
처음부터 모든 데이터를 가져오는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT 사원.사원번호,
급여.평균연봉,
급여.최고연봉,
급여.최저연봉
FROM 사원,
( SELECT 사원번호,
ROUND(AVG(연봉), 0) 평균연봉,
ROUND(MAX(연봉), 0) 최고연봉,
ROUND(MIN(연봉), 0) 최저연봉
FROM 급여
GROUP BY 사원번호
) 급여
WHERE 사원.사원번호 = 급여.사원번호
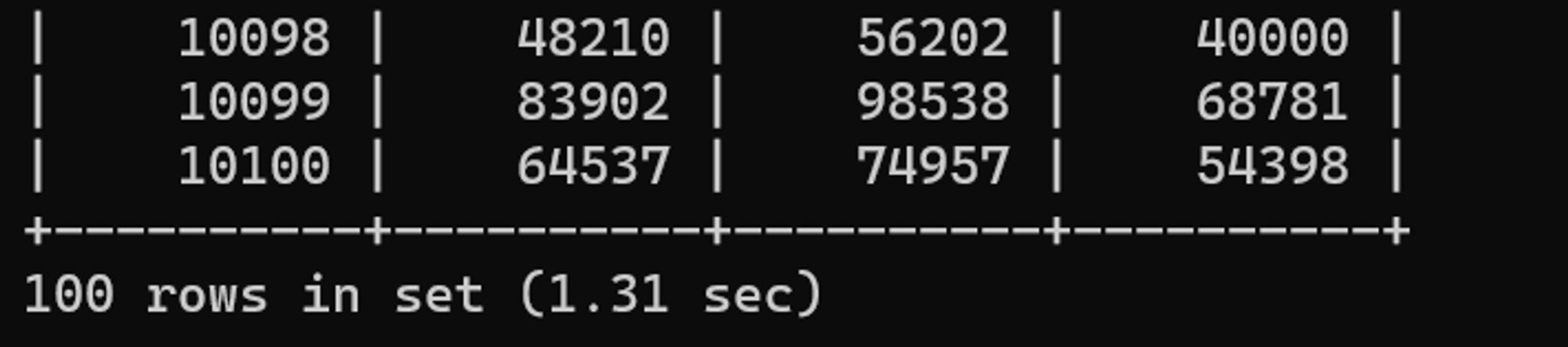
AND 사원.사원번호 BETWEEN 10001 AND 10100사원번호가 10001부터 10100번까지인 사람들의 평균연봉과 최고연봉, 최저연봉을 구하는 쿼리이다.
튜닝 전 수행결과
튜닝 전 실행계획
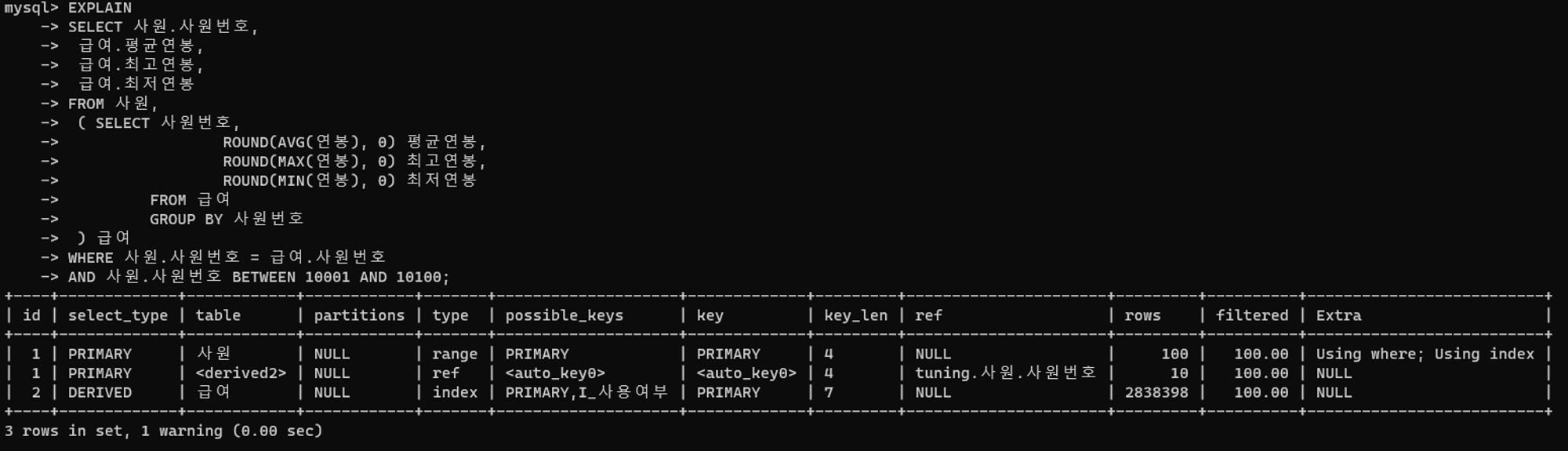
- 드라이빙 테이블은 사원, 드리븐 테이블은
<derived2>이다. <derived2>테이블은select_type항목이DERIVED로 작성된 세번쨰 행의 인라인 뷰를 가리키는 것으로,FROM절에서 급여 테이블로 수행한 그루핑 결과를 새로 생성한 임시 테이블의 메모리나 디스크에 올려놓는다.
튜닝 수행
type항목의index유형은 인덱스 풀 스캔을 수행하는 방식으로,FROM절의 급여 테이블을 그루핑하며 수행된다. 조건절 없이 그루핑을 수행하므로 지나치게 많은 데이터에 접근하지 않는지 의심해볼 수 있다.- 사원 테이블에서
BETWEEN구문으로 데이터에 접근하므로type항목의range유형을 통해 범위 스캔을 수행할 것임을 알 수 있다.

- 위 데이터 건수를 확인해보면 전체 데이터에 비해 조건절로 추출하는 데이터가 10건뿐임을 알 수 있다.
튜닝 결과
튜닝 후 SQL문
SELECT 사원.사원번호,
( SELECT ROUND(AVG(연봉), 0)
FROM 급여 AS 급여1
WHERE 사원번호 = 사원.사원번호
) AS 평균연봉,
( SELECT ROUND(MAX(연봉), 0)
FROM 급여 AS 급여2
WHERE 사원번호 = 사원.사원번호
) AS 최고연봉,
( SELECT ROUND(AVG(연봉), 0)
FROM 급여 AS 급여3
WHERE 사원번호 = 사원.사원번호
) AS 최저연봉
FROM 사원
WHERE 사원.사원번호 BETWEEN 10001 AND 10100- 전체 사원 데이터가 아닌 필요한 사원정보에만 접근한 뒤, 급여 테이블에서 각 사원번호별 평균연봉, 최고연봉, 최저연봉을 구한다.
WHERE절에서 추출하려는 사원 테이블의 데이터가 전체 데이터 대비 극히 소량이므로, 인덱스를 활용해 수행하는 3번의 스칼라 서브쿼리가 상대적으로 적은 리소스를 소모한다.
튜닝 후 수행결과
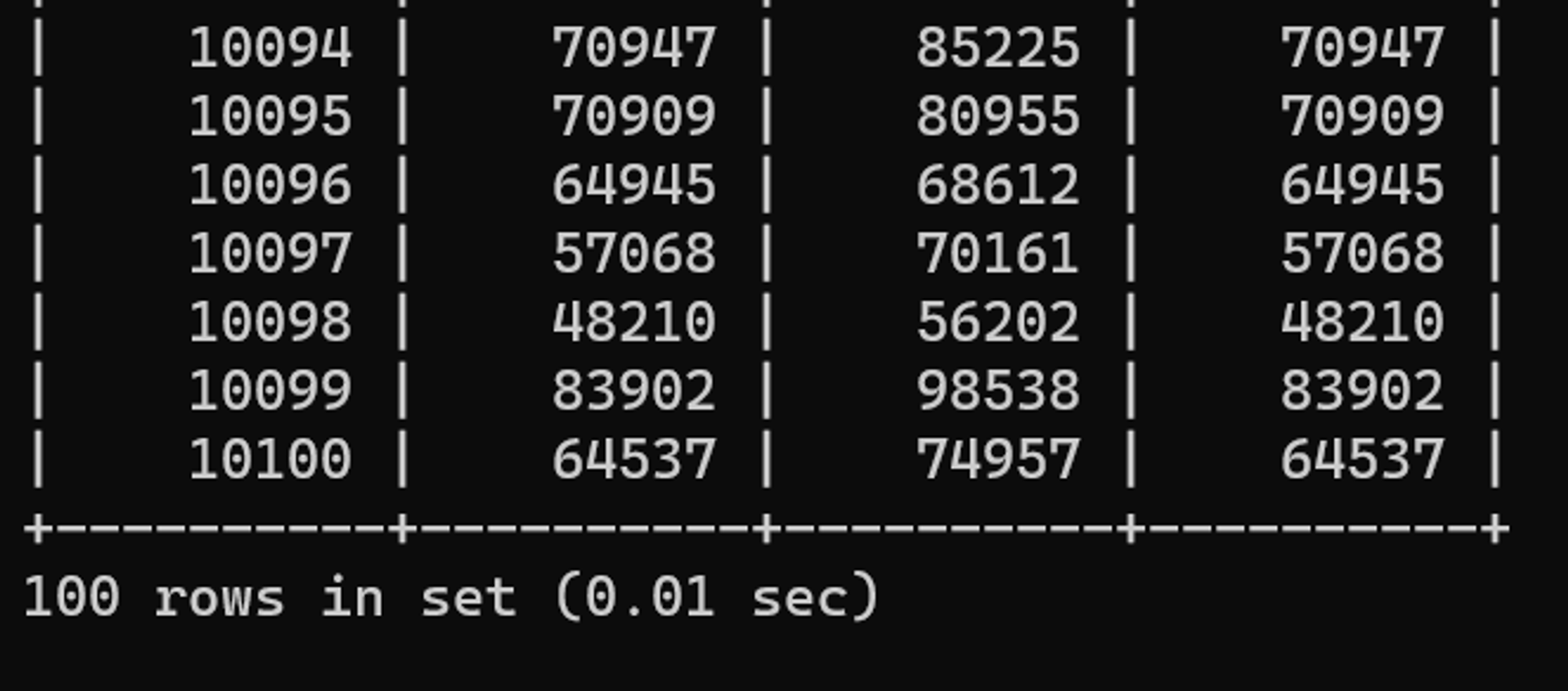
0.01초로 수행시간이 확연히 개선되었다.
튜닝 후 실행계획
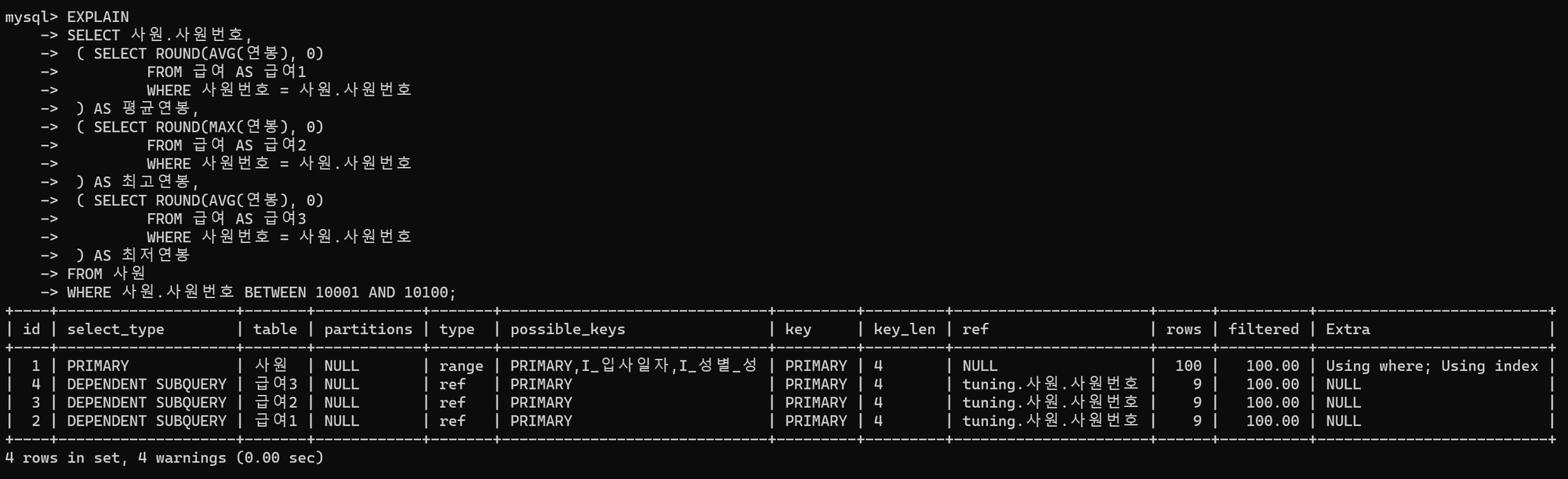
- 사원 테이블에 먼저 접근한 뒤, 급여1 → 급여2 → 급여3 순으로 접근한다.
- 사원 테이블의 사원번호를 스칼라 서브쿼리에서 매번 받아 사용한다.(
select_type : DEPENDENT SUBQUERY) 이는 반복 호출을 발생시켜 잦을 경우 지양해야 하는 형태이다. - 하지만 100건의 사원 데이터가 추출되는 기준에서는 3개의 스칼라 서브쿼리를 갖는 급여 테이블에 100번만 접근하므로, 성능 측면에서 비효율이 거의 없다.
비효율적인 페이징을 수행하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
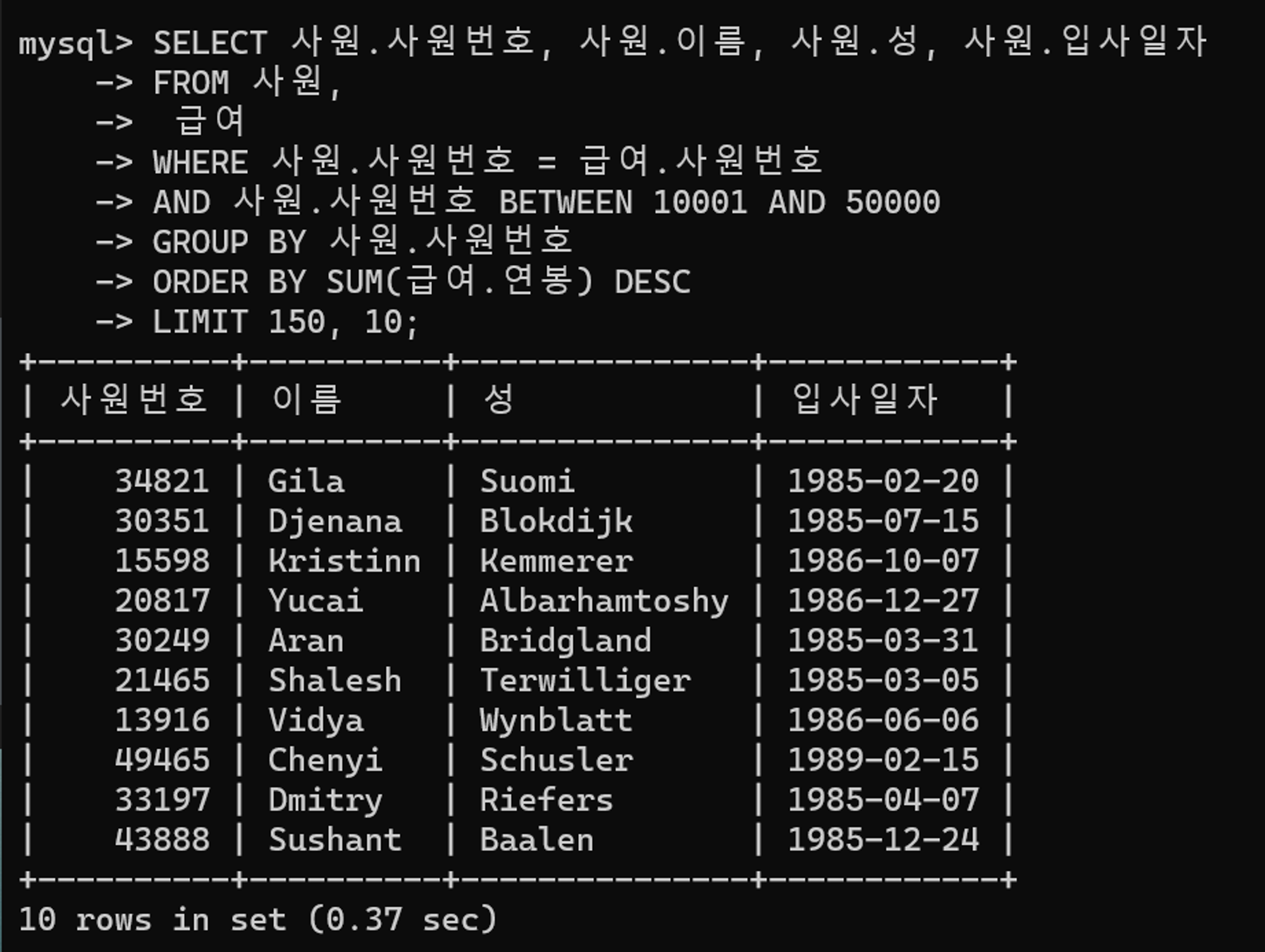
SELECT 사원.사원번호, 사원.이름, 사원.성, 사원.입사일자
FROM 사원,
급여
WHERE 사원.사원번호 = 급여.사원번호
AND 사원.사원번호 BETWEEN 10001 AND 50000
GROUP BY 사원.사원번호
ORDER BY SUM(급여.연봉) DESC
LIMIT 150, 10사원번호가 10,001번부터 50,000번 사이에 해당하는 데이터를 사원번호 기준으로 그루핑한 뒤 연봉 합계 기준으로 내림차순하는 쿼리이다. LIMIT 을 통해 150번째 데이터부터 10건의 데이터만 가져오도록 제어한다.
튜닝 전 수행결과
튜닝 전 실행계획

- 드라이빙 테이블인 사원과 드리븐 테이블인 급여가 조인한다.
- 사원, 급여 테이블은 각각 PK로 데이터에 접근한다.
- 드라이빙 테이블인 사원은 그루핑, 정렬 연산을 위해 임시 테이블(
extra : Using temporary)을 생성한 뒤 정렬 작업(extra : Using filesort)을 수행함을 알 수 있다.
튜닝 수행
10건의 데이터를 가져오기 위해 수십만 건의 데이터를 대상으로 조인을 수행한 뒤 그루핑, 정렬 작업을 수행한다. 이 방식이 효율적인지 고민해봐야 한다.
튜닝 결과
튜닝 후 SQL문
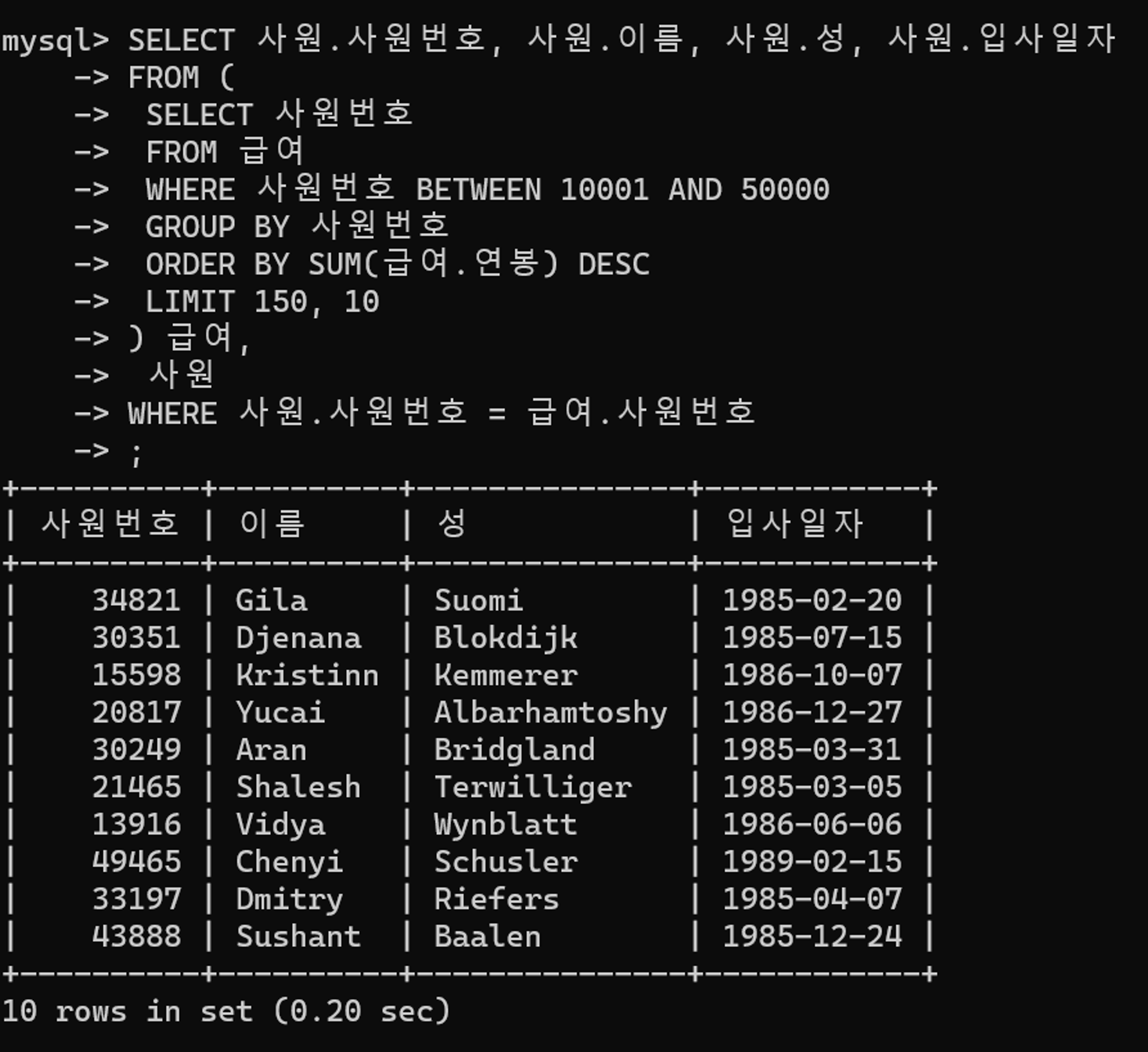
SELECT 사원.사원번호, 사원.이름, 사원.성, 사원.입사일자
FROM (
SELECT 사원번호
FROM 급여
WHERE 사원번호 BETWEEN 10001 AND 50000
GROUP BY 사원번호
ORDER BY SUM(급여.연봉) DESC
LIMIT 150, 10
) 급여,
사원
WHERE 사원.사원번호 = 급여.사원번호
- 급여 테이블의 그루핑, 정렬 작업은 인라인 뷰로 작성하였다.
- 인라인 뷰에 필요한 데이터 건수만큼
LIMIT로 제약을 설정하여 사원 테이블과 조회할 수 있는 데이터 건수를 줄일 수 있다.
튜닝 후 수행 결과
0.20초로 수행시간이 개선되었다.
튜닝 후 실행 계획
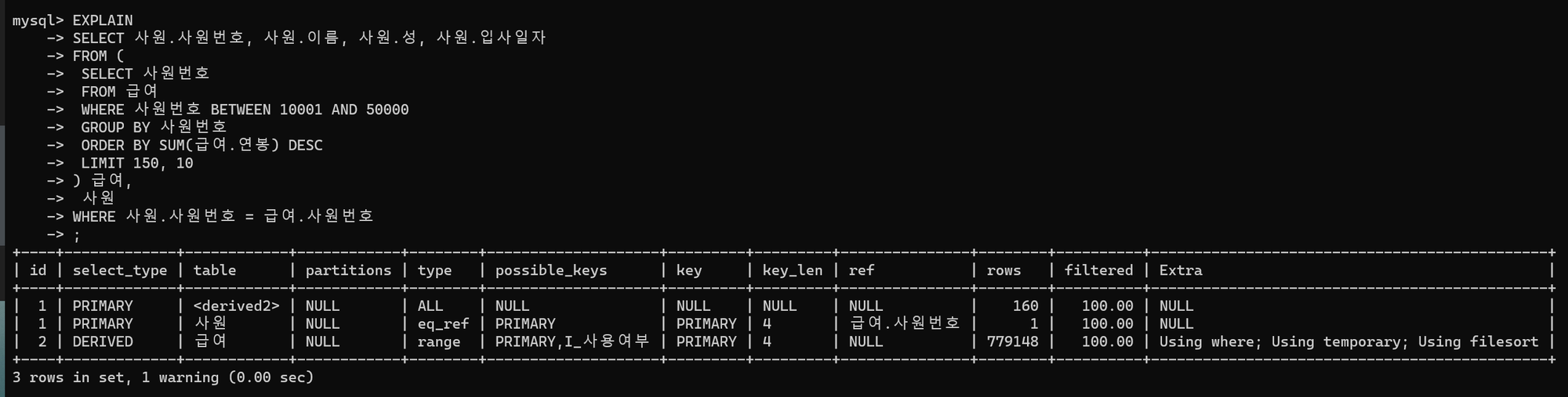
- 우선
<derived2>테이블과 사원 테이블을 대상으로 중첩 루프 조인을 수행한다. - 드라이빙 테이블인
<derived2>테이블은 id가 2인 급여 테이블이며, 드리븐 테이블은 사원 테이블이다. <derived2>테이블은WHERE절의 사원번호 범위 스캔을 수행하는 인라인 뷰로, 스토리지 엔진에서 가져온 데이터를 임시 테이블에 상주시켜 정렬 작업을 수행하게 된다.- 인라인 뷰인 급여 테이블을 기준으로 사원 테이블에 반복해 접근하고
WHERE절의사원.사원번호=급여.사원번호조건절로 조인을 수행한다. 이때 드라이빙 테이블은 테이블 풀 스캔한다. - 드리븐 테이블은 PK를 활용하여 데이터를 추출하며(
type : eq_ref), 중첩 루프 조인에 따라 PK를 매번 가져오므로rows항목에는 1개 데이터에만 접근한 것으로 출력된다.
필요 이상으로 많은 정보를 가져오는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
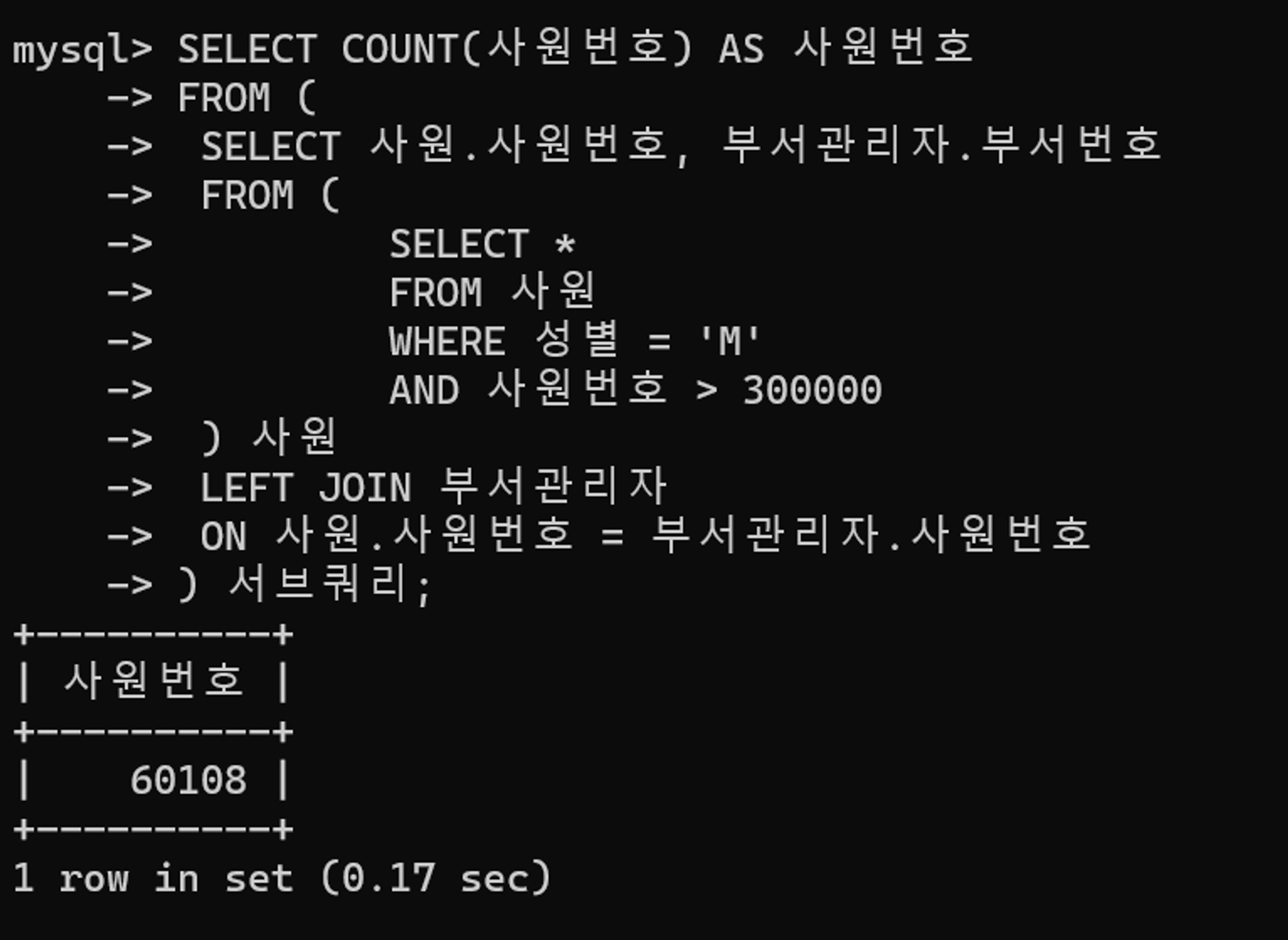
SELECT COUNT(사원번호) AS 사원번호
FROM (
SELECT 사원.사원번호, 부서관리자.부서번호
FROM (
SELECT *
FROM 사원
WHERE 성별 = 'M'
AND 사원번호 > 300000
) 사원
LEFT JOIN 부서관리자
ON 사원.사원번호 = 부서관리자.사원번호
) 서브쿼리사원 테이블에서 성별이 M이고 사원번호가 300,000을 초과하는 사원 대상으로 부서관리자 여부를 확인하는 쿼리이다.
튜닝 전 수행결과
튜닝 전 실행계획
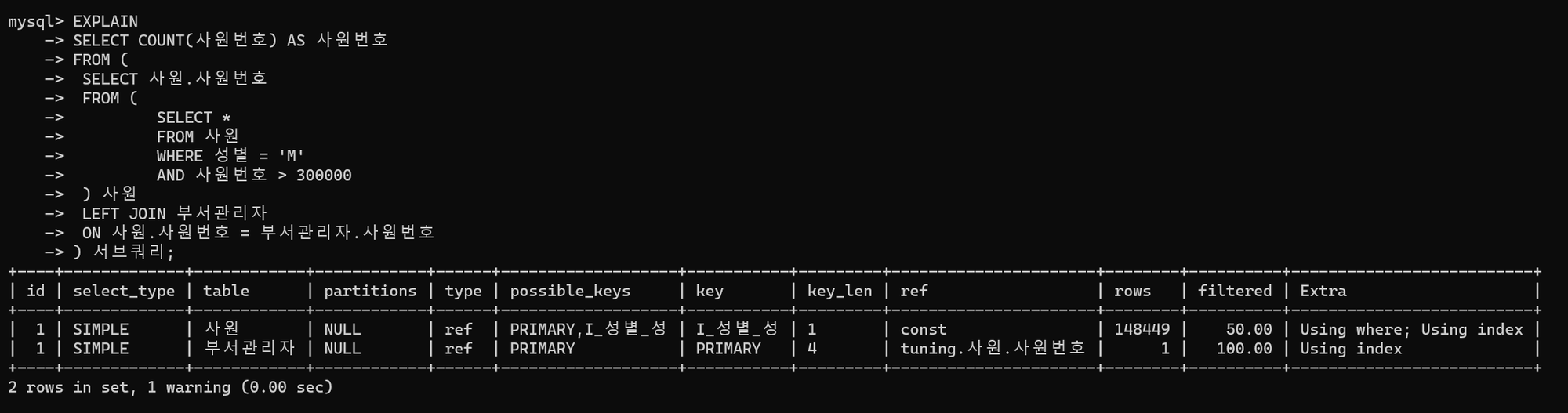
- 사원 테이블이 드라이빙 테이블이고 부서관리자 테이블이 드리븐 테이블이다.
- 사원 테이블엔 PK를 활용한 범위 스캔을 통해 데이터에 접근한다.
- 부서관리자 테이블은 외부 조인에 따라 PK를 활용하여 중첩 루프 조인시마다 1건의 데이터에 접근하는 것을 확인할 수 있다.
튜닝 수행
최종적으로 사원번호 데이터 건수를 집계한다는 사실은 알고 있다. 굳이 부서관리자 테이블과 외부 조인하는 조건이 필요한지 고민해봐야 한다.
튜닝 결과
튜닝 후 SQL문
SELECT COUNT(사원번호) AS 카운트
FROM 사원
WHERE 성별 = 'M'
AND 사원번호 > 300000최종적으로 필요한 사원번호의 건수를 구하는 과정에서 부서관리자 테이블은 필요치 않다. 따라서 사원 테이블의 데이터에만 접근토록 SQL문을 간소화한다.
튜닝 후 수행 결과
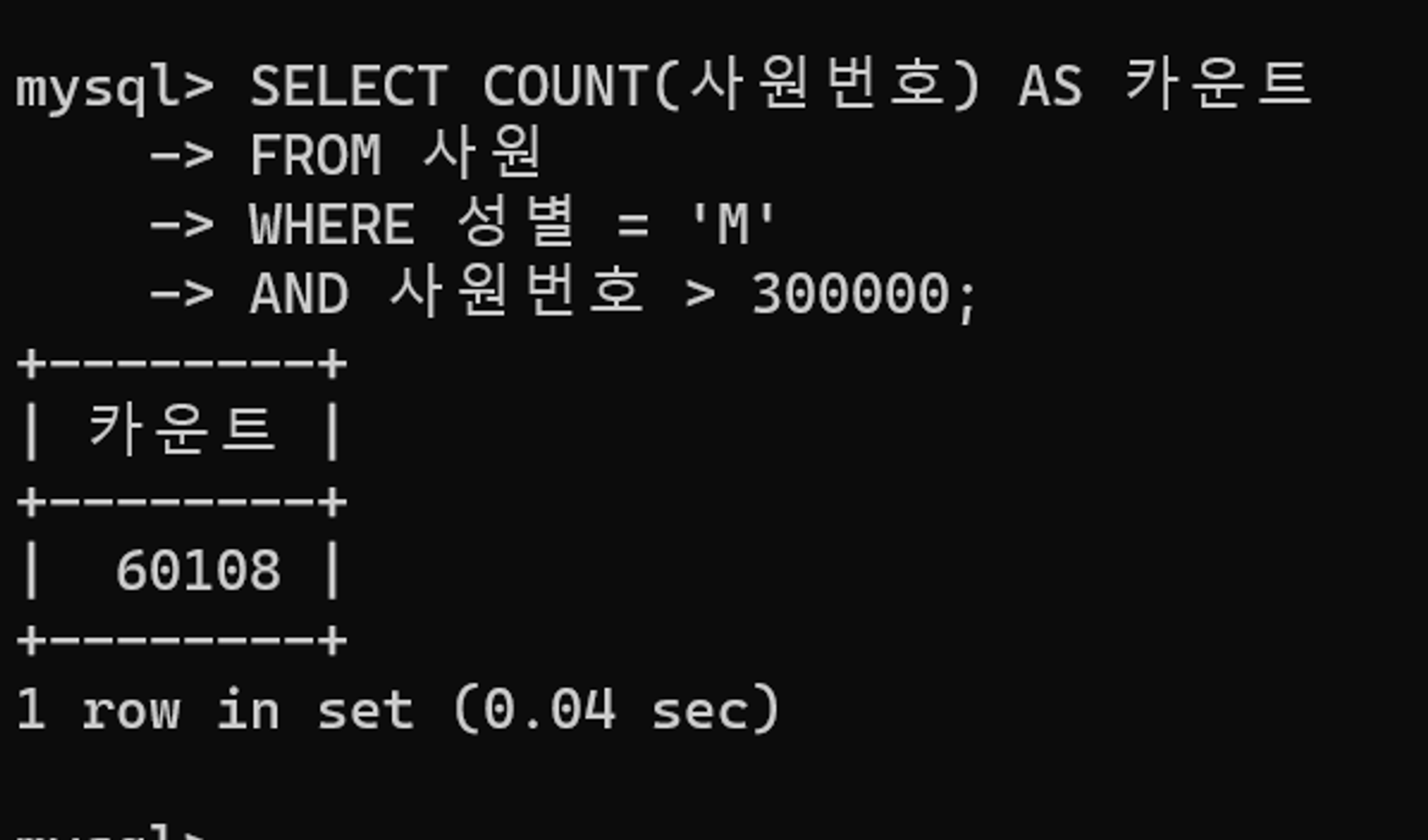
튜닝 후 실행 계획

불필요한 부서관리자 테이블로의 접근 작업이 제거되며 약 15만 건이었던 사원 테이블의 rows 항목이 5만 건으로 감소했음을 확인할 수 있다.
대량의 데이터를 가져와 조인하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT DISTINCT 매핑.부서번호
FROM 부서관리자 관리자,
부서사원_매핑 매핑
WHERE 관리자.부서번호 = 매핑.부서번호
ORDER BY 매핑.부서번호부서의 관리자가 소속된 부서번호를 조회하며 부서사원_매핑 테이블에도 있는 부서번호를 선택하는 쿼리이다.
튜닝 전 수행결과
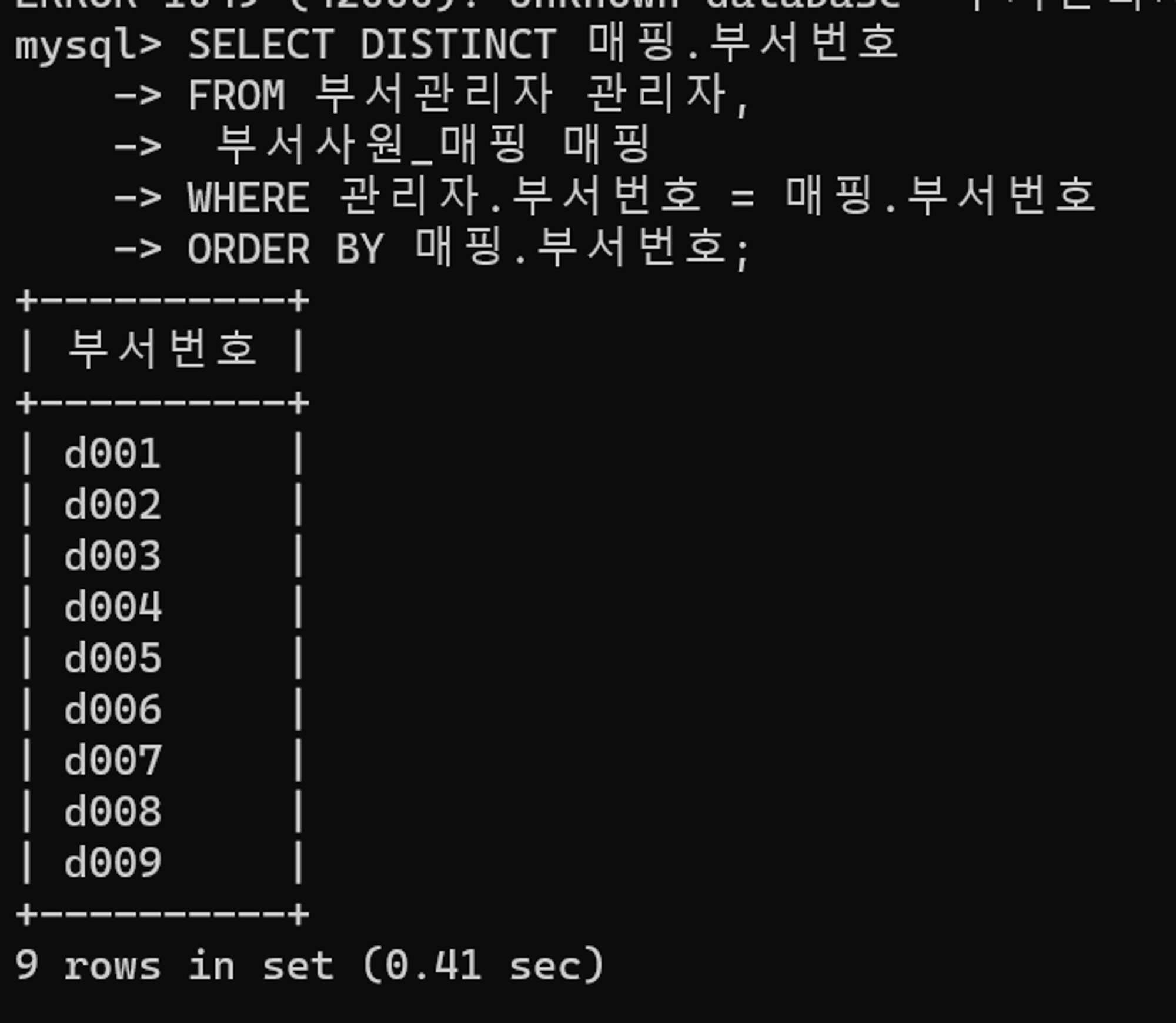
튜닝 전 실행계획

- 드라이빙 테이블은 부서사원_매핑, 드리븐 테이블은 부서관리자이다.
- 데이터에 먼저 접근하는 부서사원_매핑 테이블은 인덱스 풀 스캔 방식으로 데이터를 접근한다.
- 드리븐 테이블은 부서관리자 테이블은
관리자.부서번호=매핑.부서번호조건절로 데이터에 접근하고 중복을 제거하는DINSTINCT도 이떄 수행한다.
튜닝 수행
SELECT절을 살펴보면 중복이 제거된 부서번호 열만 조회하려는 사실을 알 수 있다.- 부서번호 열은 조인하려는 양 테이블에 모두 존재하므로 양 테이블의 어느 부서번호를 택하더라도 같은 결과를 도출하게 된다.
- 둘 중 한 테이블은 부서번호가 존재하는지 여부만 판단해도 충분하지 않을까? 또한 데이터를 조인하기 전에 미리 중복을 제거할 수 있는 방법은 없는지 고민해볼 필요도 있다.
튜닝 결과
튜닝 후 SQL문
SELECT 매핑.부서번호
FROM ( SELECT DISTINCT 부서번호
FROM 부서사원_매핑 매핑
) 매핑
WHERE EXISTS ( SELECT 1
FROM 부서관리자 관리자
WHERE 부서번호 = 매핑.부서번호)
ORDER BY 매핑.부서번호FROM절에서 매핑 테이블 데이터 조회시 부서번호 데이터 중복을 미리 제거한다.- 이후 부서관리_매핑 테이블의 데이터에 대해 부서관리자 테이블에서 같은 데이터가 있는지 여부만 판단한다.
- 굳이 부서관리자 테이블의 모든 데이터를 확인하지 않고 동일 부서번호가 있다면 더 접근을 수행하지 않는
EXISTS를 활용한 형태이다.
튜닝 후 수행 결과

0.00초로 수행시간이 확실히 개선되었다.
튜닝 후 실행 계획

<derived2>테이블은id가 2인 행의 인라인 뷰로,FROM절의DISTINCT작업까지 마친 매핑 테이블이다.DINSTINCT작업을 수행하고자I_부서번호인덱스로 정렬한 뒤에 중복을 제거하겠다는 의미로extra : Using Index for group-by가 표시되었다.- 즉, 드라이빙 테이블인 부서관리자 테이블은 전체 24개 데이터를 인덱스 풀 스캔으로 수행한 뒤에 드리븐 테이블인 중복 제거된 부서사원_매핑 테이블과 조인한다.
- 이때 부서관리자 테이블에
EXISTS연산자로 비교할 부서번호가 있다면 동일한 부서번호 데이터는 확인하지 않고 건너뛰므로extra : LooseScan으로 표시된다. rows항목을 보면 부서사원_매핑 테이블에 접근하는 데이터 건수가 한 자릿수로 줄었음을 확인할 수 있다.
