(한양대학교 박서연 교수님의 딥러닝 수업을 청강 하면서 정리한 내용을 바탕으로 교수님의 허락을 받고 작성하였습니다.)
Evaluation Metric
Evaluation_Metric Code - GitHub
+ 오늘의 연구 코멘트
Evaluation Metric
- perplexity(혼잡도) : text generation에서 next word를 prediction할 때, 몇 개의 word 사이에서 헷갈리는지 → 자주 쓰임
- BLEU,ROGUE는 특정 task에서만 쓰임
- BLEU : 내가 번역한 문장 안에, 정답 번역에 있는 “짧은 구(단어 묶음)”가 얼마나 많이/정확히 겹치는지
- ROUGE : 내가 쓴 요약·문장 안에, 정답 요약에 있는 중요 단어/구를 얼마나 빠짐없이 담았는지
- 최근엔 BLEU,ROGUE을 안쓰고 exact match score를 사용함

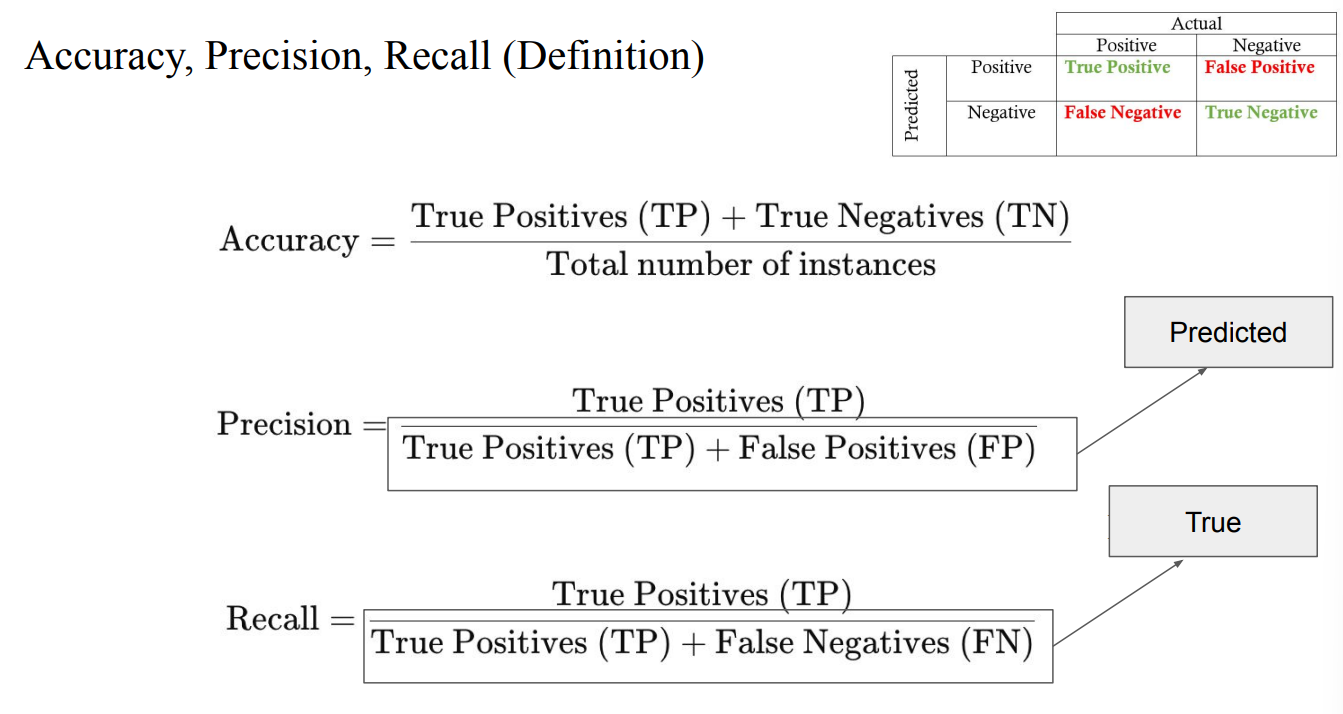
- Recall : 실제 정답 중에 몇개 맞췄는지 (실제 정답 중에서 맞춘 비율)
- Precision : 모델이 Prediction한 것 중에 몇개가 정답인지 (예측한 것들 중에서 진짜인 비율)
- 굳이 외울 필요 없음 → 의미가 중요
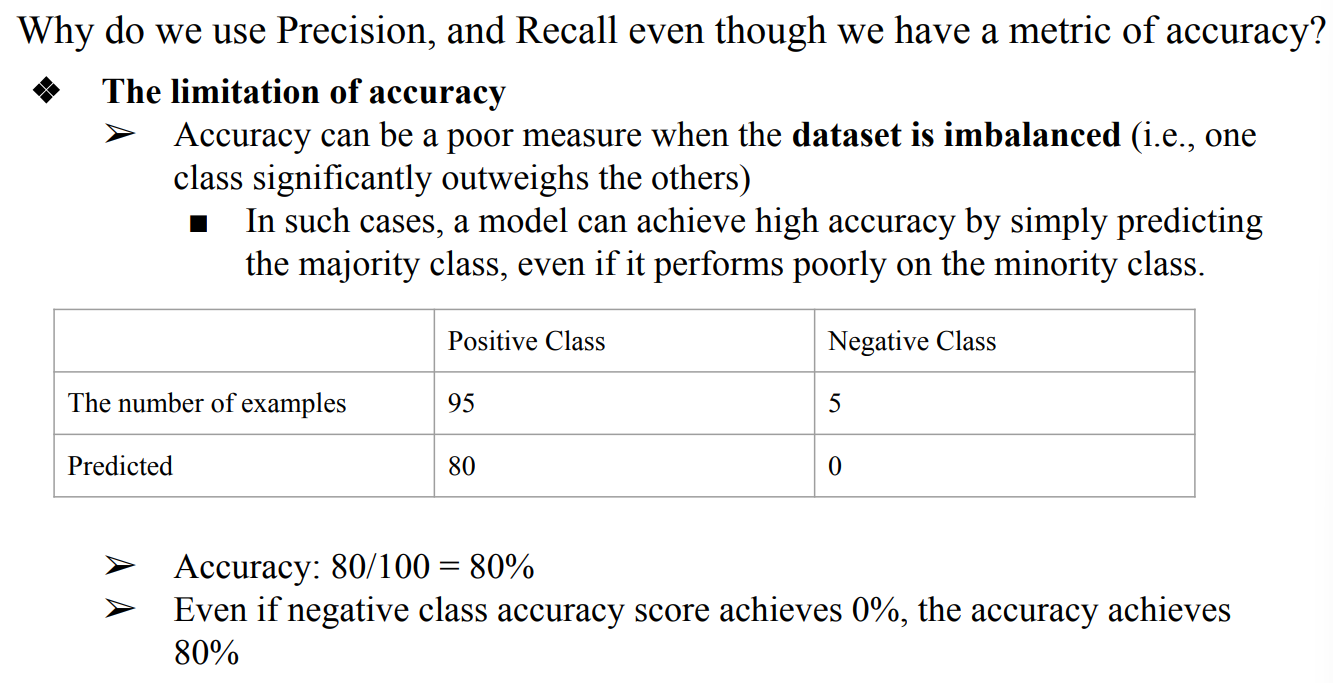
- dataset이 balance되어서 public하게 공개된 것이 아니라면 Accuracy와 Recall, Precision을 모두 봐야함
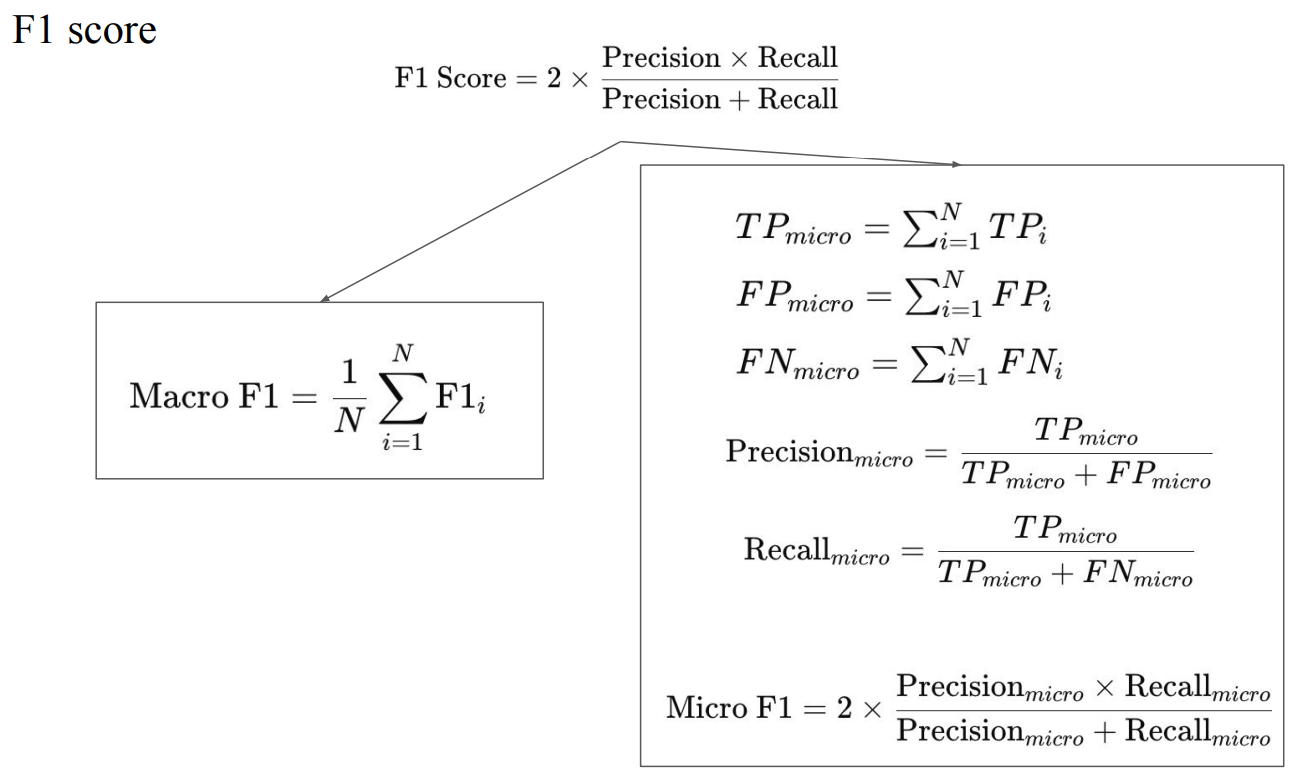
- 제일 대표적으로 Macro F1을 사용함
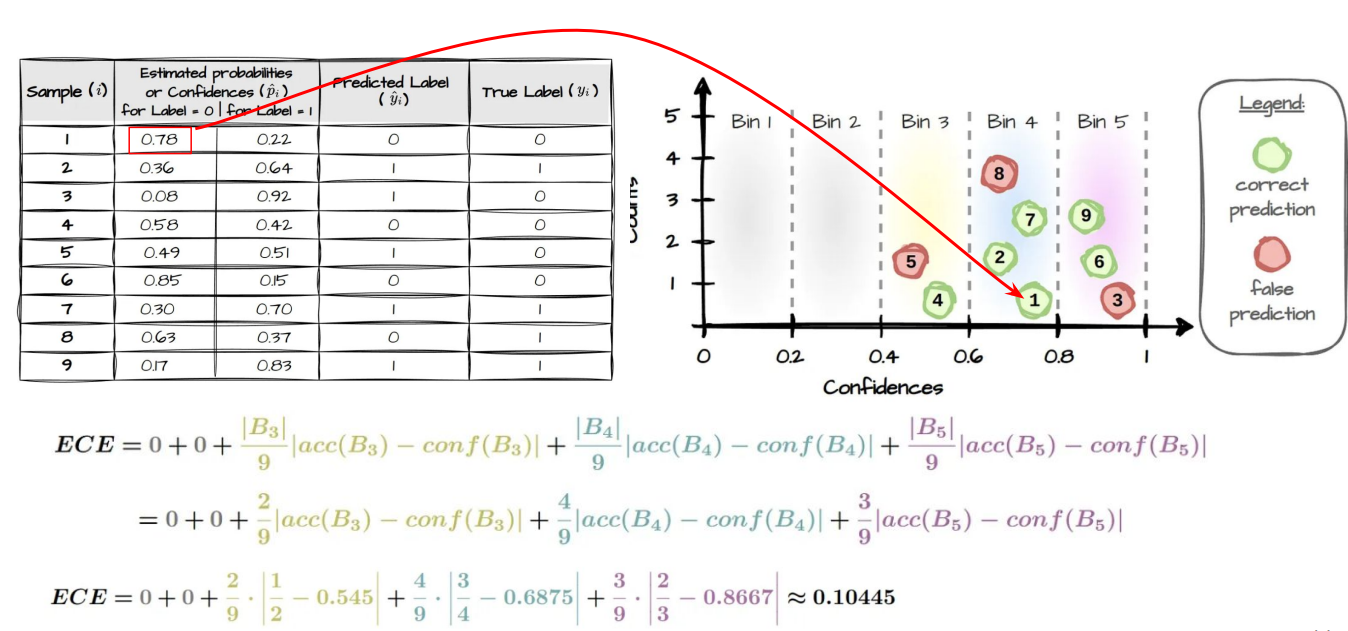
- model이 prediction한 confidence랑, 실제로 맞은 비율이 얼마나 차이 나는지를 측정하는 Evaluation Metric
- Calibration Error을 수치화 한것이 Expected Calibration Error임
- model이 prediction을 과신하기 때문에 생김
- 즉, model이 prediction한 확률(confidence)과 실제 정답 비율(accuracy) 사이의 간극을 측정하는 것

ECE Example
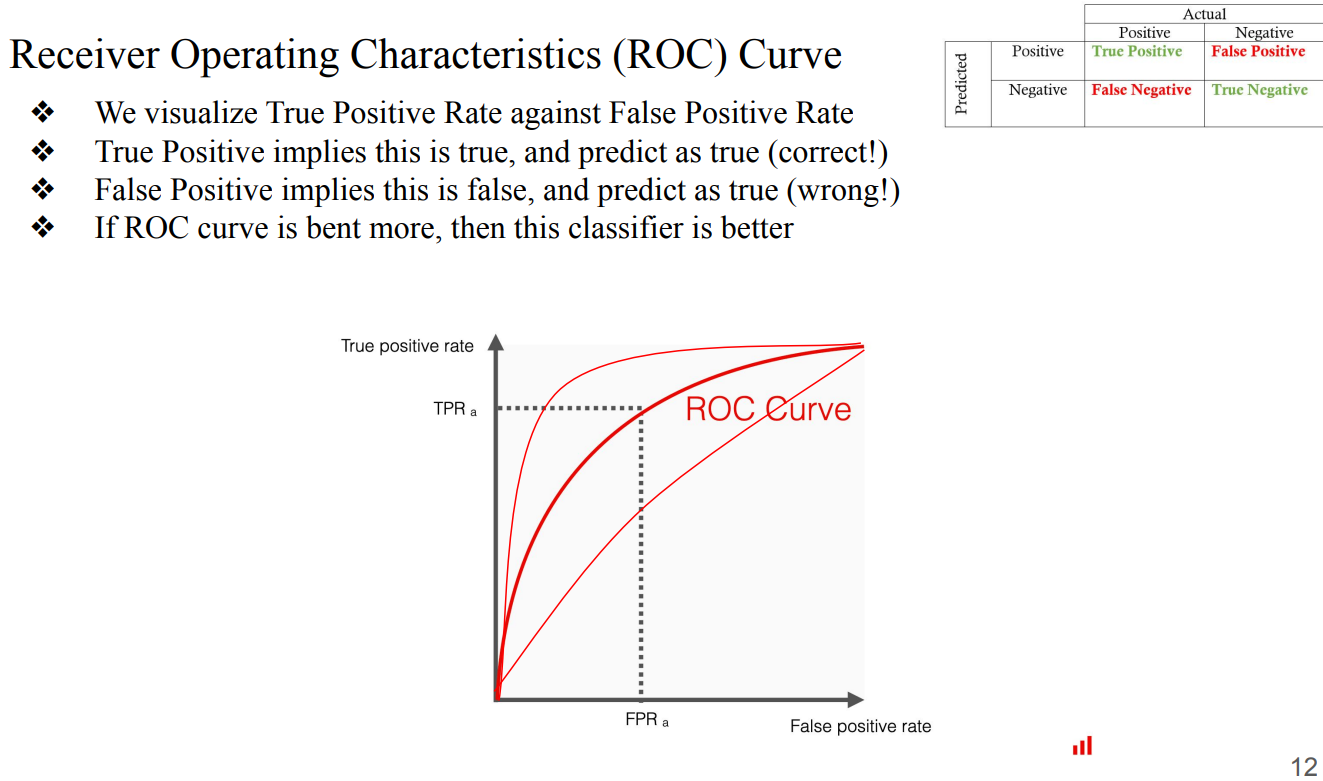
- ROC Curve가 y축에 가까울수록 (혹은 ROC Curve의 아래쪽 넓이가 클수록) 좋은 모델임
Text Generation Evaluation Metric : Perplexity
- Sentence의 Perplexity를 구하는것
- output prediction값을 통해서 문장을 구성 → chain-rule
- 어떤 language probability을 구할 때, model이 Produce한 모든 probability를 모두 곱해서 계산함
- 최종 결과값인 Perplexity값을 통해 model이 몇개의 단어 사이에서 혼동이 왔는지를 알 수 있음

Text Generation Evaluation Metric : BLEU, ROGUE
- machine translation task에서 제일 많이 쓰임
- reference : 정답
- hypothesis : model의 prediction값
- 단어들을 보고, hypothesis와 reference을 비교해서 매칭되는 것들을 찾는다
BLEU (Precision based scoring)
- Precision based로 hypothesis(prediction)를 기준으로(분모로) 계산함
- prediction문장이 짧은 경우 penalty을 추가함
ROGUE (Recall based scoring)
- Recall based로 reference(True)를 기준으로(분모로) 계산함
- ROUGE-F1 score : Precision과 Recall을 구한뒤 조화평균을 계산하는것
- ROGUE는 Recall based인데 이경우 결국 Precision도 계산하는 것이라 ROGUE의 의미가 줄어듬


Text Generation analysis Technique : T-SNE Visualization
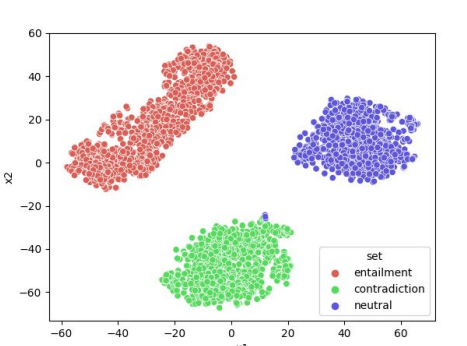
- BERT 기반으로, word vector(768 dimension)을 2d space로 축소해서 각 단어/문장을 점으로 표현해 visualization하는 방법
- 의미가 비슷한 단어·문장이 실제로 가까이 모이는지, generated text의 분포가 reference와 얼마나 비슷한지 확인 할 수 있음
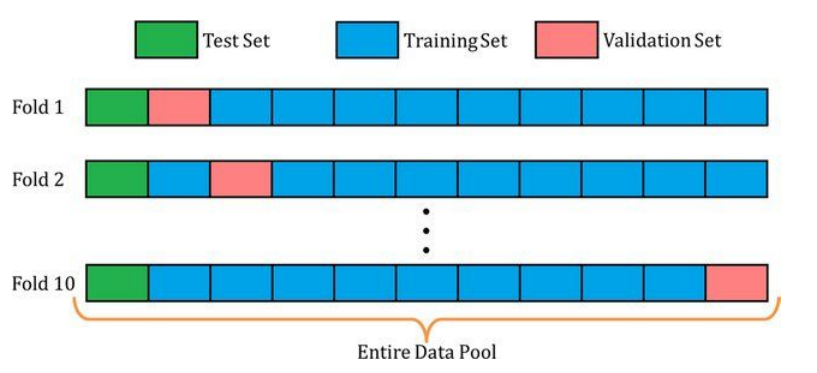
Overfitting/Underfitting : K-fold Cross-validation
- 이론적으로는 K-fold cross-validation을 쓸 수도 있지만, 요즘은 benchmark dataset이 미리 정해진 train/validation/test split을 같이 공개해두기 때문에, 제공된 split에 맞춰 training하고 Evaluation을 진행하는 것이 일반적임 → custom dataset이 아닐 경우 쓸일이 없음

AI & Robotics