(한양대학교 박서연 교수님의 딥러닝 수업을 청강 하면서 정리한 내용을 바탕으로 교수님의 허락을 받고 작성하였습니다.)
word2vec
Word2Vec_Pre_trained_Model Code - GitHub
- 모든 compute에 대해 gradient를 구하고 weights를 업데이트 하는 과정 : 역전파(backpropagation)
- 즉, backpropagation 과정에서 gradient algorithm을 사용하는 것
- 즉, backpropagation 과정에서 gradient algorithm을 사용하는 것
- rate of change (slope) : 얼마나 빠르게 변하는가
- distributional semantics : 단어의 의미(=semantics)는 그 단어와 가까이에서 자주 나타나는 다른 단어들에 의해 정의됨
- Word2vec proposed by Google
- center word : c, context words : o 일때, word P(o | c)의 값을 높여가는 방법론
- 핵심은 확률값을 높여가는것
- Word Embedding의 핵심 : distributional semantics
- 그 단어 하나만이 아닌 모든 단어를 고려하여 그 단어의 의미를 담겠다
- Word Embedding전에 Calculate the probability of context word가 제일 중요함
- 희소한 단어를 어떻게 처리를 하느냐 (P(o|c)를 어떻게 정의하느냐에 따라 모델이 달라짐)

Word2vec : Loss Function
- dot product 방식으로 probability of context word를 계산
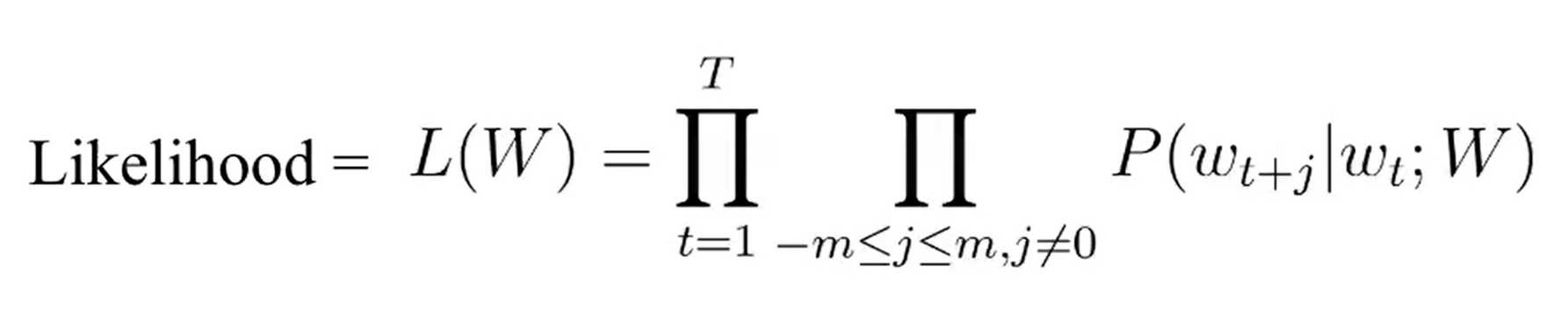
- probability를 높여나가는게 목표 > 딥러닝은 maximize보다 minimize가 쉬우니 LOSS로 계산
- 수백~수천번 0~1사이의 값을 계산하게 되면 0에 수렴할 위험이 있음 (under flow) > log로 해결
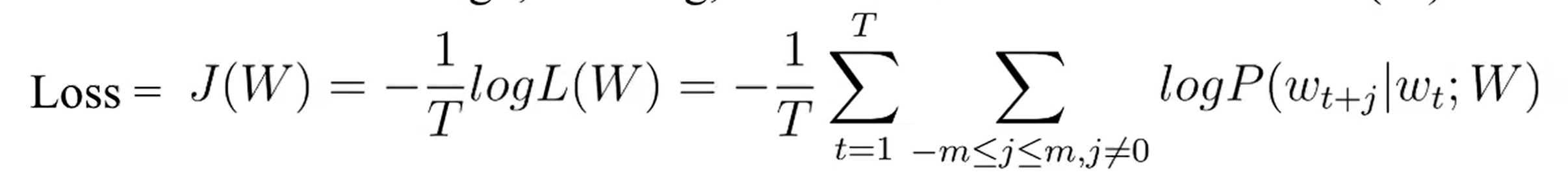
- 그래서 어떻게 Loss Function을 정의할 것인가 > 핵심은 dot product
- positive하게 만든 후 normalization
- center word vector(target)와 context word vector의 dot product를 maximize를 시키는 것
- dot product는 0~1사이의 값이 아니기 때문에 확률적으로 변환하기 위해 sofrmax 함수를 사용한다

Word2vec : optimization
- Optimization : Loss가 최소가 되게끔 W Matrix를 update하는 과정
- center word일때의 parameter와 context word일때의 parameter로 하나의 word가 독립적으로 2개의 parameter를 가짐 -> vocabulary안에 2개로 존재
- loss를 minimize하는 게 핵심이기 때문에 마찬가지로 gradient descent를 적용하여 W의 parameter를 업데이트함

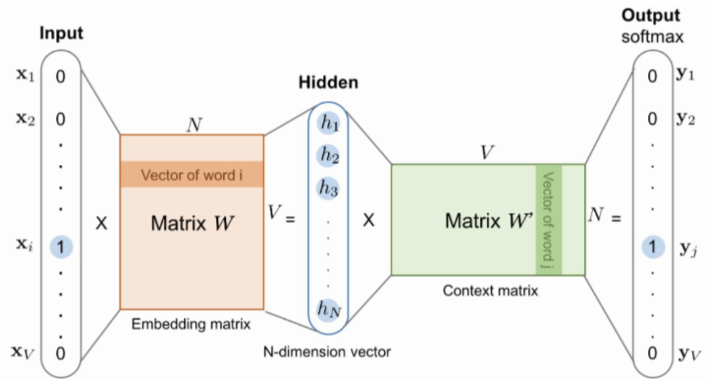
Word2vec : Architecture
- Matrix W : center word(& target word)일때의 가중치
- Matrix W’ : context word일때의 가중치
- shape은 동일함
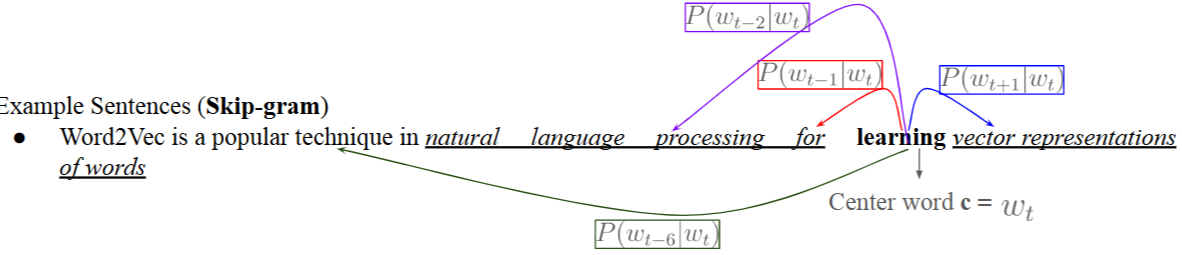
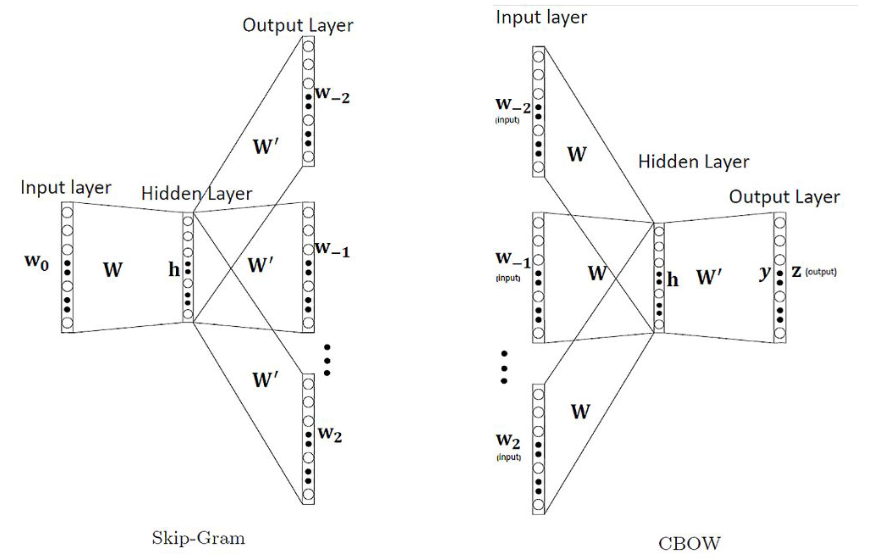
- Word2vec: Skip-gram vs CBOWs (Skip-gram이 조금더 우세)
- Skip-gram : center word가 주어졌을때 context word가 올 확률에 초점을 둠
- CBOWs : context words가 주어졌을때 center word가 올 확률에 초점을 둠
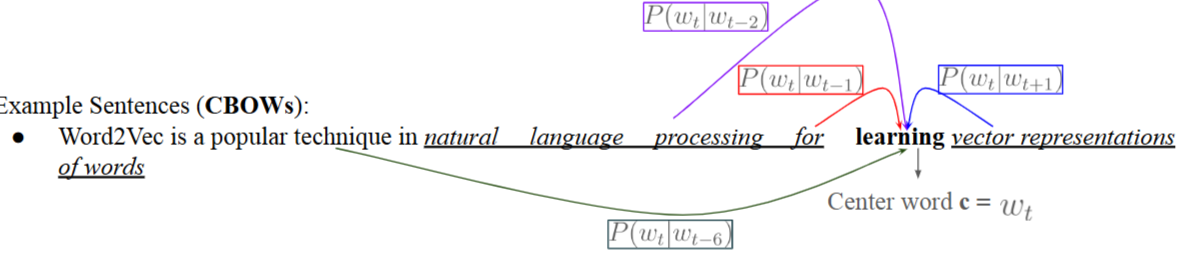
- 구현에도 약간의 차이가 존재함
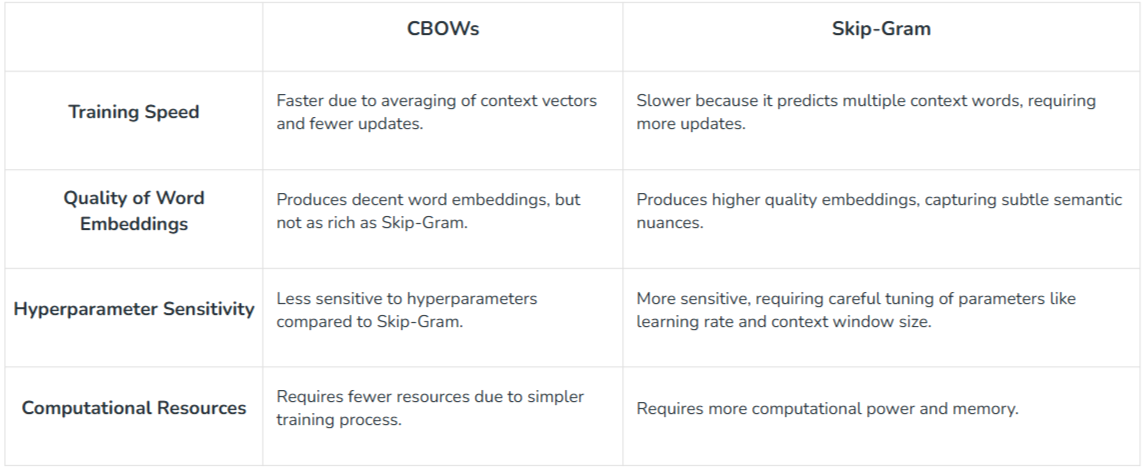
CBOW vs Skip-gram (Summary)

- 속도는 CBOW, 정확도는 Skip-Gram
GloVe 방법 (GloVe paper)
- GloVe : learning을 시킬때 통계적인 의미도 학습을 시킴
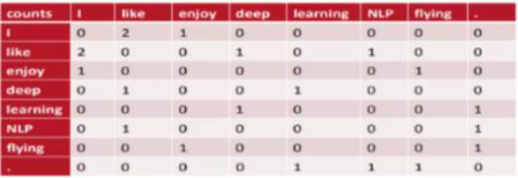
- NN전에는 통계적으로 계산함 (모든 Words의 빈도 수를 확인)
- it, a, the 등 의미는 없지만 자주나오는 단어를 통계적으로 처리
- Word2vec, skip-gram : dot product만 써서 단어의 의미만 확인함
- 기존의 이런 방식은 단어사전의 크기가 너무 커지고 0이 많아지는 문제가 생김
- 긴벡터를 2개로 쪼개서 의미를 확인한다 > SVD(Singular Value Decomposition)
- Deep Neural Network로 word vector representation을 하고 있는데, 통계적인 방법론을 사용하기위해 SVD Learning을 또 적용해야하다 보니 너무 복잡해짐
- GloVe를 사용하면 통계적인 word vector representation을 얻으면서도, Deep Learning Model training으로 얻을 수있는 모델을 개발하기 위해 사용됨
- 즉, 이런 통계적인 Matrix를 어떻게 Loss function에 적용할 것인가
- 그럼에도 뜻이 다른 같은 단어에 대해 의미의 차이를 확인하지 못함
- 여기에 초점을 둔 모델이 FastText임
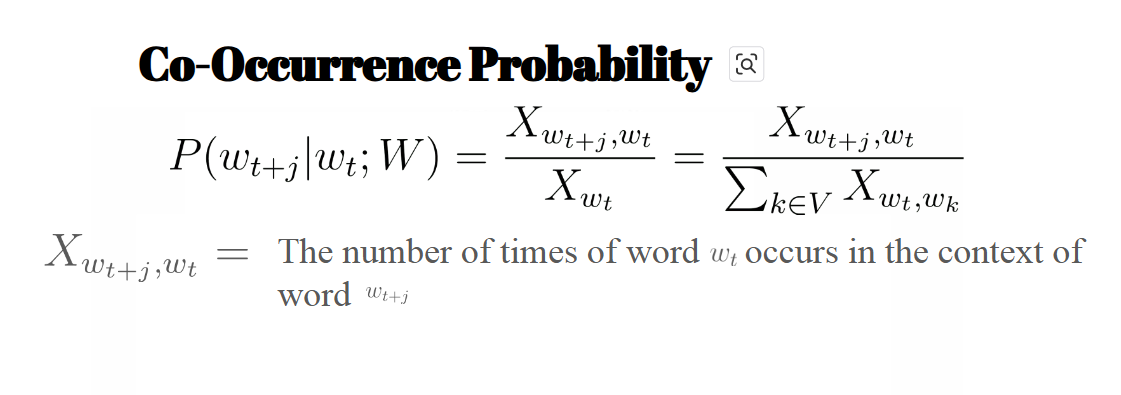
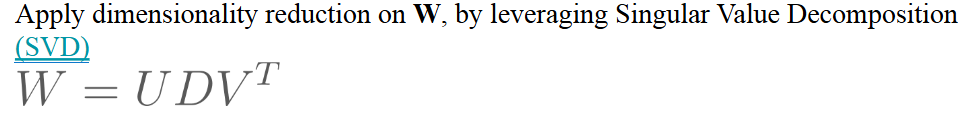

- FastText : 오탈자의 강력한 모델 (FastText paper)
- 단어안의 상관관계까지 모두 learning을 함
- 오탈자의 이슈에 초점을 맞춰서 연구가됨

- 기존 Word Vector representaion model은 음식의 apple과 회사의 apple의 차이를 모른다
- 주변 문맥을 통한 의미의 차이를 두지 못함 > tranformers의 등장으로 NLP가 기하급수적으로 성장하게됨
- 참고자료
Embedding projector - visualization of high-dimensional data
Efficient Estimation of Word Representations in Vector Space

AI & Robotics