(한양대학교 박서연 교수님의 딥러닝 수업을 청강 하면서 정리한 내용을 바탕으로 교수님의 허락을 받고 작성하였습니다.)
Text Generation
MachineTranslation Code - GitHub
+ 오늘의 연구 코멘트
- Emergent Introspective Awareness in Large Language Models
- language model이 무엇을 알고있는지를 확인하는 paper
- 그냥 훈련 데이터에서 배운 연기인지, 아니면 진짜 자기 내부 상태를 읽어서 말하는지
- Multi-Agent Evolve: LLM Self-Improve through Co-evolution
- 어떻게 하면 LLM이 더 잘 지식을 받아드릴 수 있을까에 대한 paper
- RA-DIT: Retrieval-Augmented Dual Instruction Tuning
- instruction tuning에 대한 paper
- Scaling Instruction-Finetuned Language Models
- instruction tuning의 시작인 paper
How can we implement a neural language model training framework?
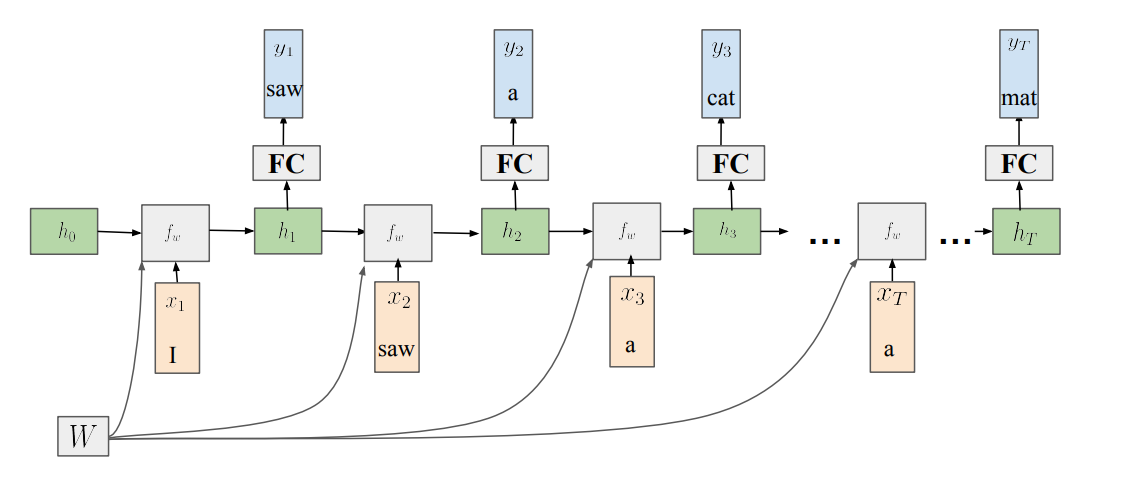
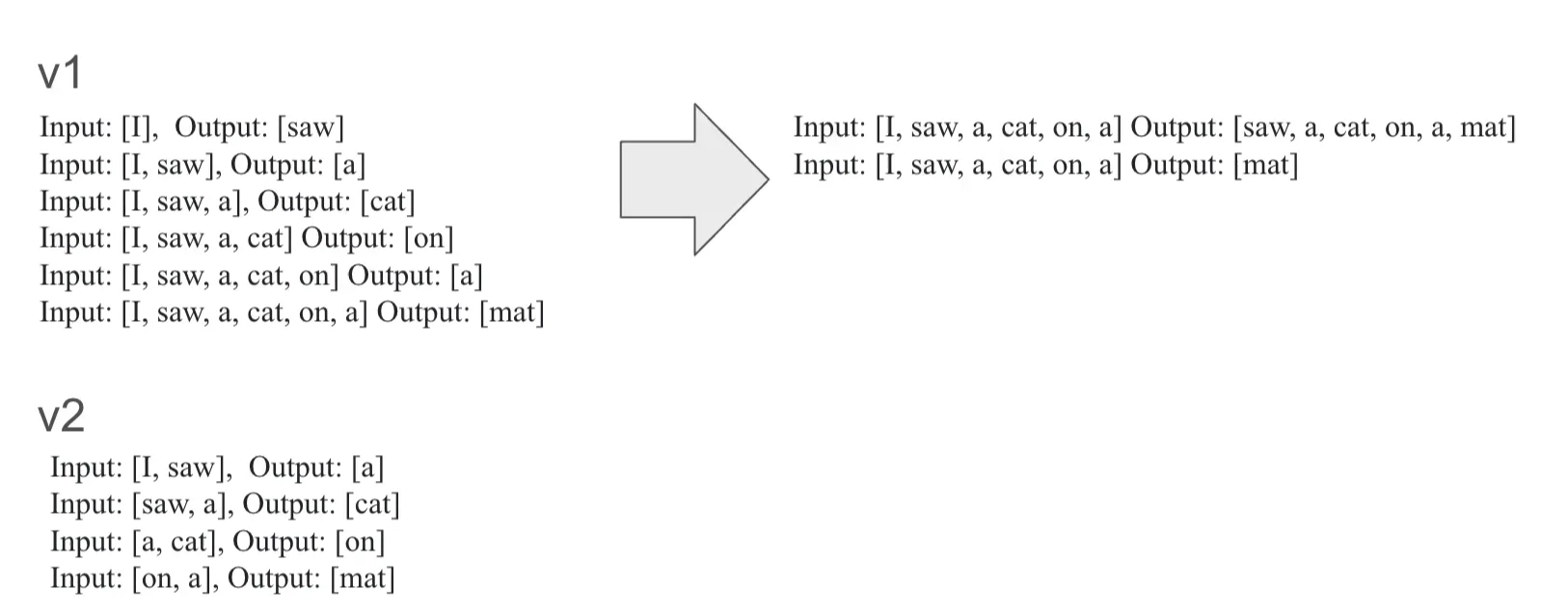
- data construction을 진행할 때 주의해야함 (many-to-one)
- pytorch의 경우 내부에서 이미 구현되어있음 → vector의 크기를 맞춰줘야함

ex) RNN
- embedding weight matrix를 무조건 구성해야함 → hidden layer의 input으로 들어가서 n-step hidden state로 나옴
- 이후, Fully connected layer로 들어가 vocab distribution만큼 출력
- 이후, Ture와 값이 비슷하게 되게끔 Loss를 계산한 뒤, Backpropagation진행 → 이 과정 반복
- data construction을 이렇게 진행하는 이유는 sequential processing 하기위함
- 사실 Many-to-Many로 줘도 내부적으로 알아서 처리함
- 하지만 many-to-one이 좀 더 효율적임
- training을 구성했으면 testing도 구성해야함
- decoding을 어떻게 할건지에 대한건 매우 많은 알고리즘들이 있음 (ex - greedy decoding)

Text Generation (e.g., Machine Translation)
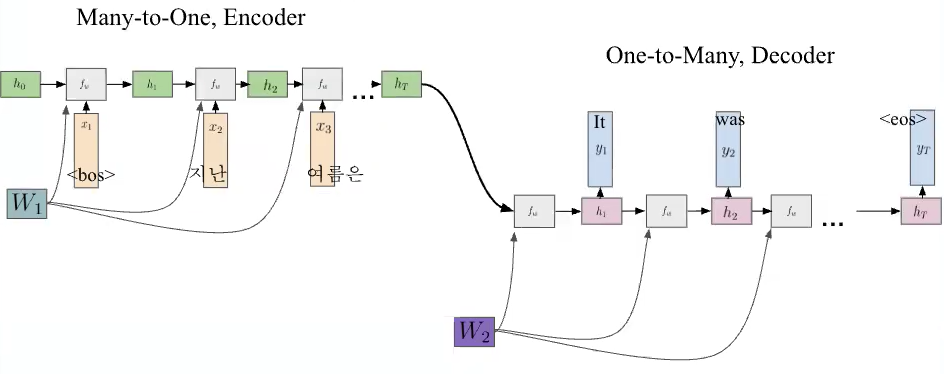
- Machine Translation에서 궁극적인 목표는 sequence x가 주어졌을때 target sequence y를 생성하는 probability를 최대화 하는 것 → Increase the conditional probability

- Seq2Seq Model for Text Generation (e.g., Machine Translation) 구조
- special token은 필수로 들어가야함 → 문장의 시작과 끝을 명확하게 하기 위함

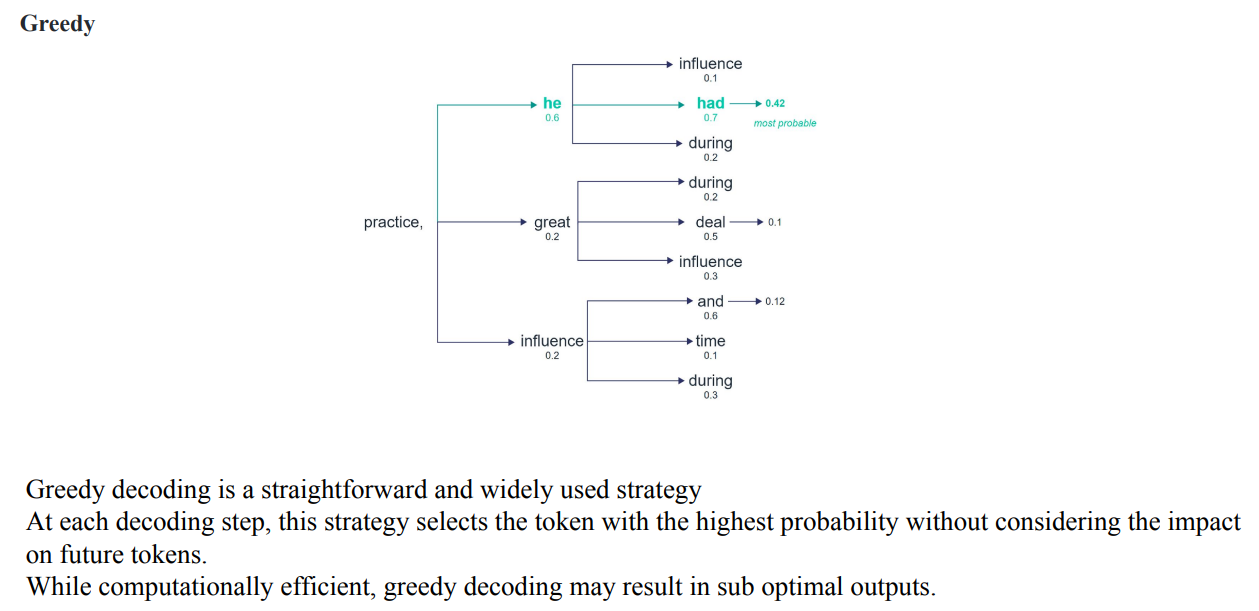
Greedy decoding
- Greedy decoding은 굉장히 단순하고 빠르지만, 항상 optimal한 output이 나오지는 않음
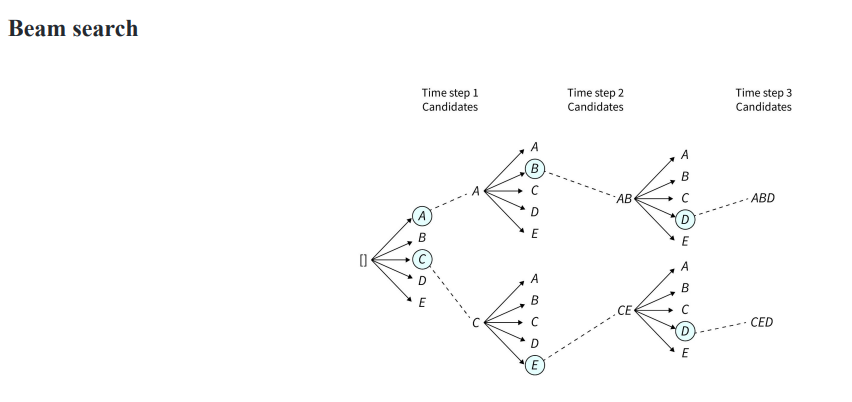
Beam search
- top-k의 후보를 두고 계속적으로 확장해나가는 방법 (greedy의 확장판)
- 각 후보는 현재 token과 이전 token들의 누적 probability를 기반으로 결정됨
Top-k Sampling
- top-k개의 후보를 선택하여 probability Normaliztion를 진행함 → 정규화된 probability를 기반으로 sampling 함 (greedy가 아니기 때문에 무조건 높은값을 선택하지 않음)

Top-p Sampling
- 누적 probability가 p 이상이 될 때까지 상위 후보들을 모아 동적으로 후보 집합을 만든 뒤, 그 안에서 probability를 정규화해서 sampling함 (그래서 top-k처럼 후보 개수가 고정돼 있지 않음)

- 요즘엔 Top-k와 Top-p를 섞어서 같이 쓰기도함

summary


AI & Robotics