(한양대학교 박서연 교수님의 딥러닝 수업을 청강 하면서 정리한 내용을 바탕으로 교수님의 허락을 받고 작성하였습니다.)
Regularization
- Regularization통해 generalization을 잘해야 overfitting을 방지할 수 있음
- model training의 목표는 generalization된 model을 만드는것 → Regularization를 통해 train data를 외워버리는 overfitting issue를 방지해야함
- 사실 데이터를 많이 모으는것이 제일 좋음

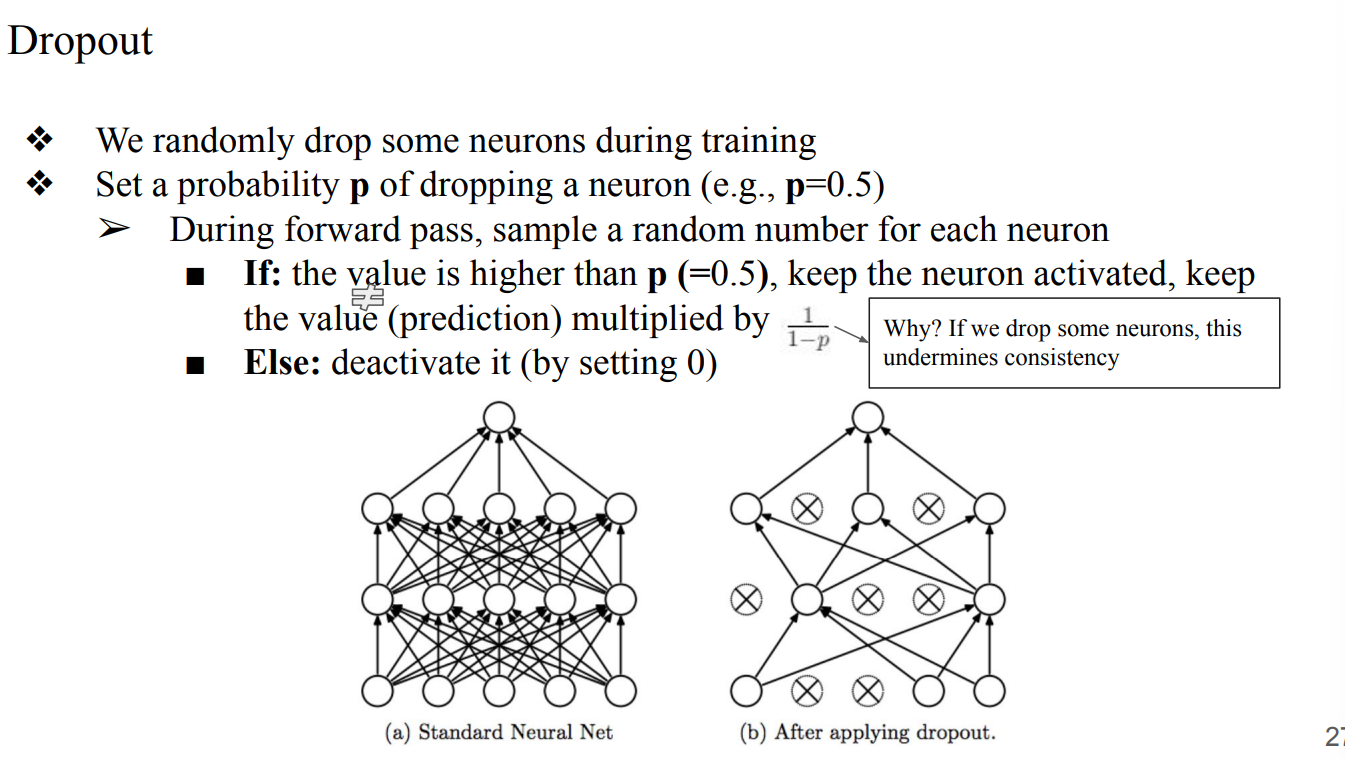
- idea : 너무 많은 neuron들이 불필요하게 학습이 되고있기 때문에 몇몇 neuron을 껏다 켰다하자
- 각 neuron들을 random하게 sampling해서 value를 확인하고, activate할지 deactivate할지 정한다
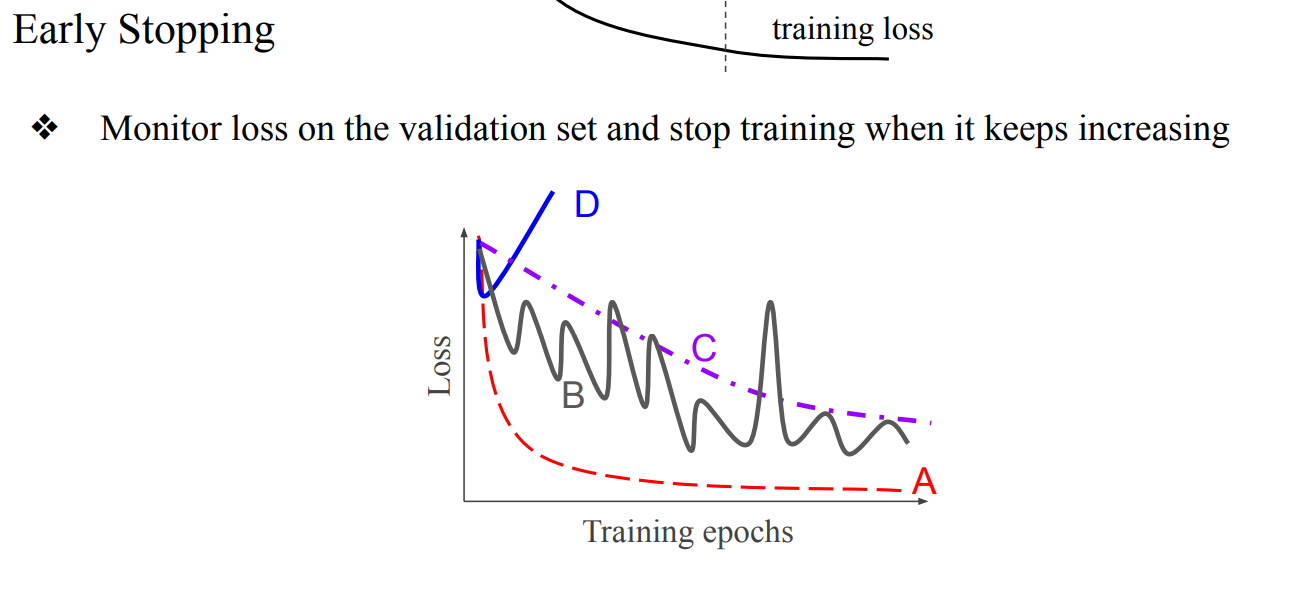
- Training Loss와 eval Loss을 관측하고 특정순간 이후로 지속적으로 eval Loss가 계속 증가하면 중간에 training을 멈춤
- 너무 성급하게 Early Stopping을 하는것 보다 Loss을 분석하고 learning rate을 조절하는것이 더 옳바른 방법임
- Weight Decay는 Weight가 엄청 큰 경우에만 작용하는 regularization technique이다 → 항상 잘 적용되지는 않음
- Weight의 크기를 측정하여 loss을 작게 만드는것이 목표
- 즉, Weight가 크지 않으면 Weight Decay가 잘 작동하지 않을 수가 있음
- L1 : sparse model에서 유용함
- 중요하지 않은 weight를 0으로 보내서 feature selection 효과를 내고, parameter를 자연스럽게 sparse하게 만들기 때문
- L2 : deep learning에서 유용함
- 모든 weight를 부드럽게 shrink시켜서 gradient가 항상 well-define되다보니, backpropagation과 optimization이 안정적이고 generalization을 개선하기 때문


AI & Robotics