(한양대학교 박서연 교수님의 딥러닝 수업을 청강 하면서 정리한 내용을 바탕으로 교수님의 허락을 받고 작성하였습니다.)
Activation Functions
Activation_Function Code - GitHub
Activation Functions
- Basics Activation Functions : Sigmoid, Tanh, ReLU
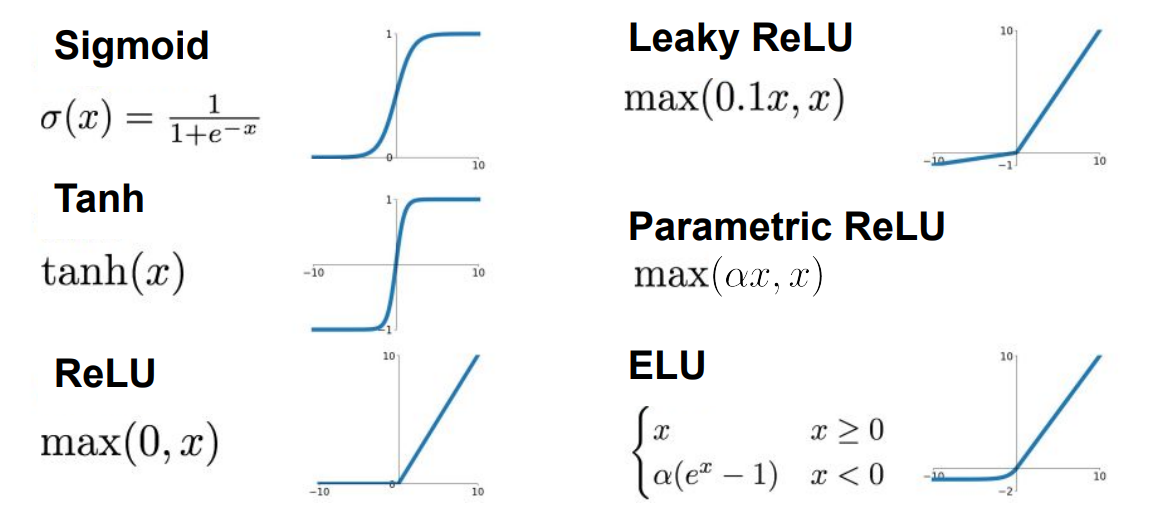
Sigmoid
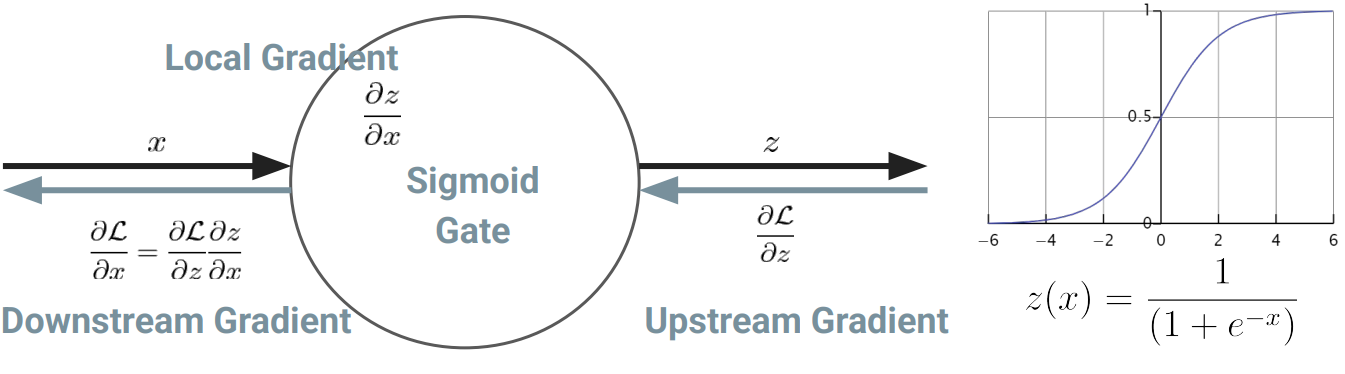
- neuron이 포화되었는지 확인하는 Activation Function
- neuron이 어떤 input이 들어왔을때 반응이 없으면 포화되었다고 함
- 즉, gradients 정보가 소실됨

Problem 1
- neuron이 포화되었는지 빠르게 확인 할 수 있는 benefit이 있지만, 반대로 Sigmoid를 사용했기때문에 neuron이 포화되는 현상이 생김
- ex) input = -6이면 gradient가 0이되버림 → Vanishing Gradient
Problem 2
- Sigmoid outputs are not zero-centered
- 모든 input이 다 양수일때, 모든 gradient가 다 양수이거나 음수가 되버릴 수 있음 (not always)
- gradient의 의미가 없어짐 → 한방향으로만 update됨
- Batch Normalization : 이를 해결하기위해 다 양수이거나 음수가 아니게 변경해주는 것

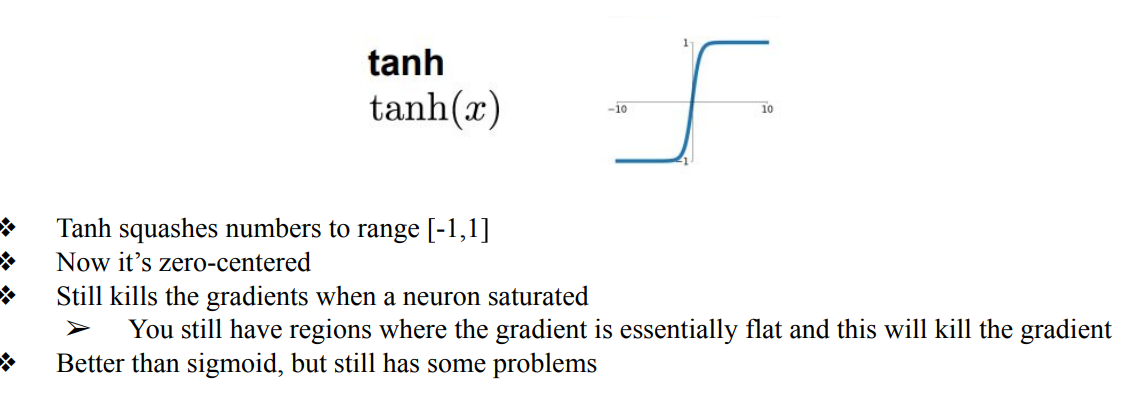
tanh
- Sigmoid의 Problem 2를 해결하기위한 zero-centered 형태인 Activation Function
- 하지만, neuron이 포화되었을때 Still kills the gradients 됨 (Vanishing Gradient)
ReLU
- Sigmoid나 tanh의 neuron saturated 이슈를 해결하기 위한 형태의 Activation Function
- negative Value에 대해선 여전하지만, positive 부분에서는 Vanishing Gradient 문제를 해결함

Leaky ReLU
- negative Value에 대해서도 해결하기 위한 형태의 Activation Function

ELU (ELU Paper)
- 모든 이슈들을 해결하기 위한 형태의 Activation Function

- 그외의 현대의 Activation Function들 → 최근 동향은 여러 Activation Function을 융합하는 형태임
- 그래서 random하게 Weight Initialization하는것이 중요함


AI & Robotics