(한양대학교 박서연 교수님의 딥러닝 수업을 청강 하면서 정리한 내용을 바탕으로 교수님의 허락을 받고 작성하였습니다.)
Attention, Transformer
transformer Code - GitHub
+ 오늘의 연구 코멘트
- NeurIPS Poster Nested Learning: The Illusion of Deep Learning Architectures
- Introducing Nested Learning: A new ML paradigm for continual learning
- catastrophic forgetting issue를 해결하기 위한 continual learning을 재정의한 paper
- 비슷한 keyword : unknown learning
- Neural Machine Translation by Jointly Learning to Align and Translate
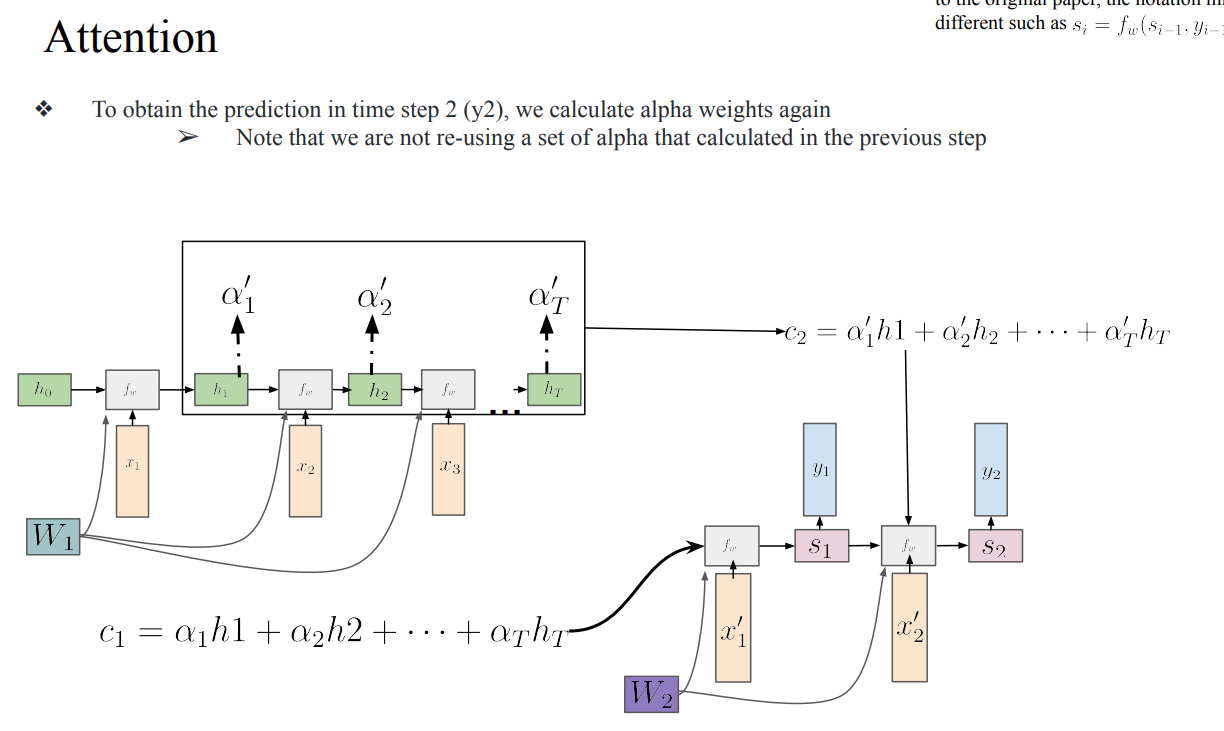
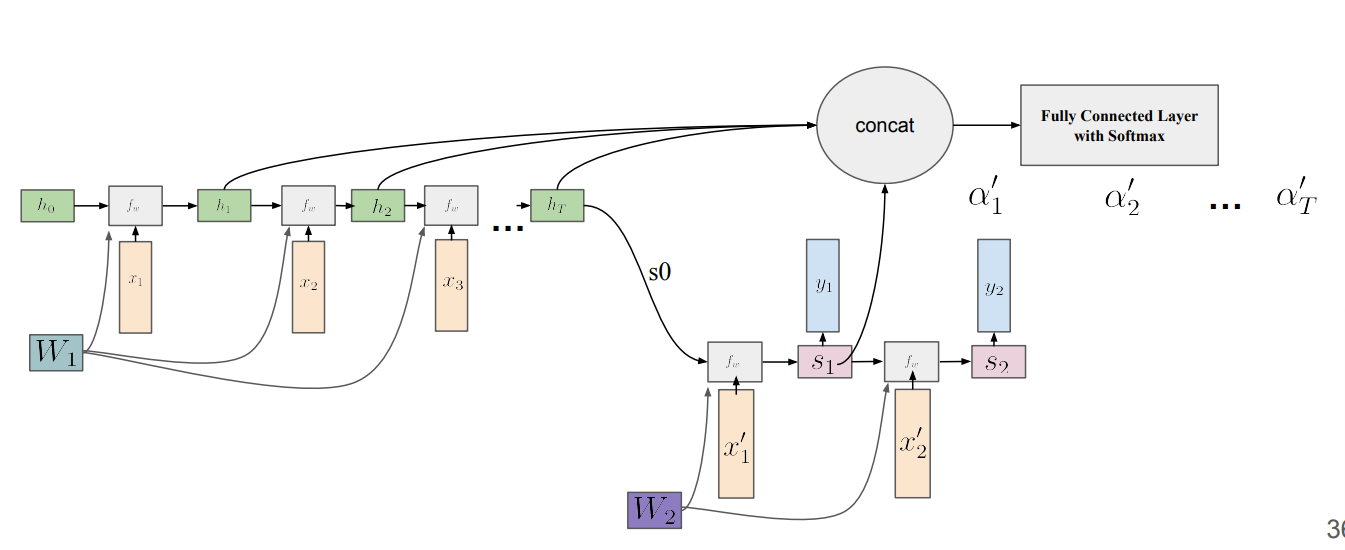
- 기존에 Seq2Seq model은 Encoder step별로 계산하고, 하나의 lest hidden state가 output으로 나오게 되는데, 각각의 hidden state를 모두 사용할 수 없을까를 고안하기위해 Attention이라는 이론이 등장함
- 모든 time-step의 hidden state를 보기때문에 context를 좀 더 정교하게 볼 수 있다 → context vector라고 함
- context vector가 decoder의 input으로 추가됨
- 이렇게 한 step의 decoder의 hidden state을 업데이트함
- 이때, 알파가 decoder의 time-step마다 새롭게 다시 계산하는 것이 핵심
- weight matrix를 Random Initialization하고, 모든 time-step의 hidden state를 붙인것을 dot-product로 계산함 → 이후 softmax를 적용해서 각 time-step에 대한 attention weight T개를 만듬
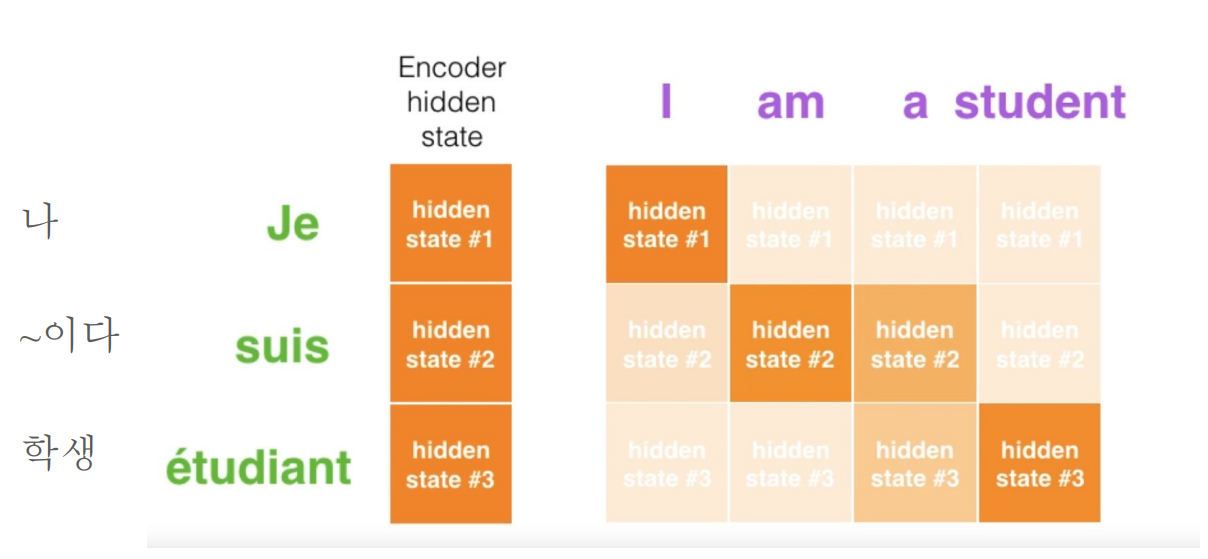
왜 Attention이 좋은가
- model이 어디에 집중(Attention)해야하는지 스스로 배움 → network가 ‘context’를 배워간다
- RNN 계열 Seq2Seq에 attention을 붙이면 성능은 좋아지지만, 여전히 sequential processing에 의존하기 때문에 parallelization과 efficiency에 한계가 있음
- 하지만, self-attention은 한 문장 안의 각 토큰이 자기와 같은 문장에 있는 모든 토큰을 attention으로 볼수 있기 때문에 모든 token이 스스로 source이자 target이 되어 각자 안에서 네트워크가 스스로 배울 수 있음

- Attention Is All You Need
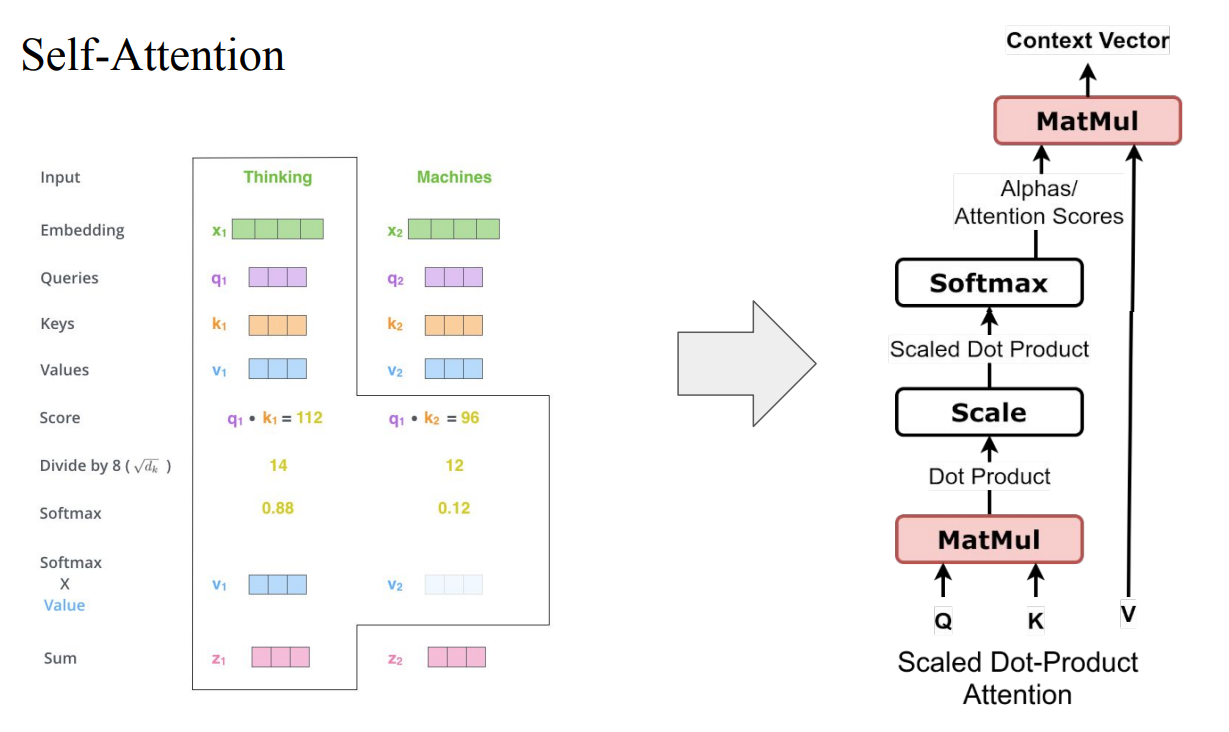
- Self-Attention의 핵심은 Query, Key, Value임
1. 각 word에 대한 embedding vector를 생성함
2. Query, Key, Value를 각각 담당하는 weight matrix를 생성함 (처음엔 Random Initialization)
→ , ,
3. 각 word embedding vector와 , , 를 곱해서 각 word에 해당하는 Query, Key, Value의 vector를 구함
- 각 Query vector마다 문장 안의 모든 Key vector와 dot-product를 해서 score들을 계산함
- 각 score들을 Key dimension의 제곱근(√d_k)으로 나눔 (실험적으로 이렇게 나누는 것이 학습이 가장 안정적이고 잘 됨)
- scale된 score에 softmax를 씌워서 T개의 probability distribution(= attention weight)를 계산함
- 이 weight들을 각 Value vector에 곱해서, 그 Query에 대한 final output vector를 구함
- 모든 time-step 대해 위 과정을 수행하고, 이들을 모아서 self-attention layer의 출력 sequence로 사용됨

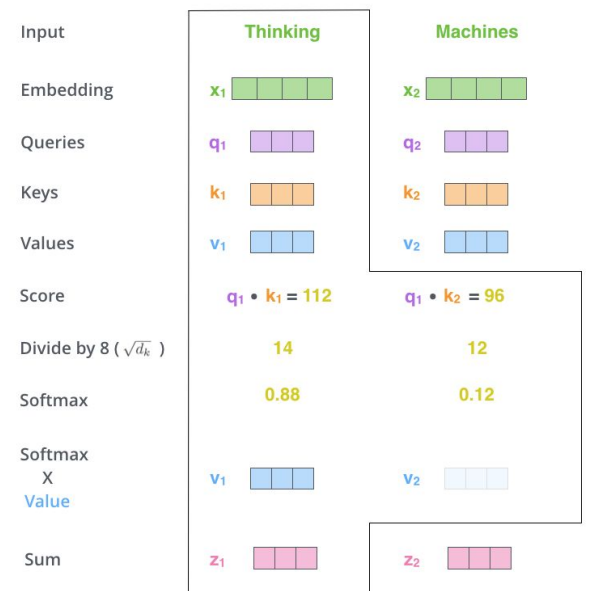
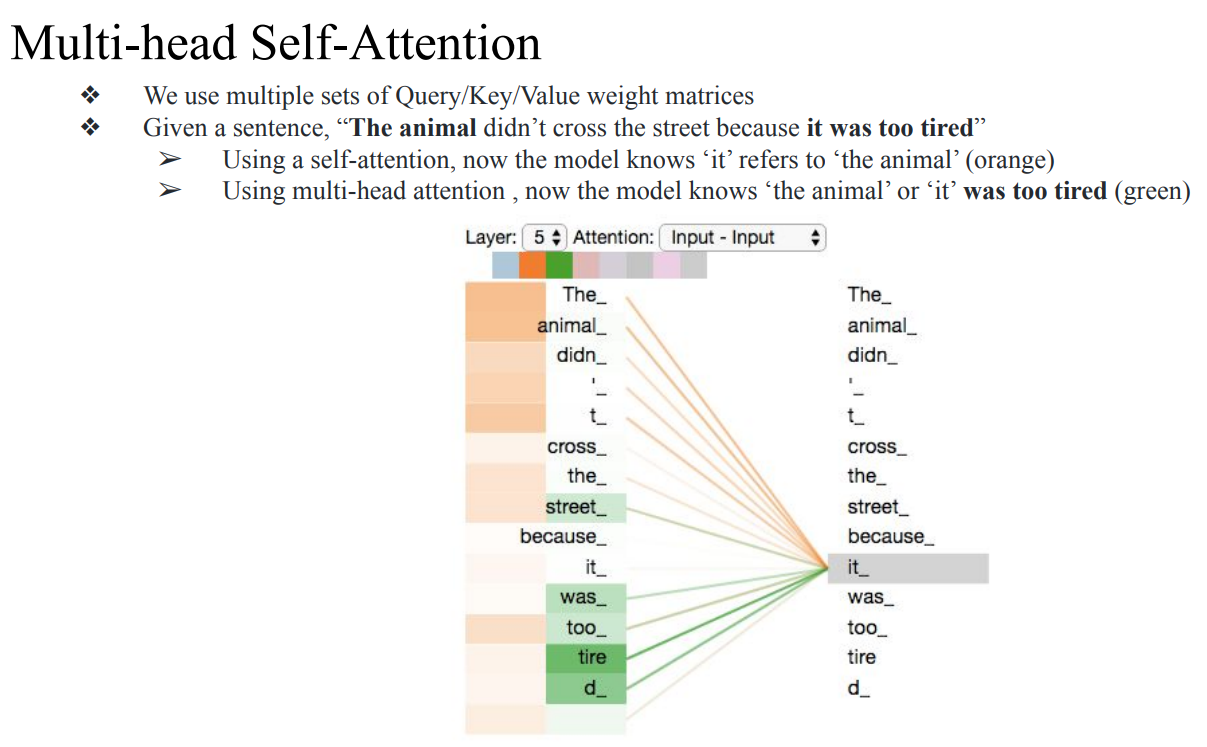
- Self-Attention의 과정은 parallel하게 한번에 진행됨
- Multi-head Self-Attention은 Q/K/V weight matrix 세트를 여러 개 두고, 여러 개의 self-attention을 병렬로 돌리는 구조임
- 각 head는 문장 안에서 서로 다른 관계에 집중해서 여러 “관점”을 동시에 보게 해서 더 풍부한 문맥 표현과 성능 향상을 얻는 것이 목적
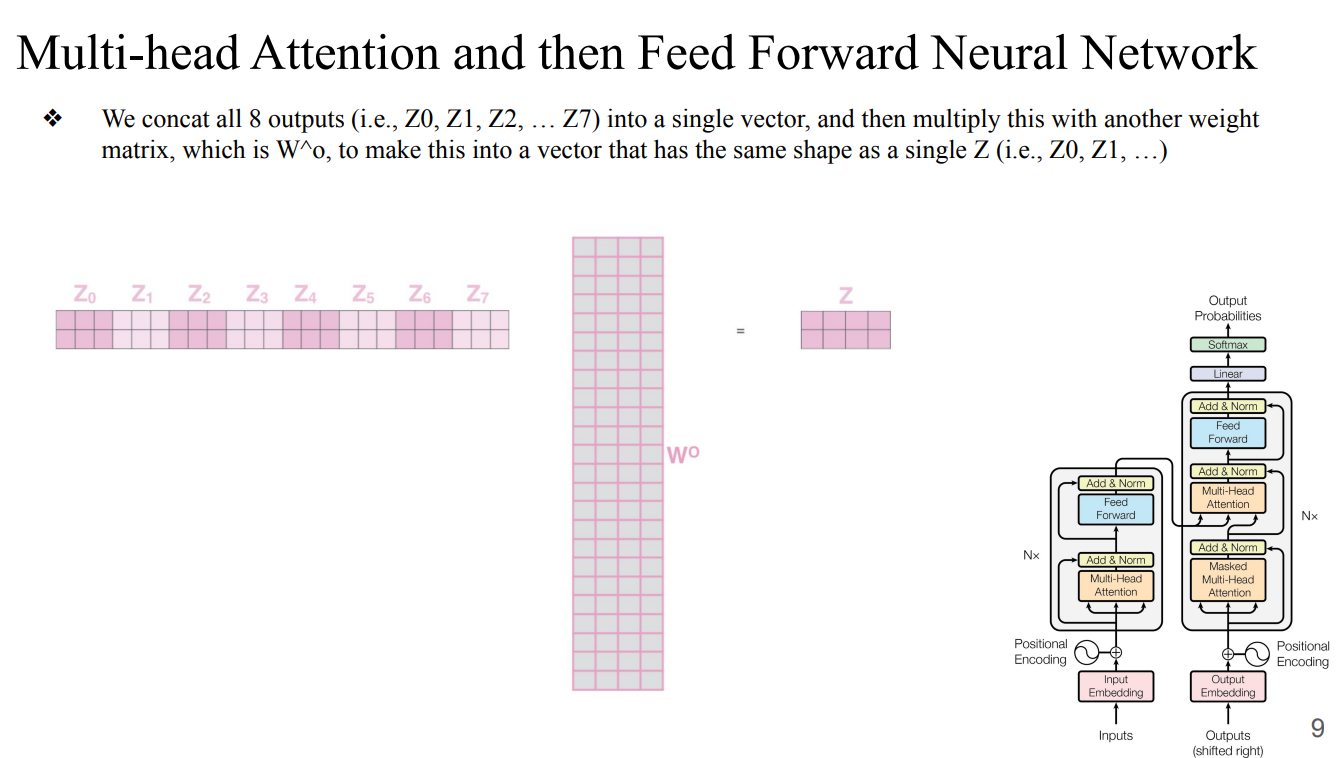
- sequential processing을 하지않고 한번에 계산해서 한번에 사용함 → 굉장히 빠름
- 하지만 순서에 대한 정보를 잃어버림 → 이를 해결하기 위해 Positional Encoding을 추가함
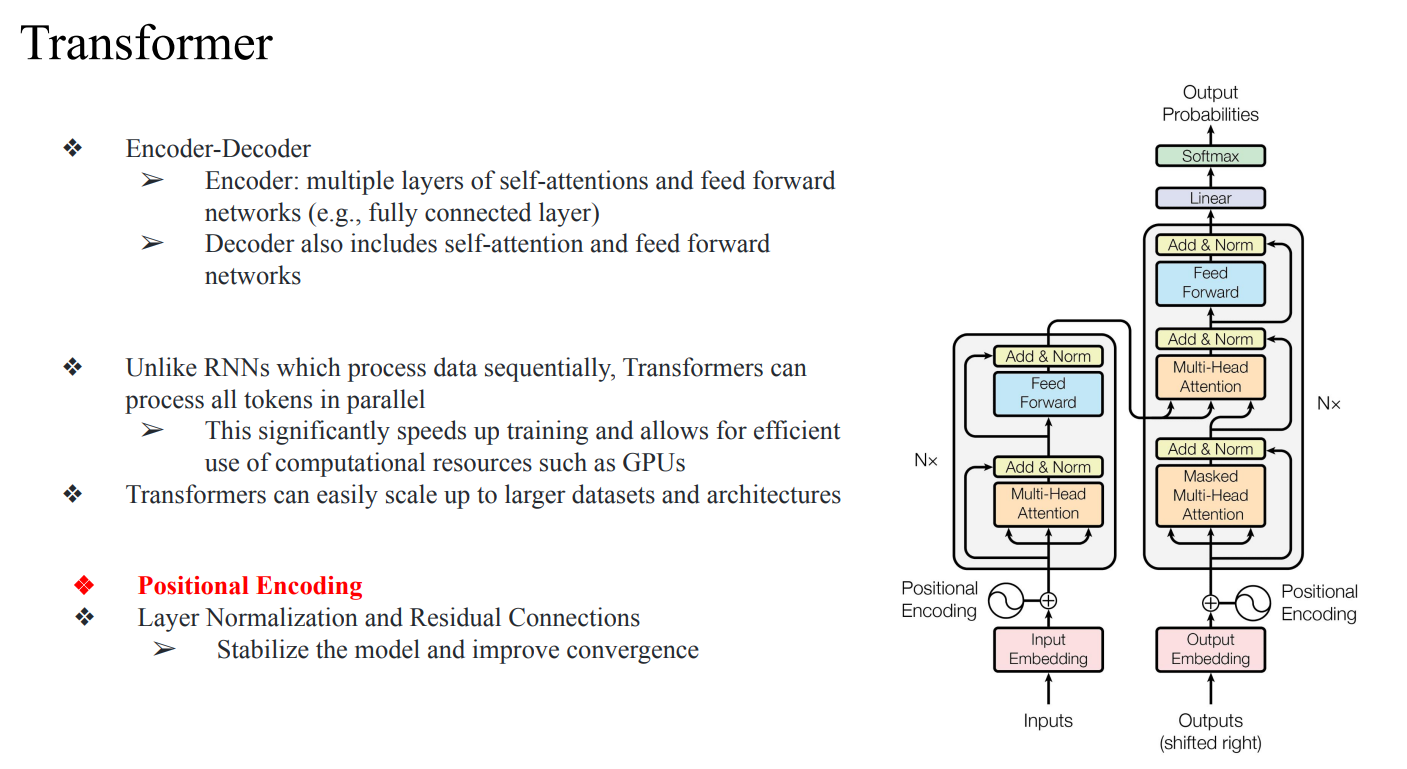
transformer encoder architecture
- Self-Attention은 기본적으로 Parallel Processing이기 때문에
현재 token이 미래의 token을 보는 것을 방지하기 위해 오른쪽에 있는 토큰들에 대한 score를 mask해서 softmax 이후 probability가 0이 되도록 만들고, attention을 진행함

Add & Norm
- Multi-Head Attention의 input으로 들어갔던 시점의 각 word에 대한 embedding vector를 Multi-Head Attention의 Output에 더 해줌
- 그렇기 때문에 Multi-head Attention의 output의 weight matrix를 곱해 dimension을 맞춰줌
- 왜 더하는가?
- embedding vector을 그대로 더해 gradient가 shortcut 경로로 흘러 vanishing gradient 문제를 완화함
- attention에서 많이 변형되더라도 원래 input이 더해져 있기 때문에 정보 소실을 줄이고 원래 token 정보가 보존됨
- 하지만, 단순히 더하는 경우 model이 너무 많은 Feature Space를 handling해야해서 오히려 normalization이 안될 수도 있음 → layer normalization을 적용함
- 그래서 Add & Norm라고 함

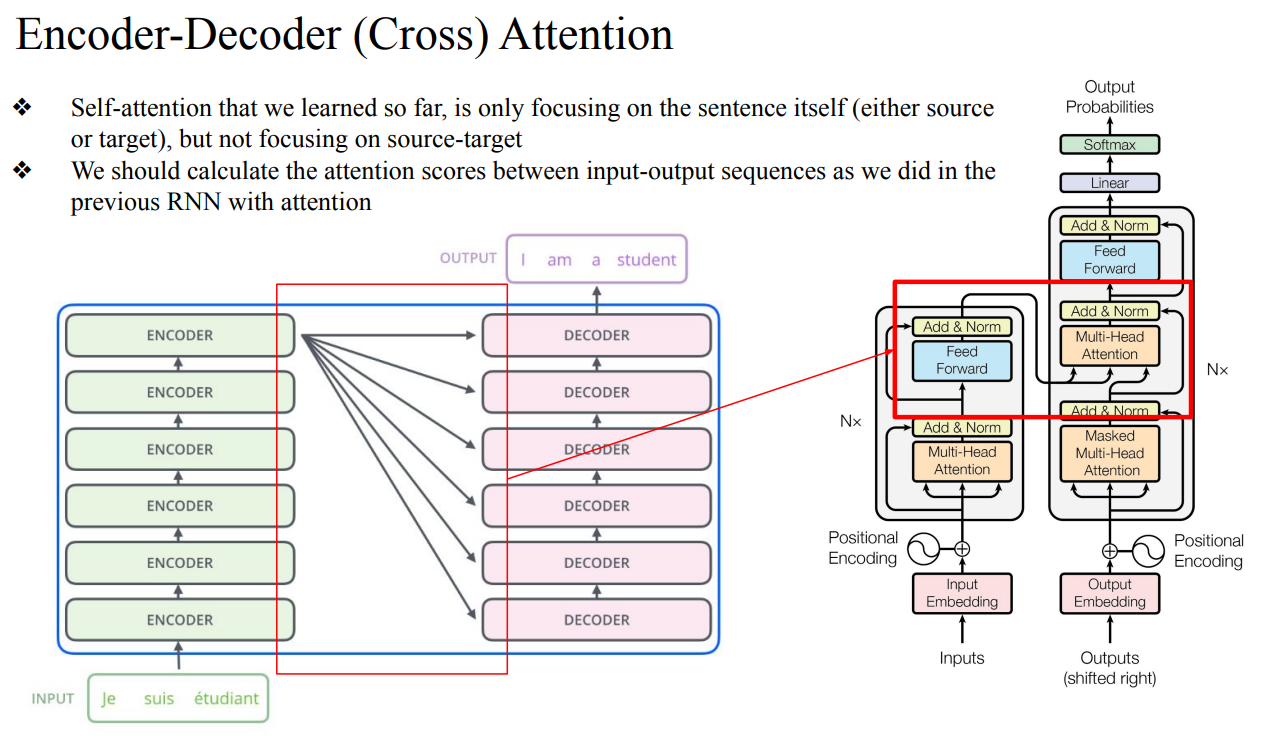
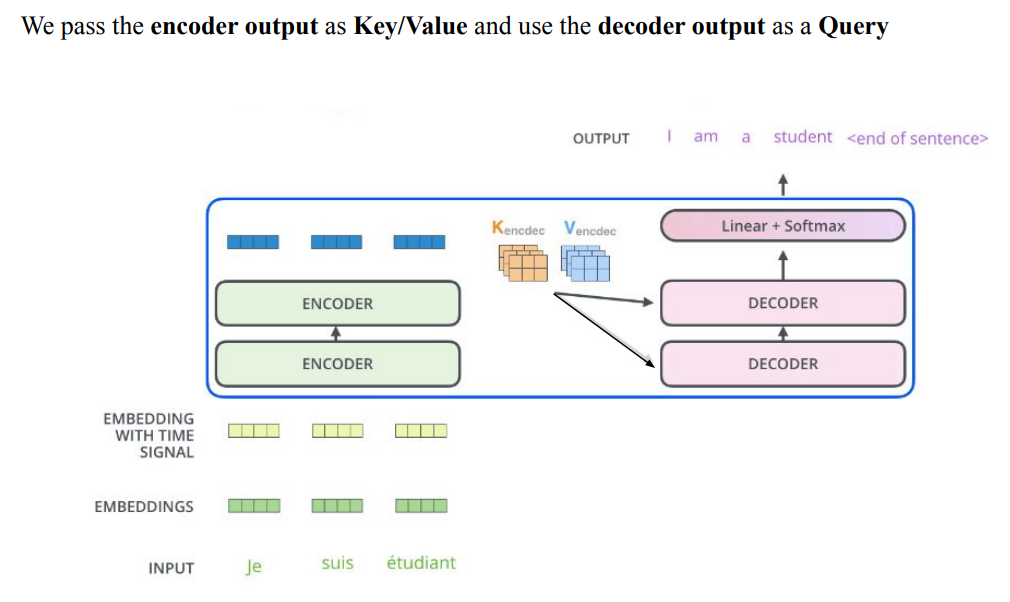
- 여러번의 과정을 거쳐서 나온 최종 encoder의 output이 decoder의 Multi-Head Attention의 input으로 들어감
- encoder의 output은 Key와 Value로, decoder의 output은 Query로 들어가짐
- 여기서 층이 깊어질수록 (N값) model의 크기가 커짐 (LLM)
Positional Encoding
- 평범하게 각 Word마다 순서대로 특정 값을 더하게 될 경우, word의 수가 굉장히 많아 지면 word embedding vector의 크기가 매우 커져서 network가 제대로 작동을 안할 수도 있음
- 그렇기 때문에 주기함수를 사용하여 추가되는 vector의 크기를 크지 않은 값으로 고정시킴

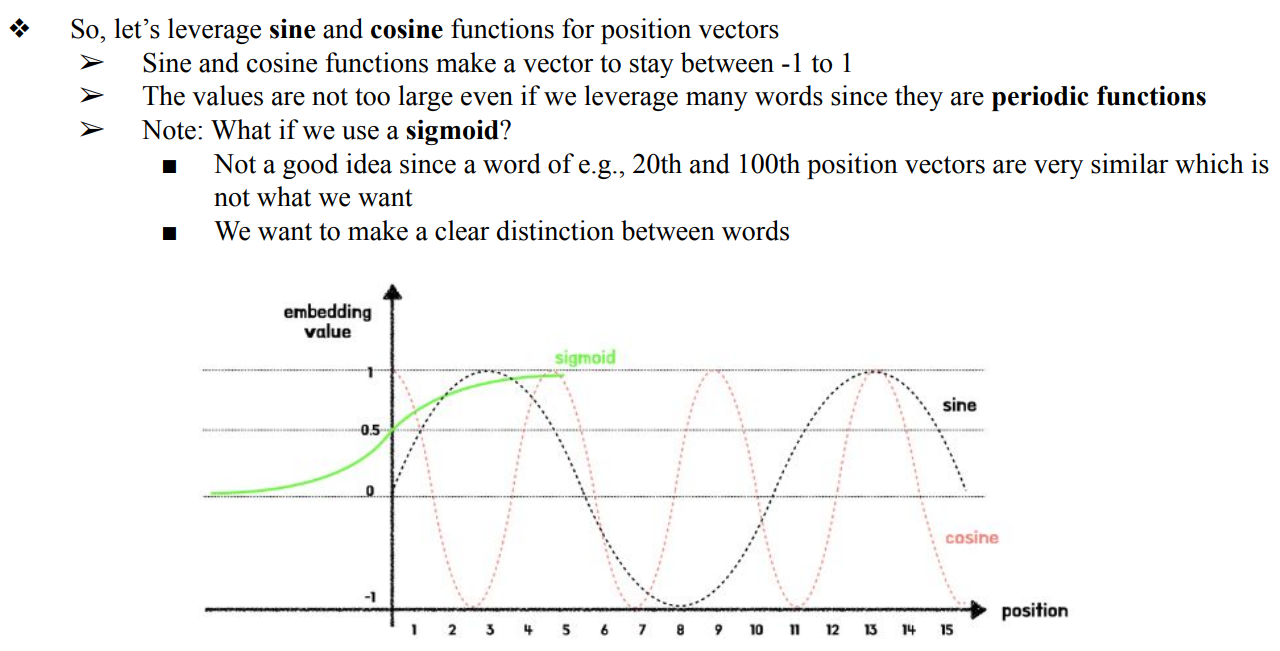
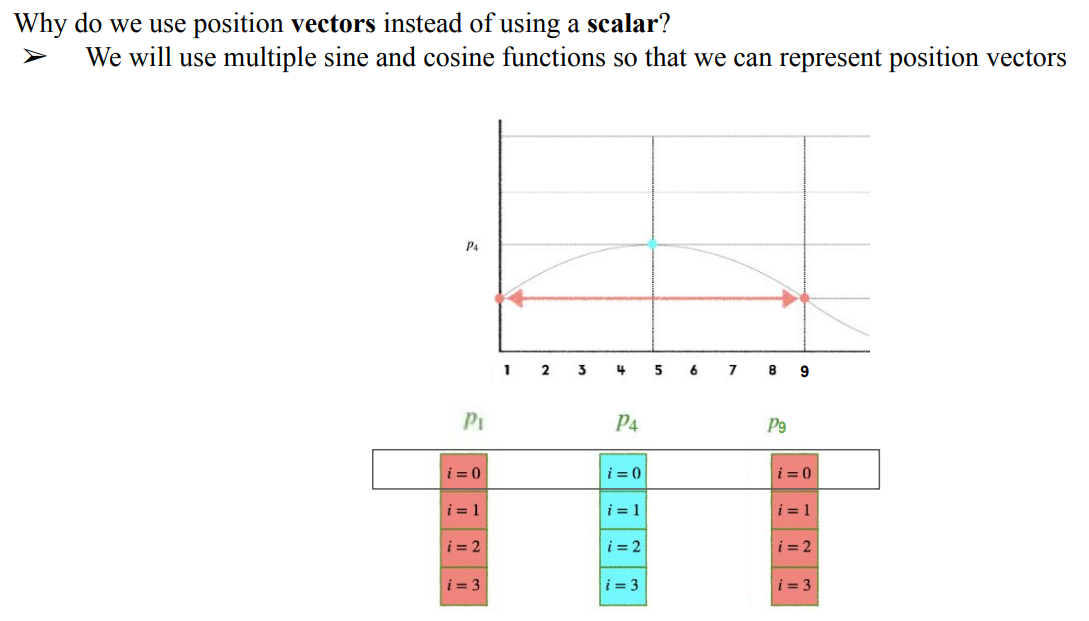
- 결국 각 word embedding vector마다 순서가 다르다는 것을 의미하게 하고 싶은것이지만 주기함수 특성상 같은 같이 반복됨
- 짝수와 홀수를 각 다른 주기함수로 나누고, 각 dimension별로 상수를 추가하여 주기를 다르게 해서 순서의 차이를 표현함 (d-model은 fixed 값)
- Positional Encoding덕분에 transformer based model들은 매우 긴 context들도 처리를 할 수 있게 됨

- 참고자료
Attention in transformers, step-by-step | Deep Learning Chapter 6

AI & Robotics