 포함된 프리 파라미터의 개수를 통해 함수의 유연성을 표현할 수 있는데, 신경망의 경우 100만 개가 넘음
- (Large Model의 경우 1000억 개 이상)
- (Large Model의 경우 1000억 개 이상)
- 함수에 포함된 프리 파라미터의 개수를 통해 함수의 유연성을 표현할 수 있는데, 신경망의 경우 100만 개가 넘음
- 이러한 인공 신경망을 통해 상태별 가치 값을 담는 것이 Deep RL 학습임
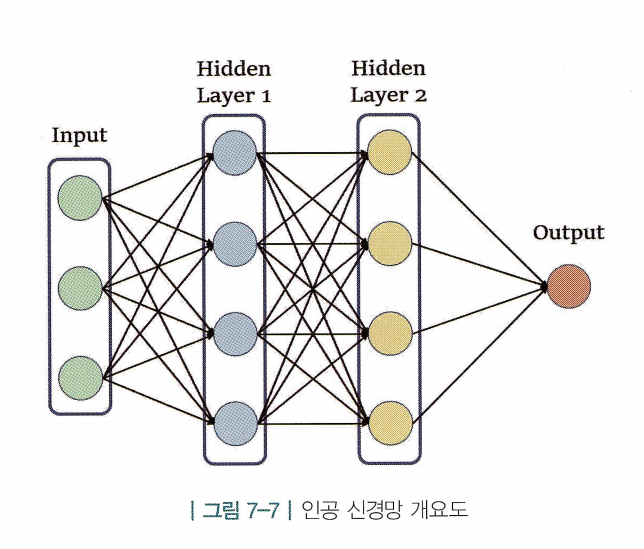
- 크기가 3인 벡터를 인풋으로 받아 값 하나를 리턴하는 신경망
- 형태로 표현 가능
- 히든 레이어(hidden layer)가 두 층이 쌓여 있고, 각각의 히든 레이어는 여러 개의 노드(node)로 구성됨
- 즉, 노드가 신경망의 기본 구성 단위임
- 노드는 해당 노드로 들어오는 값들을 선형 결합(linear combination)한 후에 비선형 함수(non-linear activation)를 적용함
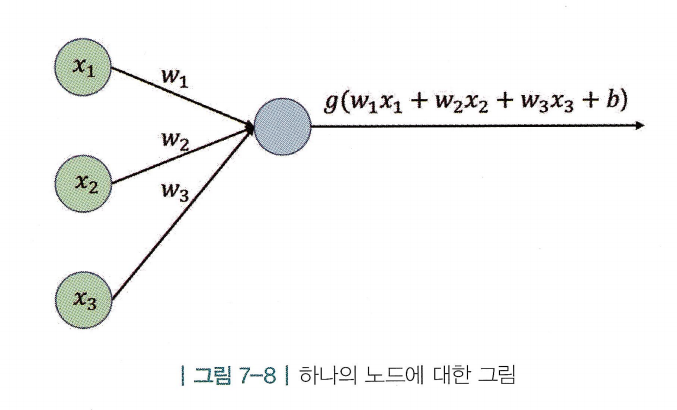
- 해당 노드로 들어오는 3개의 값()을 선형결합 하여 의 값으로 만든 후 비선형 함수 g(x)를 통과 시킴
- 대표적인 비선형 함수 : RELU(rectified linear unit)
- RELU :
- RELU :
- 대표적인 비선형 함수 : RELU(rectified linear unit)
- 선형 결합 : 새로운 피쳐(feature)를 만드는 과정. 이 피쳐는 인풋 벡터의 피쳐보다 한층 더 추상화(abstract)된 피처임
- 학습에 필요한 피쳐가 있다면 신경망의 파라미터들이 알맞은 값으로 학습됨
- 학습에 필요한 피쳐가 있다면 신경망의 파라미터들이 알맞은 값으로 학습됨
- 비선형 함수 : 인풋과 아웃풋의 관계가 비선형 관계일 수 있기 때문에 사용됨
- 선형 관계만 학습하게 되면 신경망의 표현력이 실제 자연의 많은 문제를 표현하기 어려움
- 선형 관계만 학습하게 되면 신경망의 표현력이 실제 자연의 많은 문제를 표현하기 어려움
- 즉, 신경망을 학습 한다는 것은 신경망을 구성하는 파라미터들인 w와 b의 값을 찾는 과정임
신경망의 학습 - 그레디언트 디센트
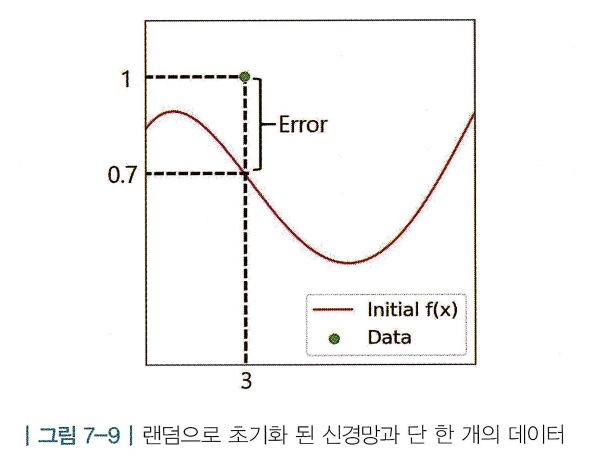
- 빨간 곡선 : 랜덤하게 초기화된
- 현재 w로는 을 만족하지 않음
- 현재 w로는 을 만족하지 않음
- 신경망의 값과 실제 값의 차이를 계산하기 위해, w에 대한 함수를 L(w)로 표현 할 수 있음
- L(w)는 신경망의 아웃풋이 주어진 데이터로부터 틀린 정도를 나타내기 때문에 손실 함수(loss function)이라고 함
- L(w)를 계산하기 위해선 w의 영향력을 알아야함
- w를 조금 증가시키거나 감소시켰을 때 함수 L(w)의 값이 어떻게 바뀌는지 확인하는 것 → 미분(derivative)
- L(w)를 w로 미분한것이 곧 w가 L(w)에 미치는 영향력임
- 신경망에는 여려 개의 w가 존재 하기 때문에 영향력을 평가하기 위해서는 L(w)를 각각의 파라미터에 대해 미분해야함 → 이를 편미분(partial derivative)이라고 함
- 그라디언트(gradient) : 를 부터 까지 각각의 파라미터에 대해 편미분하여 벡터를 만든것
- w를 그라디언트 방향으로 아주 조금씩 이동 시킴
- w를 그라디언트 방향으로 아주 조금씩 이동 시킴
- w를 얼만큼 이동시킬지는 라는 상수를 통해 정해짐
- 는 업데이트 크기를 결정하는 상수로, 러닝 레이트(learning rate) 혹은 스텝 사이즈(step size)라고 부름
- 목적 함수를 최소화하기 위해서 그라디언트에 라는 상수를 곱하여 원래 값에서 빼 줌
- 위 100개의 식을 벡터를 이용해 한 줄로 표현
-
- 그라디언트 디센트(gradient descent(경사 하강법)) : 그라디언트를 계산하여 파라미터를 업데이트하는 방식으로 목적함수를 최소화 해나가는 과정
간단한 확인
- 모델(함수) 정의
- 초기값, 데이터, 목표 설정
- 초기 파라미터:
- 데이터 한 개:
- 목표: 가 y=1에 가까워지게 만들기
- 현재 예측값 계산
- 목표와 차이가 큼
- 손실 함수 정의 (제곱오차)
- “정답”과 “예측값”의 차이를 제곱
- 여기서 이니까
- 전개하면
- 그라디언트(편미분) 구하기
- 초기값 대입
- 그래서
- 경사하강법 업데이트
- 학습률
- 업데이트 규칙
- 각 파라미터에 적용
- 업데이트 후 예측값이 좋아졌는지 확인
- 이전: -0.9
- 이후: -0.71
- 즉, 목표값인 1 방향으로(증가 방향으로) 조금 이동함.
파이토치를 이용한 신경망의 학습 구현
- 그라디언트 기반 방법론을 쓰려면 를 미분 가능한 함수로 정의해야함
- 하지만, 신경망은 매우 복잡하기 때문에 직접 미분할 수가 없음 → 컴퓨터 활용
- 하지만, 신경망은 매우 복잡하기 때문에 직접 미분할 수가 없음 → 컴퓨터 활용
- 텐서플로우(Tensorflow), 파이토치(PyTorch) 같은 다양한 자동 미분(auto diff) 라이브러리를 사용해야함
- 이 라이브러리는 역전파(back propagation) 알고리즘을 통해 아주 복잡한 함수여도 그라디언트를 효율적이고 빠르게 구함
- 파이토치 공식 홈페이지 : PyTorch Foundation
- 사전 정의
- 앞 예제에서 다룬 함수에서 노이즈를 균등 분표로 변형함
- 이 함수는 실제론 알 수 없다고 가정하며, 함수가 만들어 내는 데이터만 관찰 가능함 → 근사가 목표
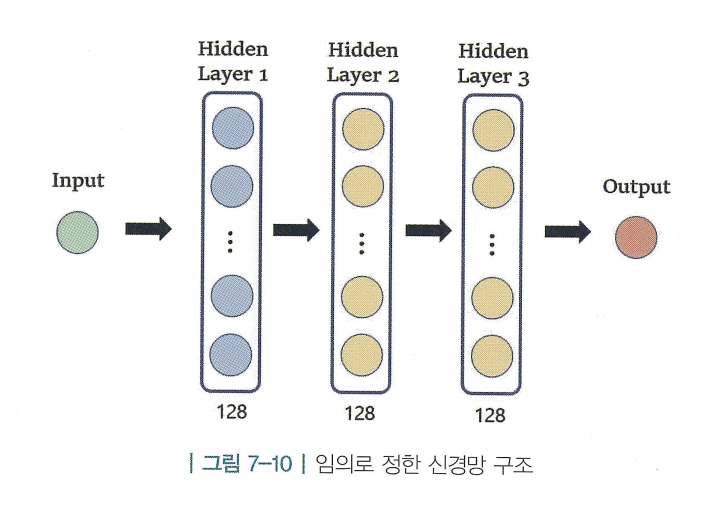
- 임의로 정한 신경망 구조 ()
- 총 3개의 히든 레이어 + 128개의 노드
- 각 레이어에 ReLU라는 활성화 함수(activation function) 사용

AI & Robotics