(한양대학교 박서연 교수님의 딥러닝 수업을 청강 하면서 정리한 내용을 바탕으로 교수님의 허락을 받고 작성하였습니다.)
Normalization, Optimization
Normalization & Optimization Code - GitHub
+ 오늘의 연구 코멘트
GitHub - ndb796/Deep-Learning-Paper-Review-and-Practice: 꼼꼼한 딥러닝 논문 리뷰와 코드 실습
- paper는 Introduction이 제일 중요함
- Introduction : 개념들 정의, 저자들의 관심있어하는 기술들 소개, 이전의 연구들에 대한 한계점 및 저자들의 해결 방안
- 즉, 논리적인 흐름이 중요함
- 논문 읽을때나 무언가를 공부할때는 항상 how(어떻게 했는가)을 공부한 뒤에 why(왜 그렇게 했는가)를 공부하는 것이 좋음
- zero-centered가 아닌 문제 해결하는 방법
- zero-centered한 activation function 사용
- input이 항상 positive하지 않게 해주면 됨 → Batch Normalization
- Normalization : 베타와 감마를 통해 Flexibility하게 만드는 것

Batch Normalization
- Batch Normalization
- input vector가 zero mean이고 unit variance을 가지도록 range를 조정하는 방법
- test Phase때는 train data에서 기록되어진 mean과 variance를 가지고 test input을 Normalization함 (test data 자체를 가지고 Normalization 하는 것이 아님)

Layer Normalization
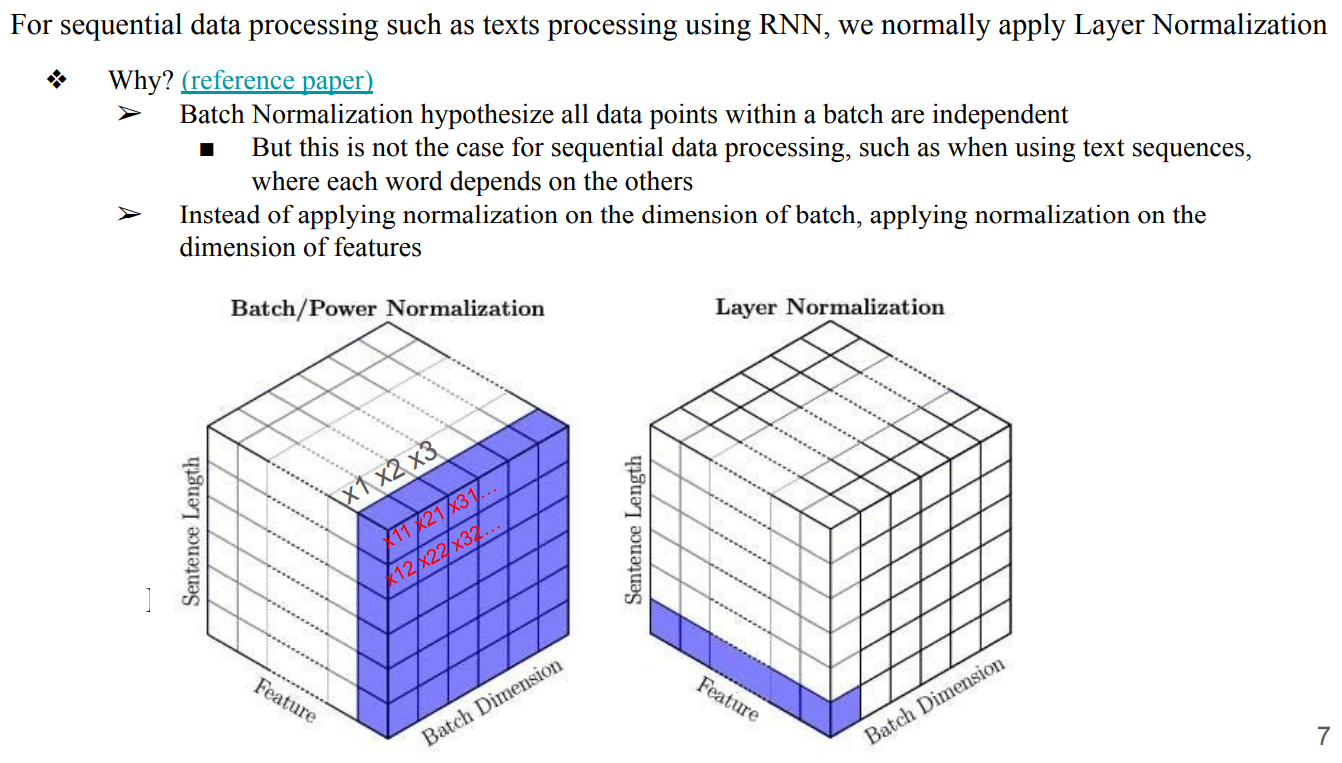
- sequential data processing(texts processing)할 때는 Batch Normalization이 아니라 Layer Normalization을 진행해야함
- Batch Normalization은 data의 sample이 0을 평균으로 가지고, variance가 1을 가지는 distribution에서 뽑아졌다고 가정함. 즉, sample들이 independent하다고 가정하는 것)
- texts processing에서는 문장안에 각 word가 서로 매우 dependent하기 때문에 사용할 수 없음
- Layer Normalization : feature dimension을 따라서 Normalization을 진행하는 방법
- Batch Normalization은 Batch dimension을 따라 진행해서 각 vector들의 dependent한 feature을 무시하게 되지만, Layer Normalization은 feature dimension을 따라 Normalization을 진행하기 때문에 의미 정보가 소실되지 않음
Optimization : Stochastic Gradient Descent
- 기본적인 Gradient Descent 방법은 모든 data sample을 보고 각각의 step별로 Gradient를 다 계산한 후, 그 Gradient들을 가지고 한번에 update를 하는것
- Stochastic Gradient Descent는 모든 Gradient를 다보고 한번에 update를 하는 것이 아니라, Gradient가 계산될 때마다 update을 하는 방법
- problem 1 : 모든 Gradient를 보고 update를 하는 것이 아니기 때문에(batch processing 하기 때문에) Gradient Noise가 누적되어, 학습이 제대로 되지 않을 수도 있음
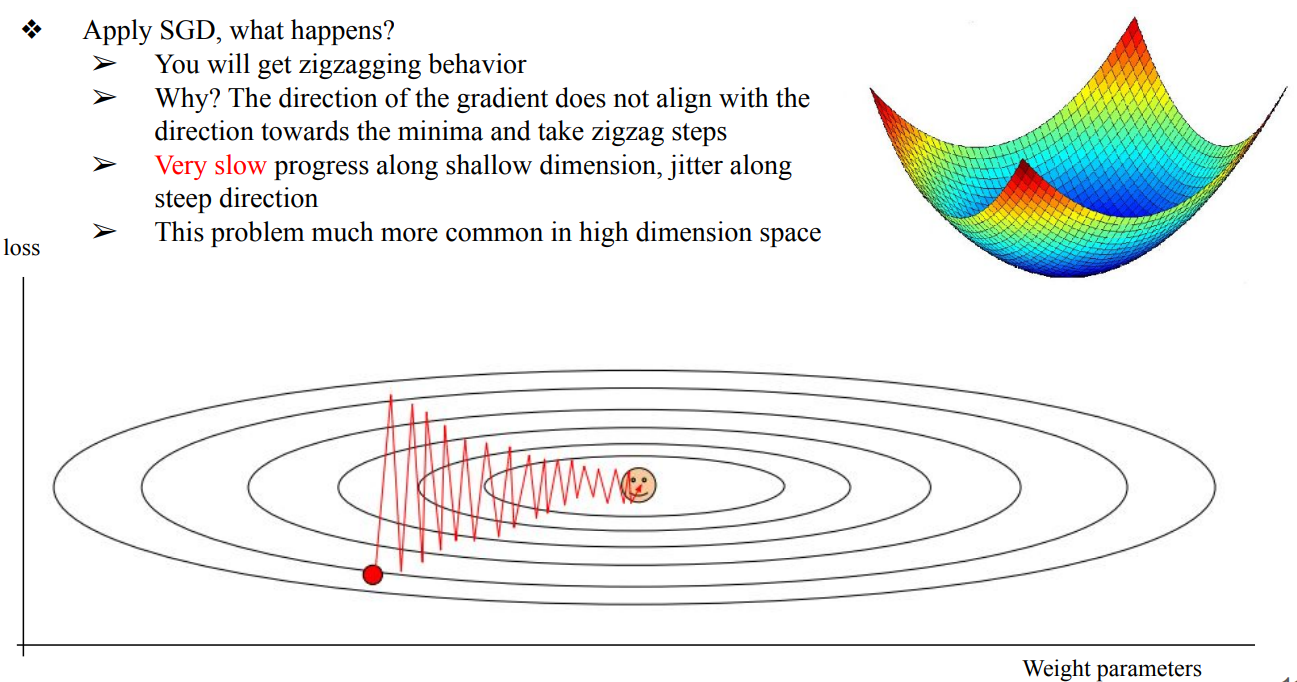
- problem 2 : Poor Conditioning
- weight가 어떻게 변하는지에 따라서 Gradient가 너무 많이 변함 → Gradient가 예민하기 때문에 zigzagging behavior이 발생하여 매애애애애우 느려지는 현상이 발생함
- problem 3 : Local Minima, Saddle Points
- 결국 Gradient를 통해 update하는것 이기 때문에, gradient=0인 지점이 여러 개 존재할 경우, local minima나 saddle point에 수렴할 수 있음

Optimization: SGD + Momentum
- zigzagging behavior와 Local Minima의 문제를 해결하기 위해서 Momentum이라는 velocity를 추가해서 빠져나올 수 있도록함 → 즉, Gradient에 memory가 생기는 것
- problem 1 → velocity 덕분에 gradient estimate에 섞인 noise가 평균화가 되어 해결됨
- problem 2 → velocity가 step을 가속시켜 줘서, gradient 방향이 자꾸 바뀌며 생기는 zigzagging behavior를 줄임
- problem 3 → gradient가 0이어서 local minima나 saddle points에 갇혀 있어도, 이제는 velocity가 있어 그 지점을 빠져 나올 수 있음

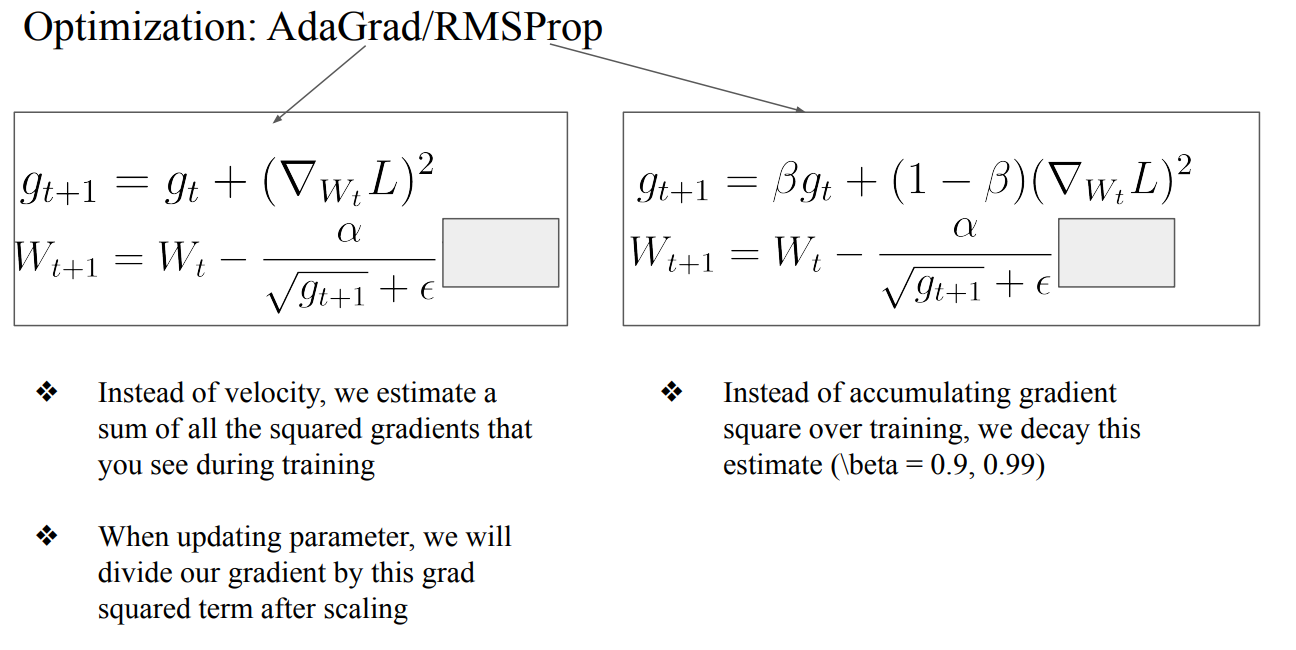
- AdaGrad : Momentum은 velocity을 update할 때 gradient하나만 가지고 진행했다면, squared gradients로 velocity를 update하는 방법
- RMSProp : AdaGrad방법론에서 얼만큼 update할건지 베타를 사용하여 정하는 방법
- Adam : Momentum에서 계산하는 방식과 AdaGrad에서 계산하는 방식에서의 benefit들을 가지고와서 합친 방법
- AdamW : Adam에서 Weight Decay을 추가한 방법

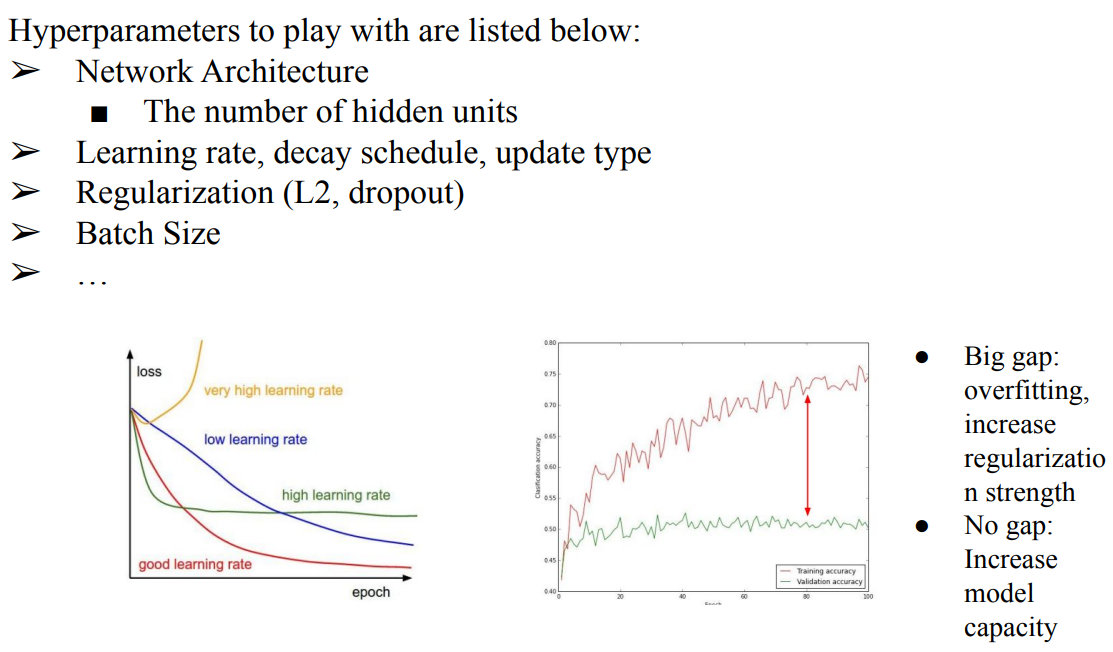
- Monitoring a Learning Procedure
- train loss을 확인하고 learning rate조절 (국룰 learning rate : 1e-3, 1e-5)
- eval accuracy을 확인하고 갑자기 좋아진 순간 Early Stopping하는 것도 좋음
- Hyperparameter Optimization
- loss을 확인하기
- 다른 reference 참고 하기
- 핵심은 많이 학습해서 많이 확인하기 (노가다)
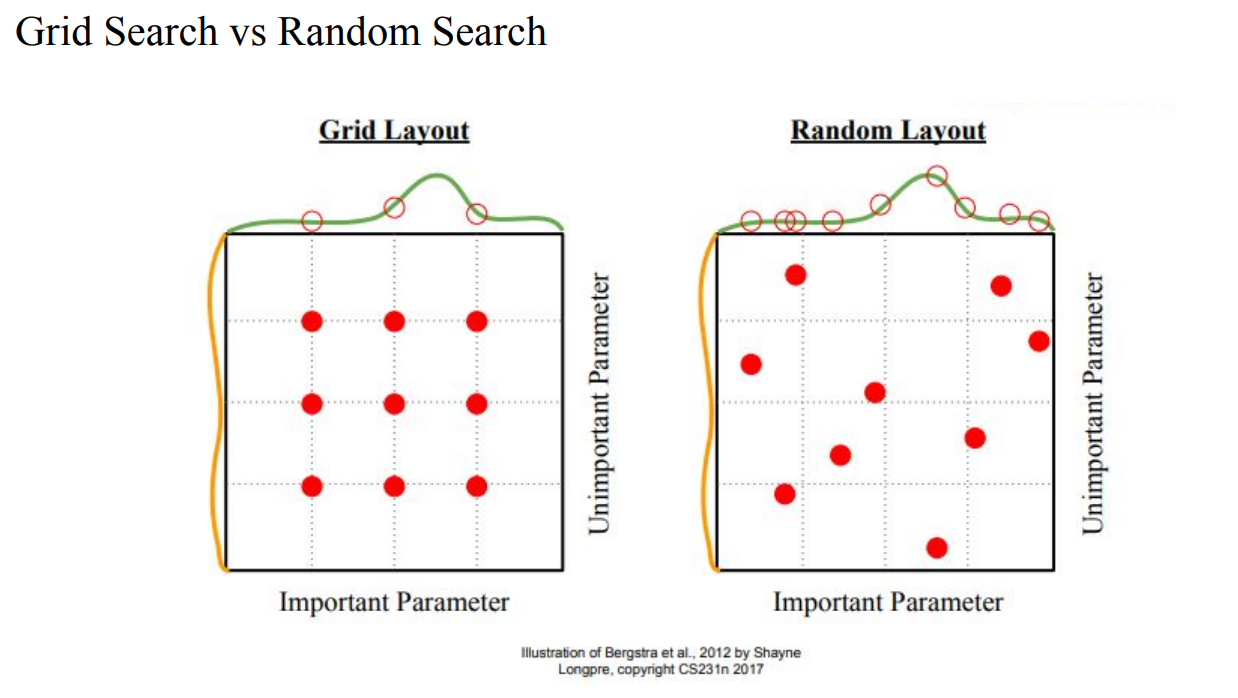
- Learning rate을 크게 바꿔봐야 Learning rate문제인지 code문제인지 알 수 있음
- underfitting이 된경우 : Network의 Complexity을 높이는 쪽으로 접근할 수도 있음
- 제일 중요한것은 data가 얼마나 많은지, 질이 좋은지 확인하는것

AI & Robotics