
서브쿼리 위치에 따른 SQL 용어
서브쿼리란 쿼리 안의 보조쿼리를 가리키는 용어이다. 가장 바깥의 SELECT 문인 메인 쿼리를 기준으로 내부에 SELECT 문을 추가로 작성해서 서브쿼리를 만든다. 작성되는 위치에 따라 그 종류가 달라진다.
스칼라 서브쿼리
메인쿼리는 SELECT 절에 있는 또 다른 SELECT 절이 스칼라 서브쿼리이다. 메인쿼리의 SELECT 절에는 최종 출력하려는 열들이 나열되므로, 출력 데이터 1건과 스칼라 서브쿼리의 결과 건수가 일치해야 한다. 만약 스칼라 서브쿼리의 결과값이 2개 이상 나온다면 에러가 발생합니다. 즉, 결과값이 1행 1열의 구조로 출력되어야 한다.
SELECT name,
(SELECT COUNT(*)
FROM student AS student2
WHERE student2.name=student1.name) COUNT
FROM student AS student1인라인 뷰
메인쿼리의 FROM 절에 있는 또 다른 SELECT 절이 인라인 뷰라고 한다. 인라인 뷰의 결과는 내부적으로 메모리 또는 디스크에 임시 테이블을 생성하여 활용한다.
SELECT student2.id, student2.name
FROM (SELECT *
FROM student
WHERE gender = 'Male') student2;중첩 서브쿼리
메인쿼리의 WHERE 절에 있는 또 다른 SELECT 절을 중첩 서브쿼리라고 한다. WHERE 절에서 단순 값 이상의 값들을 비교 연산하기 위해 사용한다. 보통 비교 연산자나 IN, EXISTS, NOT IN, NOT EXISTS 문과 함께 사용된다.
SELECT *
FROM student
WHERE id = (SELECT MAX(id)
FROM student);메인쿼리와의 관계성에 따른 SQL 용어
비상관 서브쿼리
메인쿼리와 서브쿼리 간에 관계성이 없음을 의미한다. 서브쿼리가 독자적으로 실행된 뒤 메인쿼리에게 그 결과를 넘겨주는 형태이다.
SELECT *
FROM student
WHERE id IN (SELECT id
FROM professor);비상관 서브쿼리에서는 서브쿼리 → 메인쿼리의 순서로 실행된다. 아래와 같은 예제 쿼리는 DB 버전 및 옵티마이저에 따라 서브쿼리가 제거되고 하나의 메인쿼리로 통합되는 뷰 병합, 즉 SQL 재작성이 작동할 수 있다.
SELECT *
FROM student
WHERE id IN (SELECT id
FROM student
WHERE gender = 'MALE')상관 서브쿼리
메인쿼리와 서브쿼리 간에 관계성이 있음을 의미한다. 상관 서브쿼리는 SELECT 절에 작성하는 스칼라 서브쿼리와 WHERE 절에 작성하는 중첩 서브쿼리일 때 발생한다.
SELECT *
FROM student s
WHERE s.id IN (SELECT p.id
FROM professor p
WHERE s.name=p.name);위 예제 쿼리의 수행 순서는 다음과 같다.
- 메인쿼리 실행(
s.name데이터 조회) - 서브쿼리 실행(
s.name=p.name) - 다시 메인쿼리 실행한 뒤 결과 출력
이 쿼리를 실행할 때도 뷰 병합, 즉 SQL 재작성이 발생할 수 있다.
반환 결과에 따른 SQL 용어
서브쿼리의 결과 유형은 반환하는 행, 열의 수에 따라 구분할 수 있다.
단일행 서브 쿼리
서브쿼리 결과가 1건의 행으로 반환되는 쿼리이다. 이 결과는 보통 메인쿼리의 조건절에서 =,< 등의 연산자를 통해 비교한다. 스칼라 서브쿼리와 동일하다고 볼 수 있다.
SELECT ...
FROM ...
WHERE id = (SELECT MAX(id) FROM student);다중행 서브 쿼리
서브쿼리 결과가 여러 건의 행으로 반환되는 쿼리이다. 메인쿼리의 조건절에서는 IN 구문으로 서브쿼리의 결과를 받는다.
SELECT ...
FROM ...
WHERE id IN (SELECT MAX(id)
FROM student
GROUP BY major_code);다중열 서브쿼리
서브쿼리 결과가 여러 개의 열과 행으로 반환되는 경우이다. 메인쿼리의 조건절에서는 IN 구문과 함께 서브쿼리에서 반환될 열들을 동일하게 나열해 결과를 받는다.
SELECT ...
FROM ...
WHERE (name, major_code)
IN (SELECT name, major_code
FROM student
WHERE name LIKE 'kim%');조인 연산방식 용어
다수의 테이블에서 필요한 데이터를 결합할 때 조인이라는 방식을 사용한다. 분리된 데이터 간의 공통 정보, 즉 동일한 열값 또는 키값 기준으로 데이터를 논리적으로 연결할 수 있다.
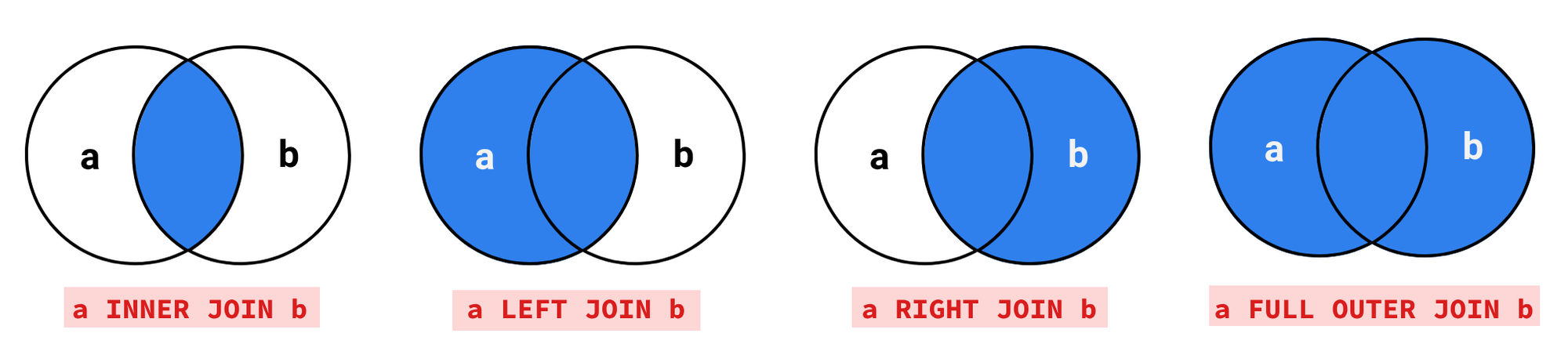
내부 조인
교집합에 해당하는 방식으로, 양쪽 모두 존재하는 데이터만 반환한다. 명시적, 암시적으로 내부 조인 쿼리를 작성할 수 있다.
---명시적
SELECT student.id, student.name, professor.name
FROM student
JOIN professor
ON student.id=professor.id;
--묵시적
SELECT student.id, student.name, professor.name
FROM student, professor
WHERE student.id=professor.id;왼쪽 외부 조인
왼쪽 테이블(먼저 작성된 테이블) 기준으로 오른쪽 테이블과 조인을 수행하며, 조인 조건과 일치하지 않더라도 왼쪽 테이블의 결과는 최종 결과에 포함된다.
SELECT student.id, student.name, professor.name
FROM student
LEFT OUTER JOIN professor -- LEFT JOIN professor
ON student.id=professor.id;오른쪽 외부 조인
오른쪽 테이블(나중에 작성된 테이블) 기준으로 왼쪽 테이블과 조인을 하지만, 조인 조건에 부합하지 않더라도 오른쪽 테이블의 결과를 최종 결과에 포함한다.
SELECT professor.id, student.name, professor.name
FROM student
RIGHT OUTER JOIN professor -- RIGHT JOIN professor
ON student.id=professor.id;사람의 인지적 특성상 왼 → 오 방향이 편하기 때문에 왼쪽 외부 조인 위주로 작성하는 것이 유지보수, 관리 편의성 측면에서 유리하다.
전체 외부 조인은 MySQL,MariaDB에서 지원하지 않는다.
교차 조인
수학적 관점에서 데카르트 곱(cartesian product)라는 개념으로 조인에 참여하는 테이블에서 가능한 모든 조합을 찾아내어 반환한다. 연산과정의 시간, 공간적 리소스 점유 측면에서 오버헤드가 발생하기에 주의해서 사용해야 한다.
--명시적
SELECT student.id, student.name
professor.id, professor.name
FROM student
CROSS JOIN professor;
--묵시적
SELECT student.id, studnet.name
professor.id, professor.name
FROM student, professor;자연 조인
2개 테이블에 동일한 열명이 있을 때 조인 조건절을 따로 작성하지 않아도 자동으로 조인을 수행해주는 방식이다. 조인이 제대로 성사되면 내부 조인과 같은 결과가 도출된다.
SELECT student.*, professor.*
FROM student
NATURAL JOIN professor;하지만 자연 조인을 사용해도 동일한 열명이 없다면 발생 가능한 모든 경우의 수를 모두 조합하는 교차 조인으로 수행된다. 의도치 않은 결과를 도출할 수 있기에 보통 잘 사용되지 않는다.
조인 알고리즘 용어
드라이빙 테이블과 드리븐 테이블
SELECT student.id, student.name,
emergency_contact.relation, emergency_contact.phone_number
FROM student
JOIN emergency_contact
ON student.id=emergency.id
WHERE student.id IN (1, 100)원하는 결과를 추려 결합하는 조인을 수행할 때, 테이블에 동시 접근할 수는 없으므로 테이블의 데이터에 접근하는 우선순위가 존재한다. 위 예제에서 먼저 접근하는 student 테이블이 드라이빙 테이블이고, 이어서 접근되는 emergency_contact 테이블이 드리븐 테이블이다.
드라이빙 테이블에서 많은 건수가 반환되면 그 결과를 가지고 드리븐 테이블에 접근하게 되기에 드라이빙 테이블을 무엇으로 결정하는 지가 중요하다. 가능하면 적은 결과가 반환되는 드라이빙 테이블을 선정하고, 조인 조건절의 열이 인덱스로 설정되도록 구성해야 한다.
중첩 루프 조인
NL 조인(nested loop join)은 드라이빙 테이블의 데이터 1건당 드리븐 테이블을 반복해 검색하며 최종적으로는 양쪽 테이블에 공통된 데이터를 출력한다.
먼저 기본 키와 인덱스가 없는 상황에서 다음 쿼리로 극단적인 NL 조인을 수행한다.
SELECT student.id, student.name
emergency_contact.relation, emergency_contact.phone_number
FROM student
JOIN emergency_contact
ON student.id=emergency_contact.id
WHERE student.id IN (1,100)
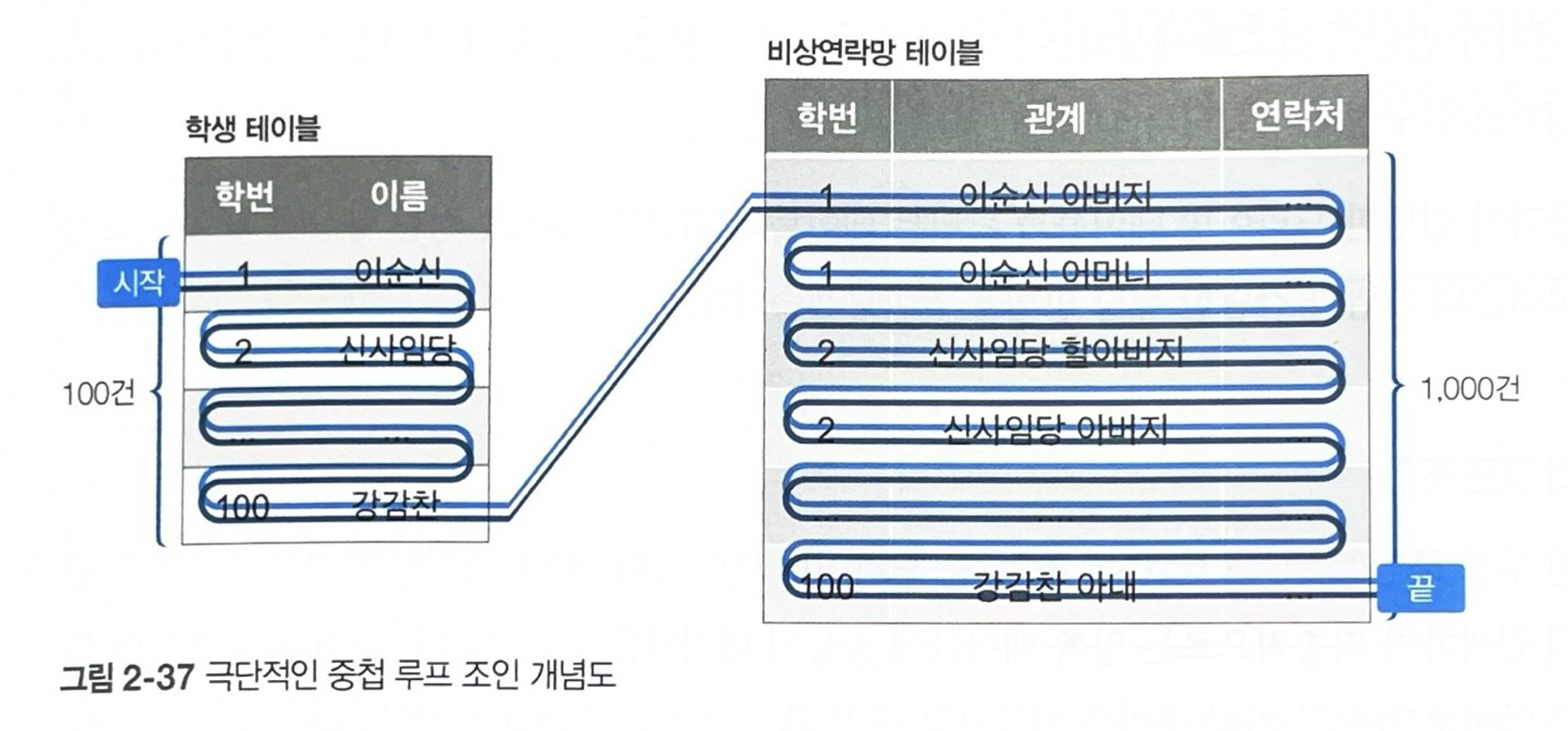
이 쿼리는 학번 1 데이터(100+1000)와 학번 100 데이터(100+1000)를 조회하기 위해 대략 2200건의 데이터에 접근하게 된다.
이번에는 학생 테이블에 학번 열로 인덱스가 생성되어 있고, 비상연락망 테이블에도 학번 열로 인덱스가 생성되어 있는 환경을 가정해보자. 앞선 쿼리를 똑같이 수행하면 인덱스를 기반으로 데이터에 접근한다.
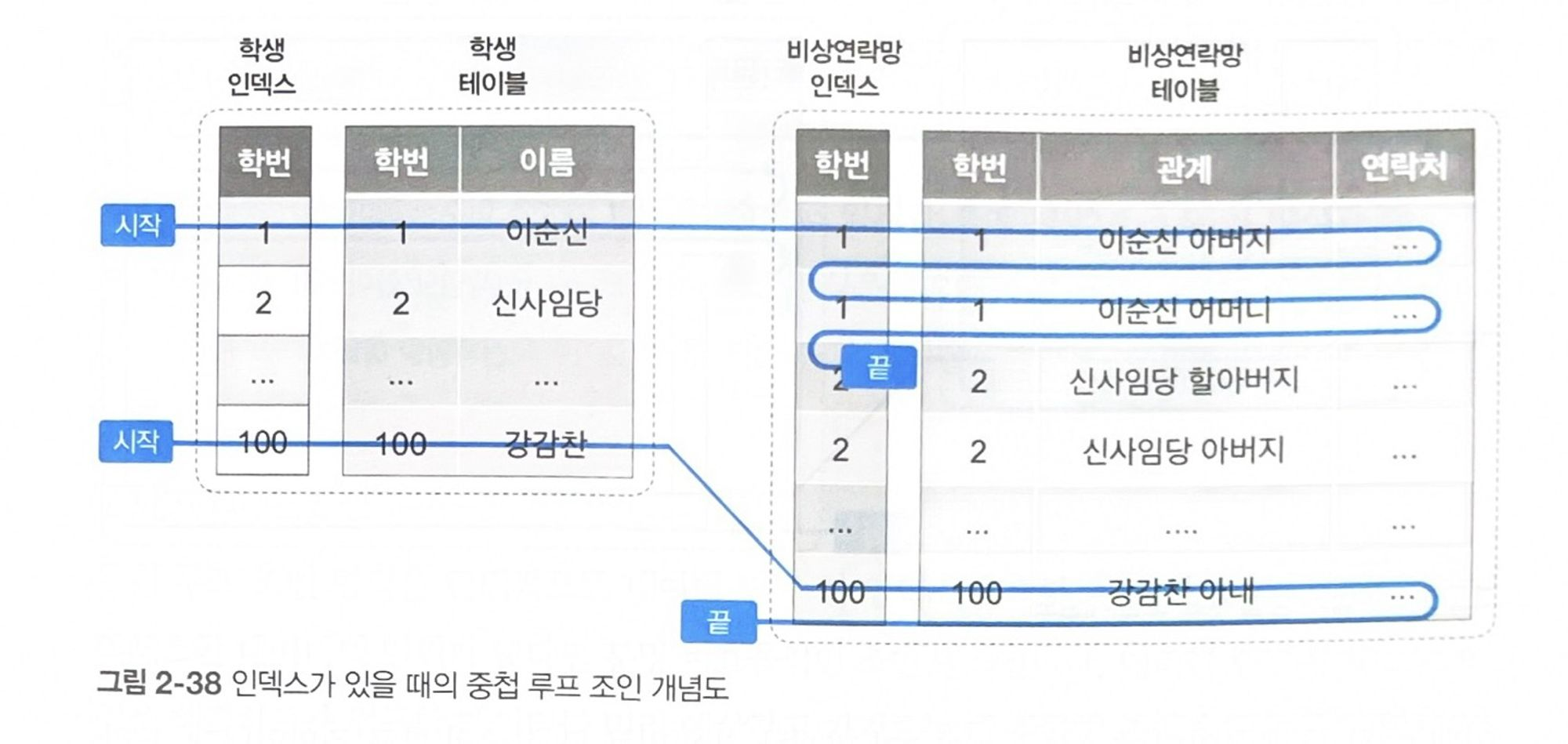
학번 1인 데이터(1+2)와 학번 100인 데이터(1+1)를 찾기 위해 총 6건의 데이터에 접근하게 된다.
사실 인덱스는 인덱스로 정의된 열 기준으로 순차 정렬되지만, 인덱스를 이용해 테이블의 데이터를 찾아가는 과정에서 임의 접근 방식인 랜덤 액세스가 발생한다. 따라서 랜덤 액세스를 줄이도록 데이터 액세스 범위를 좁히는 방향으로 인덱스를 설계하고 조건절을 작성해야 한다.
단, 랜덤 액세스를 유발하는 인덱스는 기본 키가 아닌 비고유 인덱스일 경우에 해당한다. 기본 키는 클러스터형 인덱스인지라 키의 순서대로 테이블의 데이터가 적재되어 있어 조회 효율이 매우 높다.
블록 중첩 루프 조인
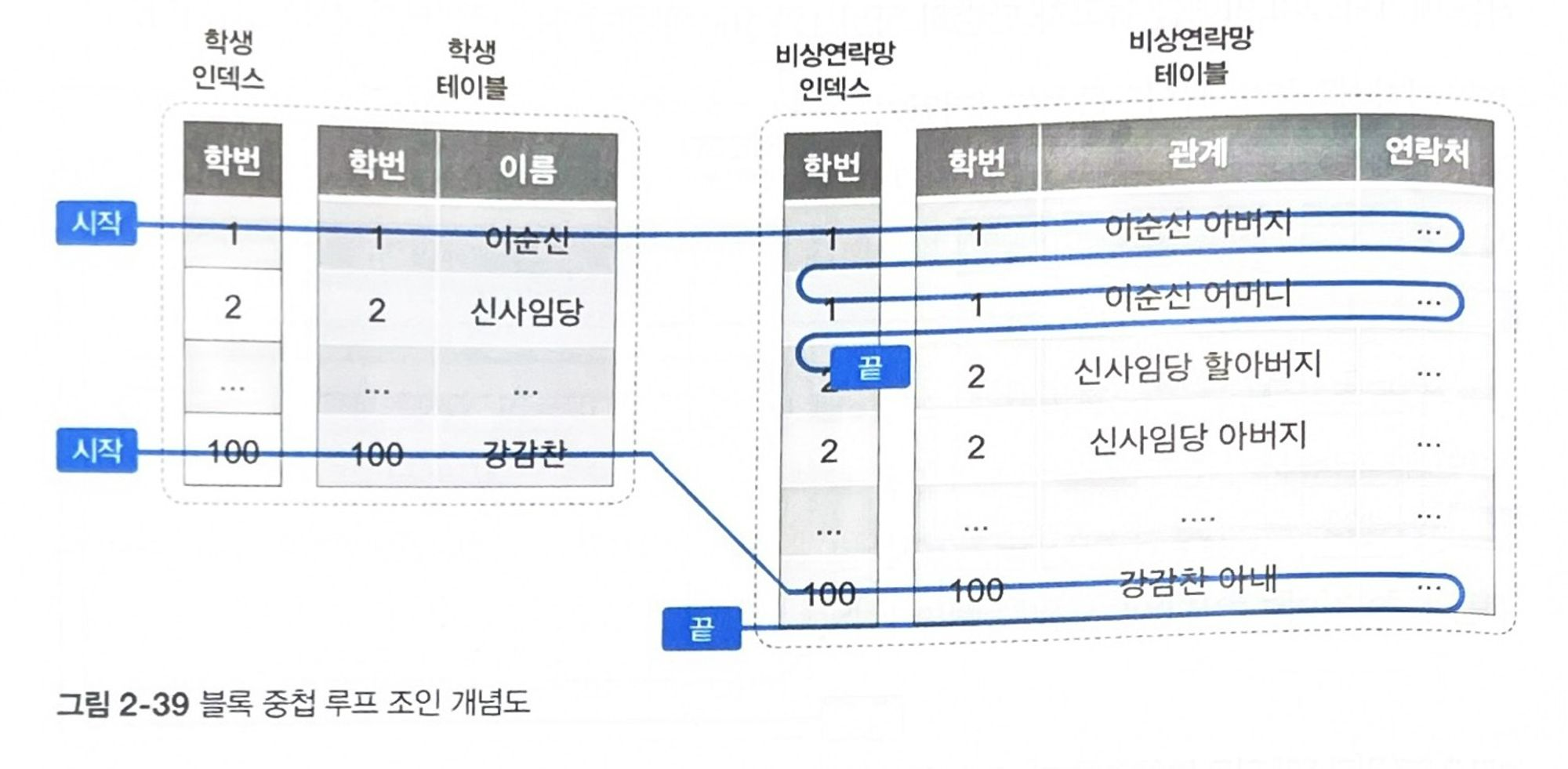
위와 같은 중첩 루프 조인 실행 상황에선 인덱스가 없는 드리븐 테이블에 대해 매번 전체 데이터를 비효율적으로 검색해야 한다.
이런 NL 조인의 효율성을 높이기 위해 BNL 조인이 탄생하였다.
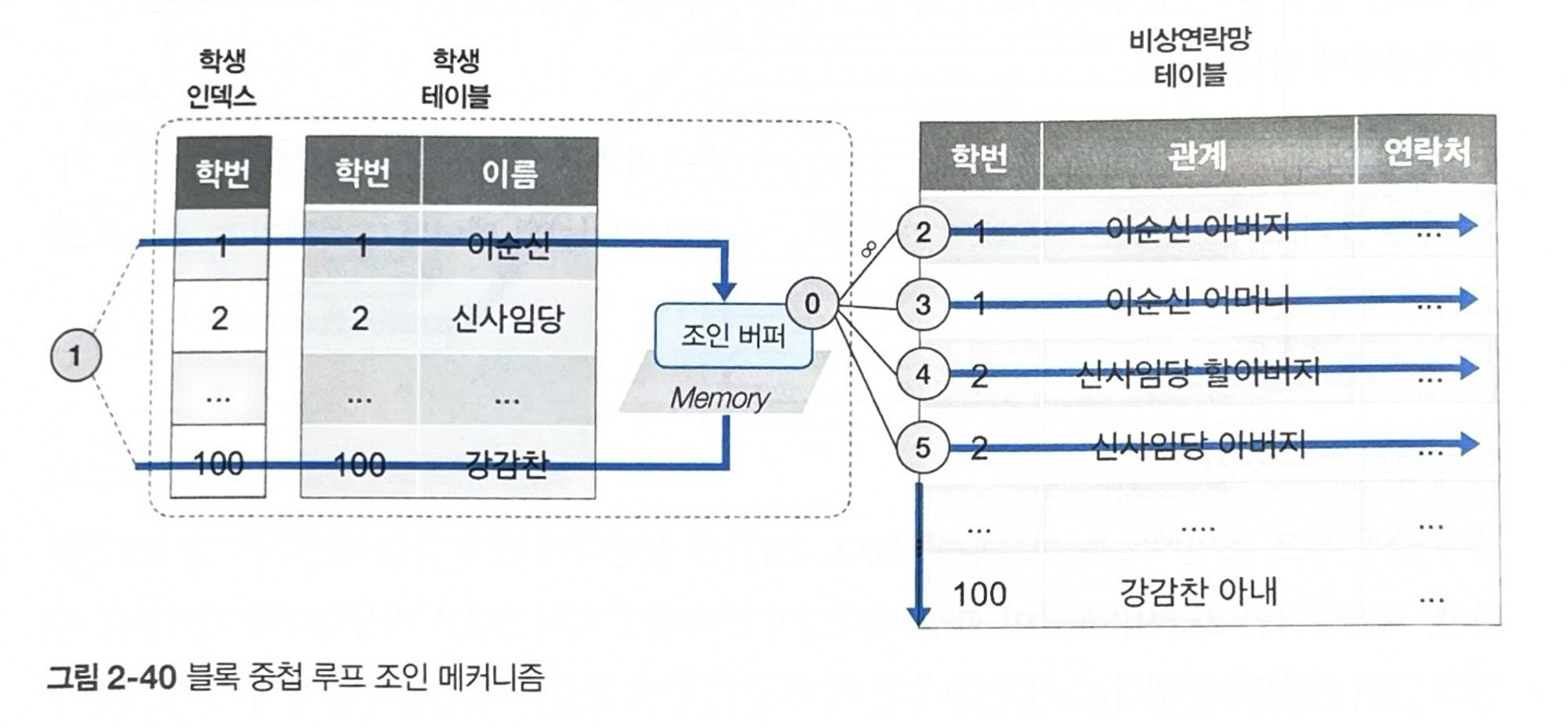
BNL 조인의 수행 절차는 다음과 같다.
- 드라이빙 테이블인 학생 테이블에서 학번 1,100 데이터를 검색한다. 검색된 데이터를 조인 버퍼에 가득 채워질 때까지 적재한다.
- 조인 버퍼와 비상연락망 테이블의 데이터를 비교한다. 조인 버퍼와 비상연락망 테이블에 데이터들을 순차적으로 조인하는 방식으로 모두 접근한다.
위 절차를 통해 조인 버퍼-비상연락망 테이블간 한 번의 테이블 풀 스캔으로 원하는 데이터를 모두 찾을 수 있다. 이 과정은 드리븐 테이블의 풀 스캔을 줄이는 게 목적이다.
배치 키 액세스 조인
BNL 조인 방식은 데이터 접근시 인덱스에 의한 랜덤 액세스가 발생하므로, 액세스할 데이터 범위가 넓다면 비효율적인 방식이다. 이를 해결하고자 접근할 데이터를 미리 예상하고 가져오는 데 착안한 알고리즘을 배치 키 액세스 조인 알고리즘(BKA 조인)이라고 한다.
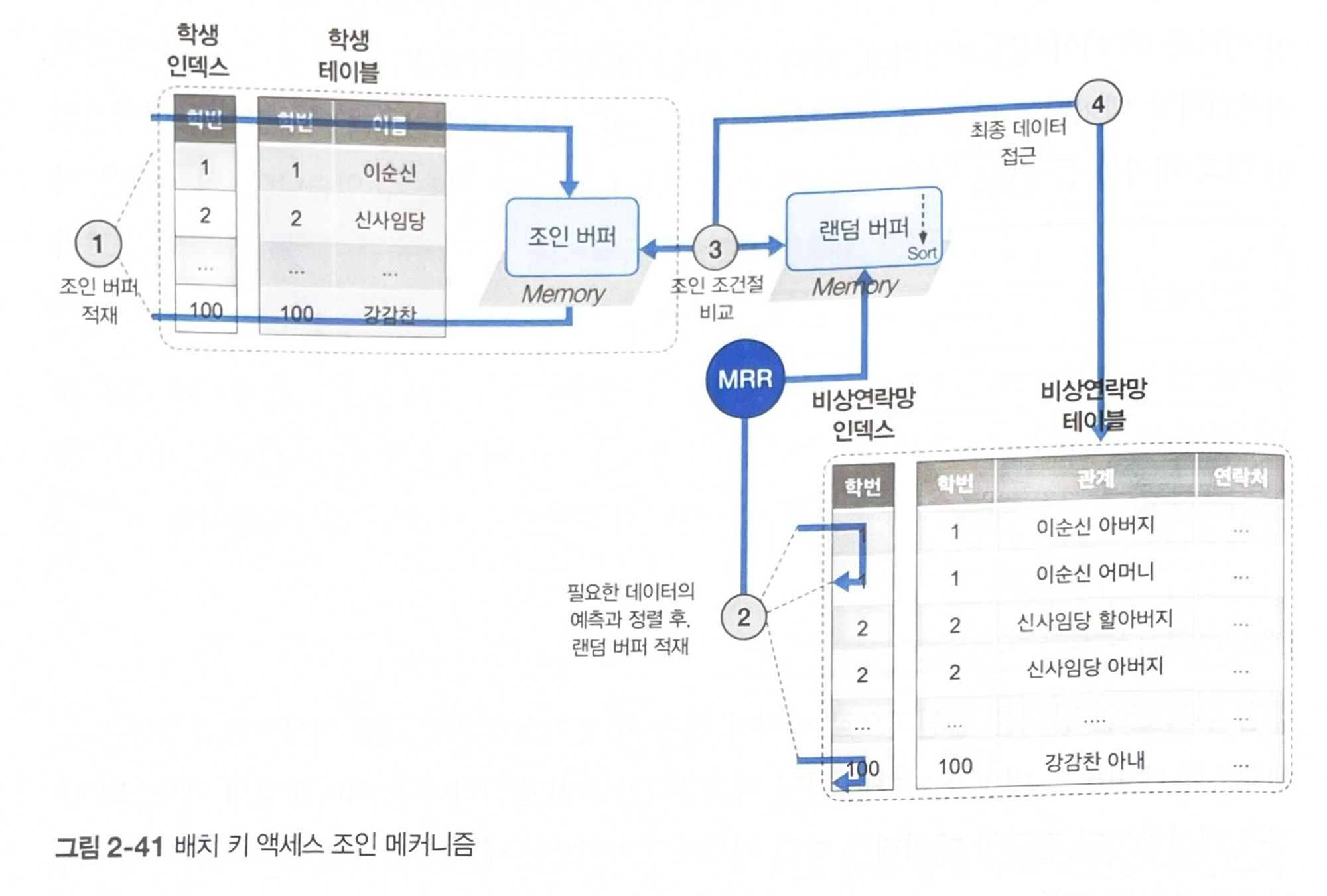
BNL 조인의 조인 버퍼 개념을 그대로 활용하며, 드리븐 테이블에 필요한 데이터를 미리 예측하고 정렬된 상태로 담는 랜덤 버퍼의 개념을 도입한다. 이때 드리븐 테이블의 데이터를 예측하고 정렬된 상태로 버퍼에 적재하는 기능을 다중 범위 읽기(multi range read, MRR)라고 한다. 즉, 미리 예측된 데이터를 가져와 정렬된 상태에서 랜덤 버퍼에 담기 때문에, 드리븐 테이블에 대해 랜덤 액세스가 아닌 시퀀셜 액세스를 수행하는 방식이다.
해시 조인
MySQL 8.0.18부터 지원하는 조인 방식이다. 조인에 참여하는 각 테이블의 데이터를 내부적으로 해시값으로 만들어 내부 조인을 수행한다. 해시값으로 내부 조인을 수행한 결과는 조인 버퍼에 저장되므로 조인열의 인덱스를 필수로 요구하지 않아도 된다.
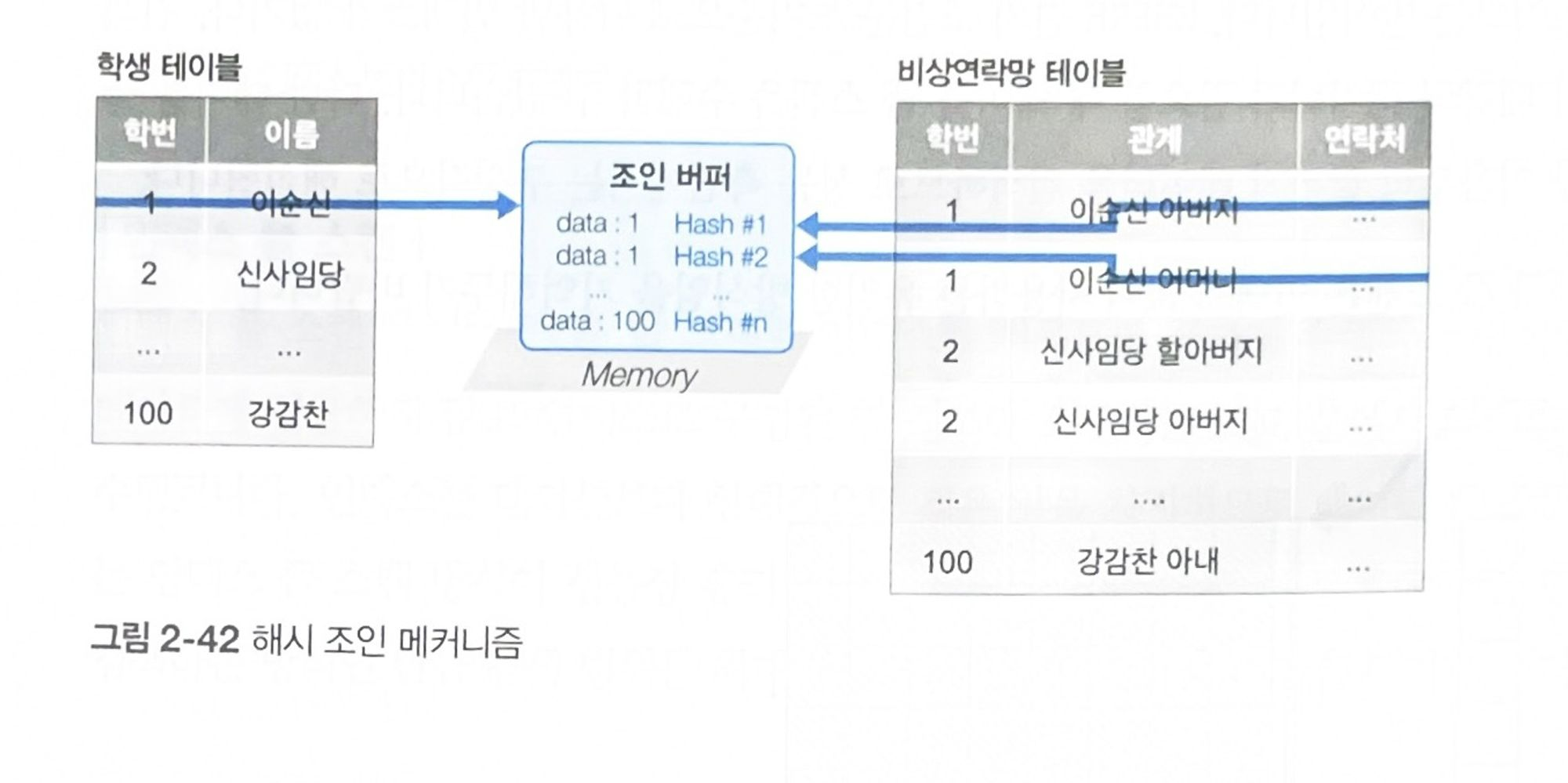
위 예시에서 학번 기반으로 만들어진 양 테이블 데이터의 해시값을 비교한 뒤 서로 동일한 경우에만 조인 버퍼에 저장된다.
참고
