
인덱스 없이 작은 규모의 데이터를 조회하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT *
FROM 사원
WHERE 이름 = 'Georgi'
AND 성 = 'Wielonsky';튜닝 전 수행 결과
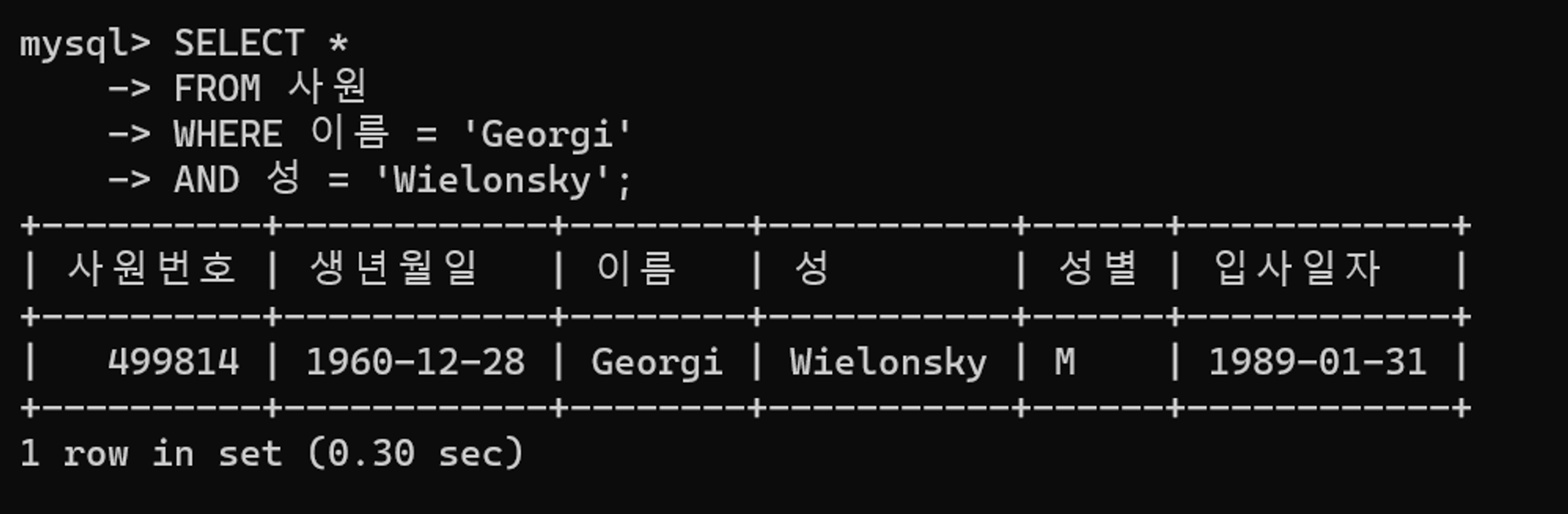
튜닝 전 실행 계획
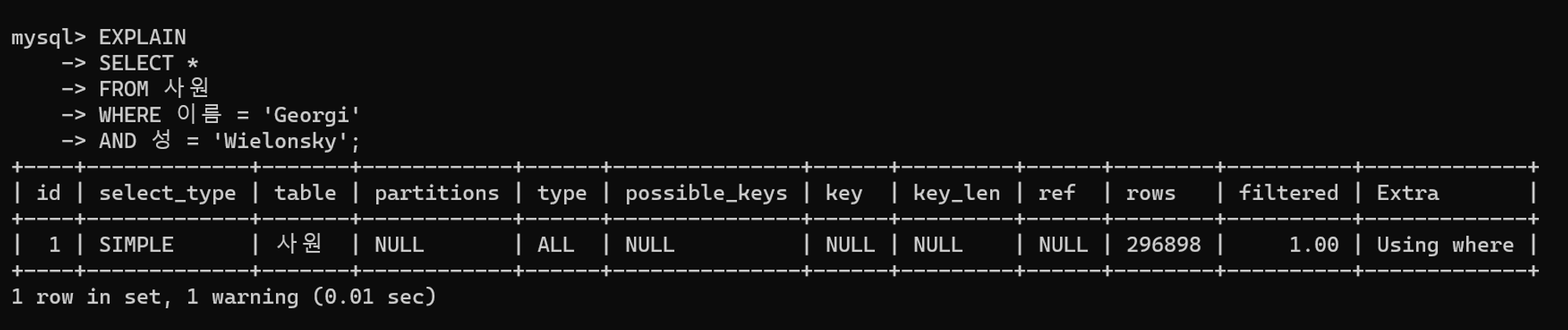
테이블 풀 스캔을 통해 주어진 쿼리를 수행한다.
튜닝 수행
단 1건의 데이터를 조회하기 위해 테이블 풀 스캔을 수행하는 것은 비효율적이다. 조건절에 해당하는 열들이 자주 호출된다면, 인덱스로 빠른 데이터 접근을 유도하는 식으로 튜닝이 가능하다.
이름, 성 칼럼을 대상으로 인덱스를 생성하기 전에 더 다양한 값이 있는 칼럼을 파악한다. 아래 결과에서 데이터 범위를 더 축소할 수 있는 성 칼럼을 선두 칼럼으로 삼아 인덱스를 생성해보자.
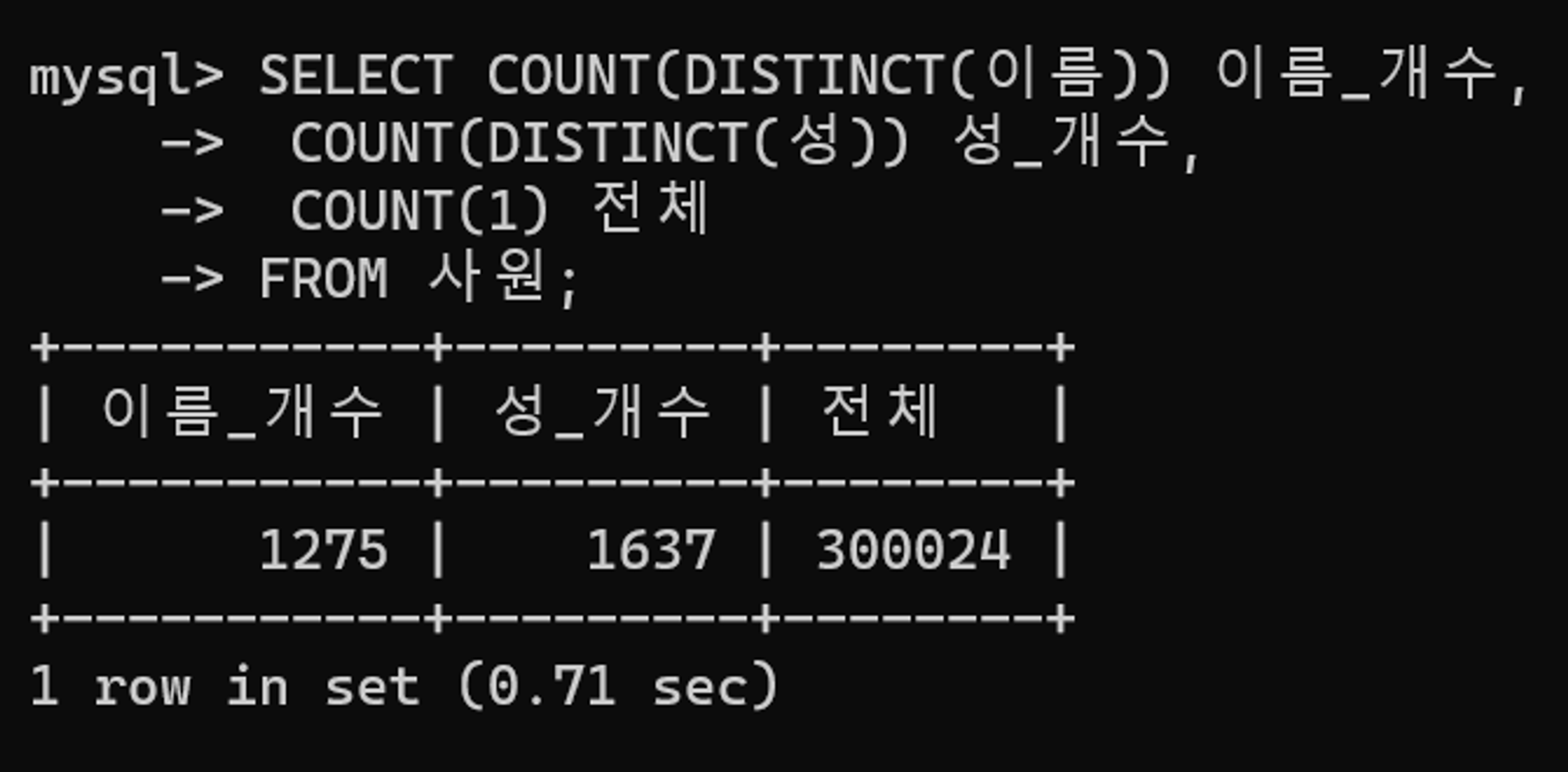
아래 명령을 통해 사원 테이블에 I_사원_성_이름 인덱스를 생성한다.
ALTER TABLE 사원
ADD INDEX I_사원_성_이름 (성,이름);튜닝 결과
튜닝 후 SQL문
튜닝 전 SQL문과 동일하다. 신규 인덱스가 SQL문의 성능을 높혀준다.
튜닝 후 수행 결과
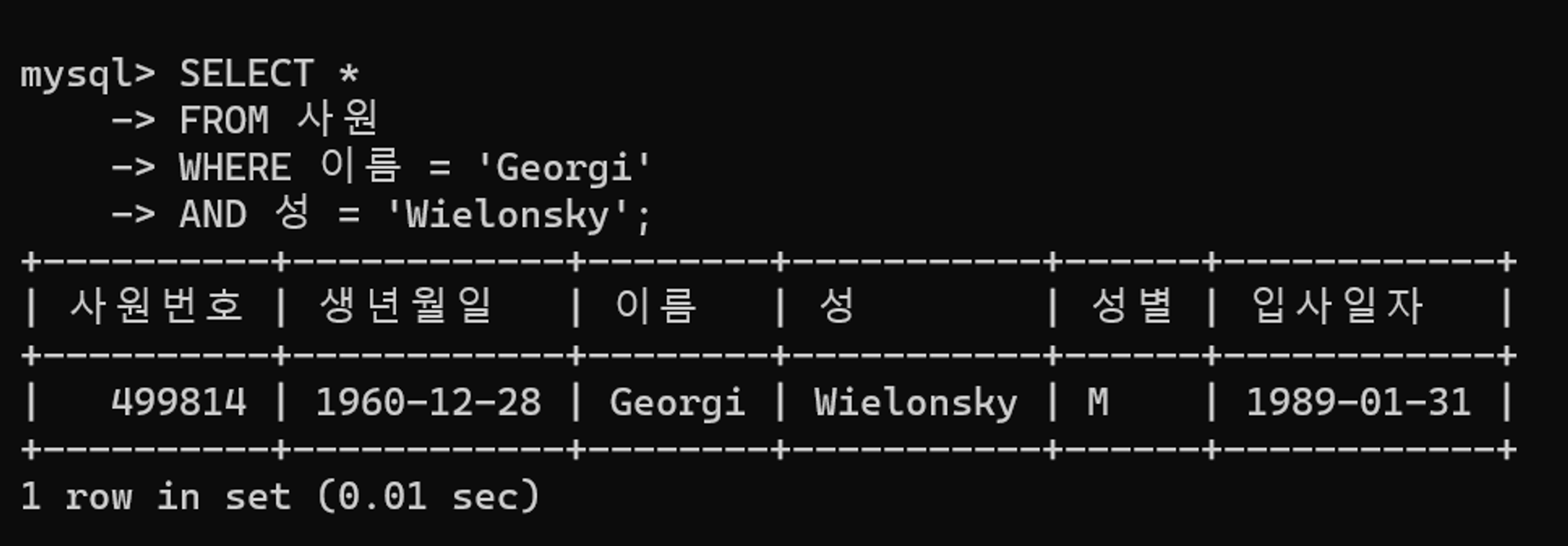
0.01초로 수행시간이 개선되었다.
튜닝 후 실행 계획

인덱스 스캔을 통해 데이터를 조회하는 것을 확인할 수 있다.
인덱스를 하나만 사용하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT *
FROM 사원
WHERE 이름 = 'Matt'
OR 입사일자 = '1987-03-31';튜닝 전 수행 결과
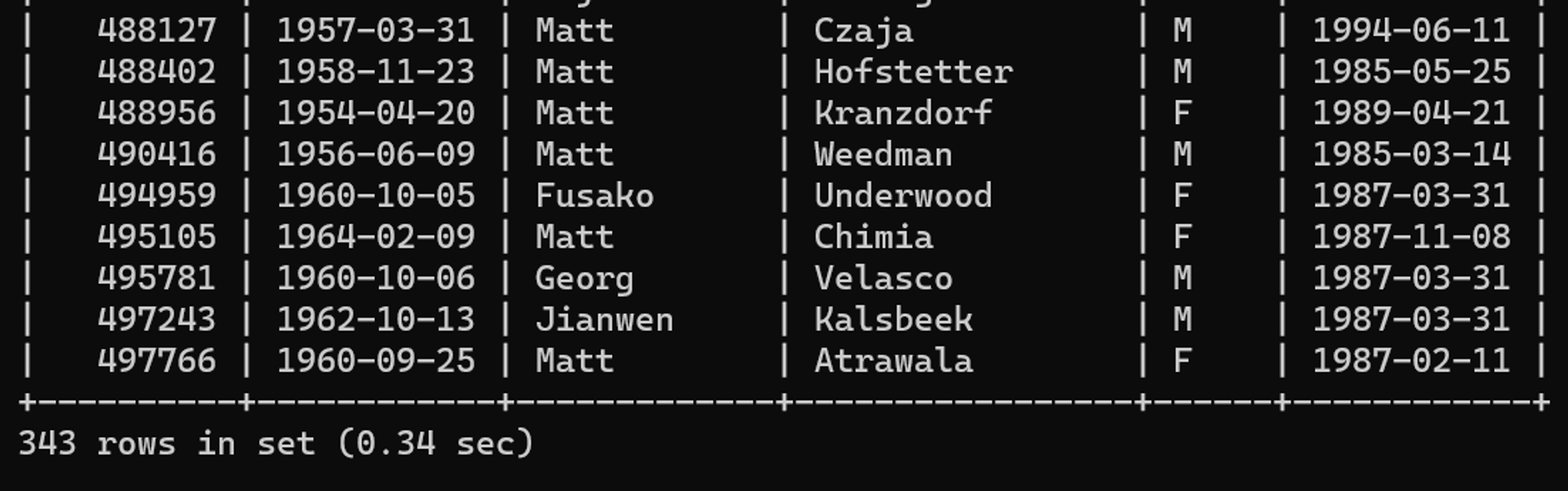
튜닝 전 실행 계획
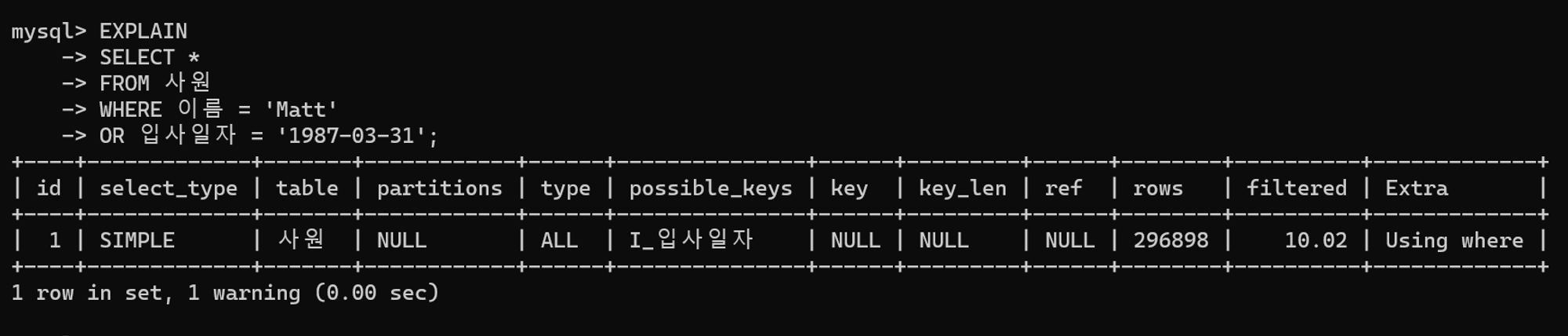
테이블 풀 스캔을 통해 쿼리를 수행함을 확인할 수 있다.
튜닝 수행
조건절에 해당하는 데이터 분포를 확인해보자. 전체 데이터 건수에 비해 조건절을 통해 조회하는 데이터 건수가 현저히 적은 것을 확인할 수 있다.
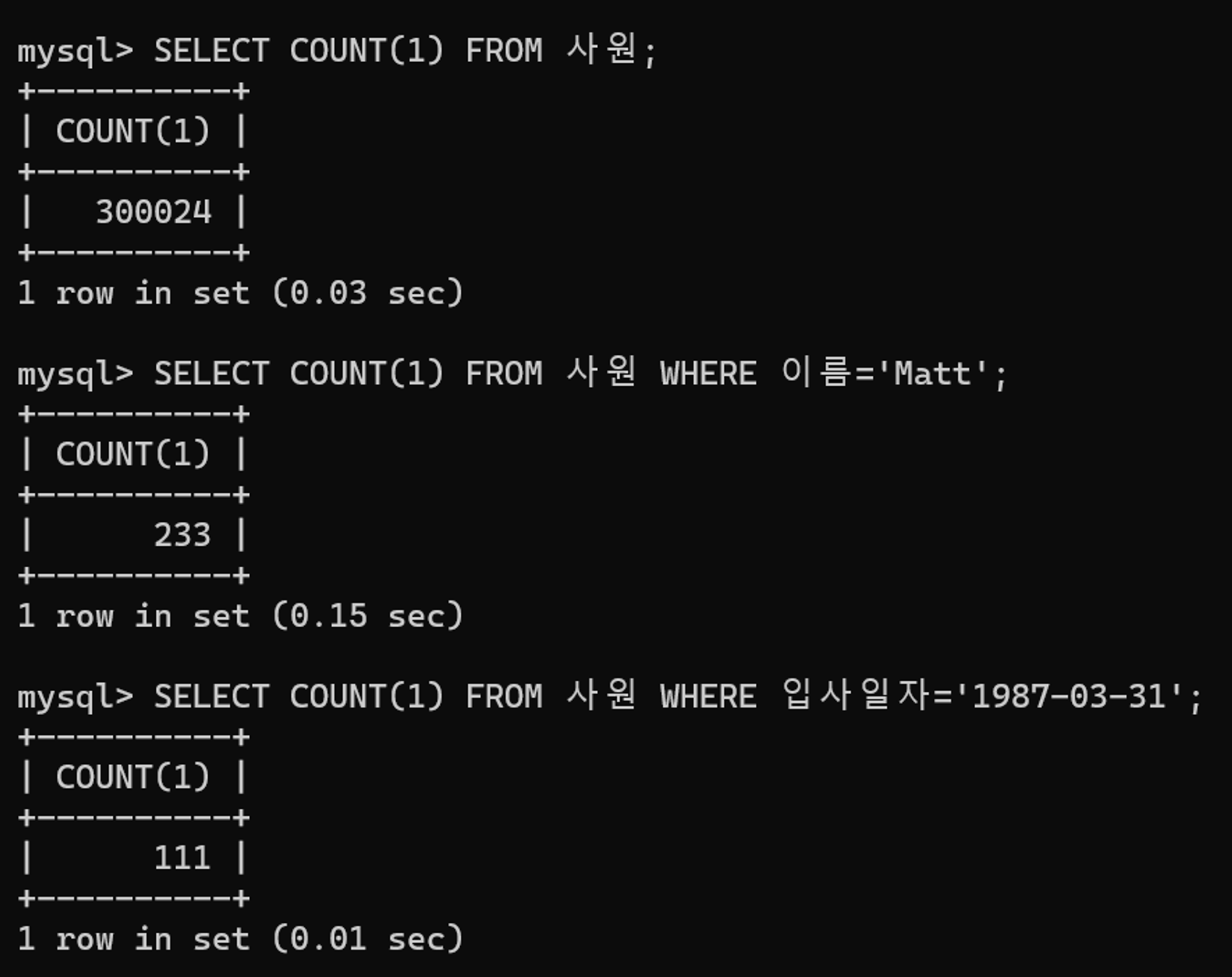
이처럼 소량의 데이터를 가져올 때는 인덱스 스캔이 더 효율적이다. 조건절 칼럼이 포함된 인덱스가 존재하는지 확인해보면, 입사일자 인덱스는 존재하나 이름 칼럼이 포함된 인덱스는 없다.

이름 열에 대한 인덱스를 생성하여 조건절의 각 칼럼이 인덱스 스캔을 통해 쿼리를 수행하도록 튜닝해보자.
ALTER TABLE 사원
ADD INDEX I_이름(이름);튜닝 결과
튜닝 후 SQL문
SQL문 자체에는 변경 사항이 없다.
튜닝 후 수행 결과
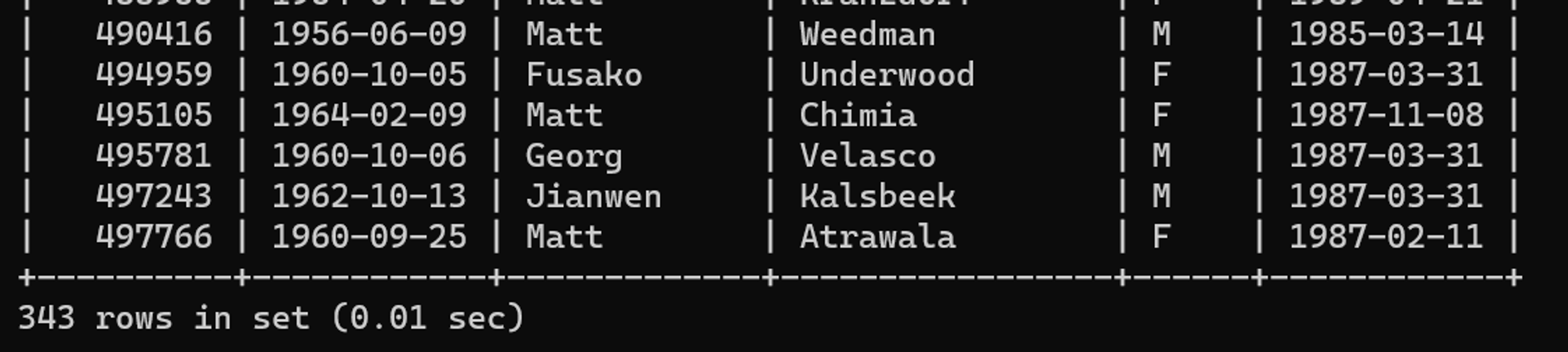
0.01초로 수행 시간이 개선되었다.
튜닝 후 실행 계획

2개의 조건절 칼럼이 각각 인덱스 스캔으로 수행되고 각 결과는 병합된다. 만약 WHERE ~ OR 구문에서 한쪽의 조건절이 동등 조건이 아닌 범위 조건이라면 index_merge 로 처리하지 않을 수 있다. 버전에 따라 내부 메커니즘에 차이가 있어 실행 계획을 확인한 뒤 UNION 이나 UNION ALL 구문 등으로 분리하는 걸 고려해야 한다.
큰 규모의 데이터 변경으로 인덱스에 영향을 주는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
UPDATE 사원출입기록
SET 출입문 = 'X'
WHERE 출입문 = 'B';튜닝 전 실행 결과
MySQL에서 DML을 수행할 때 기본적으로 커밋은 자동 저장된다. 아래 명령을 통해 자동 커밋 옵션을 확인해볼 수 있다. autocommit 이 1이면 자동 커밋이다. 예제를 수행하기 위해 자동 커밋을 우선 해제해둔다.
select @autocommit;
set autocommit=0; -- 자동 커밋 해제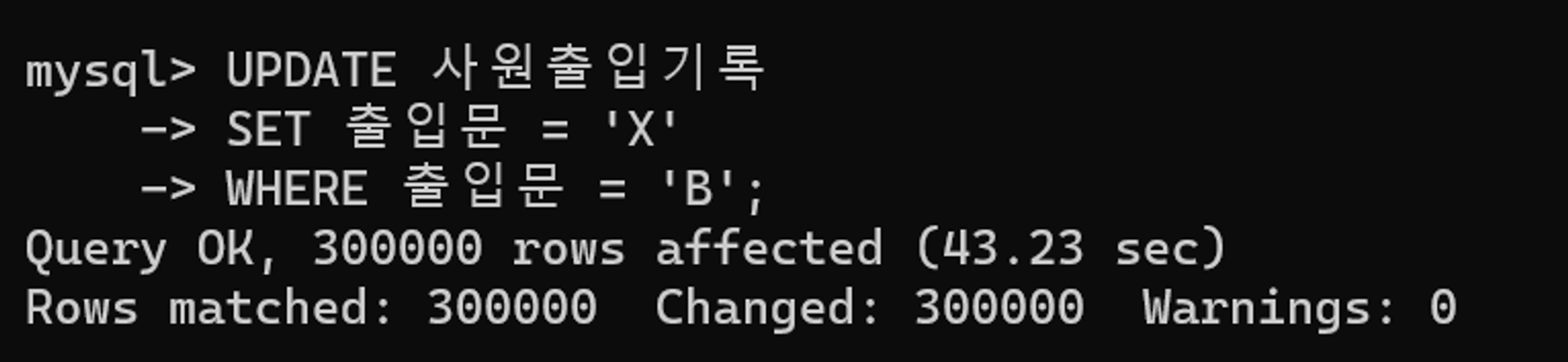
수행 결과를 보면 30만 건의 데이터가 변경되었고 43초가 소요되었다. 쿼리 튜닝후 UPDATE 쿼리를 반복 실행해야 하므로 롤백해준다.
튜닝 수행
UPDATE 문은 수정할 데이터에 접근한 뒤에 수정을 시행하므로, 인덱스로 데이터를 접근한다는 측면에서 이 경우에도 인덱스의 존재 여부가 중요하다. 한편, 조회 데이터를 변경하는 범위에는 인덱스도 포함되므로, 인덱스가 많은 테이블의 데이터를 변경할 때는 성능적으로 불리하다.
튜닝 전 UPDATE 문에 포함된 테이블의 인덱스 목록을 살펴보자.

예제 쿼리는 출입문 칼럼을 포함하므로 I_출입문 인덱스의 튜닝 여부를 고민해봐야 한다. 사원출입기록과 같은 이력용 테이블에서는 보통 지속적인 데이터 저장만 이루어지므로, 애플리케이션을 통한 I_출입문 인덱스의 활용이 적다면 삭제하여 튜닝할 것을 고려할 수 있다.
만약 업데이트 작업이 서비스에 대한 영향이 적은 시간대에 수행되는 배치성 작업이라면 일시적으로 인덱스를 삭제한 뒤 대량 업데이트 작업을 수행하고 다시 생성하는 방식으로 SQL문 효율을 높일 수 있다.
ALTER TABLE 사원출입기록
DROP INDEX I_출입문;
SHOW INDEX FROM 사원출입기록; -- 인덱스 목록 확인튜닝 결과
튜닝 후 SQL문
SQL문 자체의 변경 사항은 없다.
튜닝 후 수행 결과
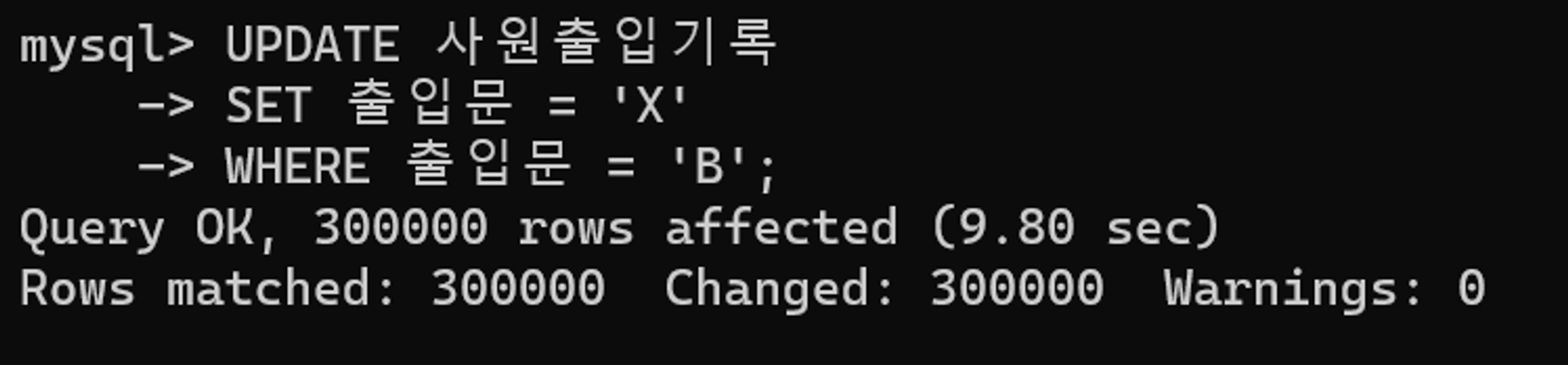
9.8초로 수행 시간이 확실히 개선되었다.
튜닝 후 실행 계획

인덱스 삭제 이후 PK로 데이터에 접근하여 변경하는 것을 확인할 수 있다.
비효율적인 인덱스를 사용하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
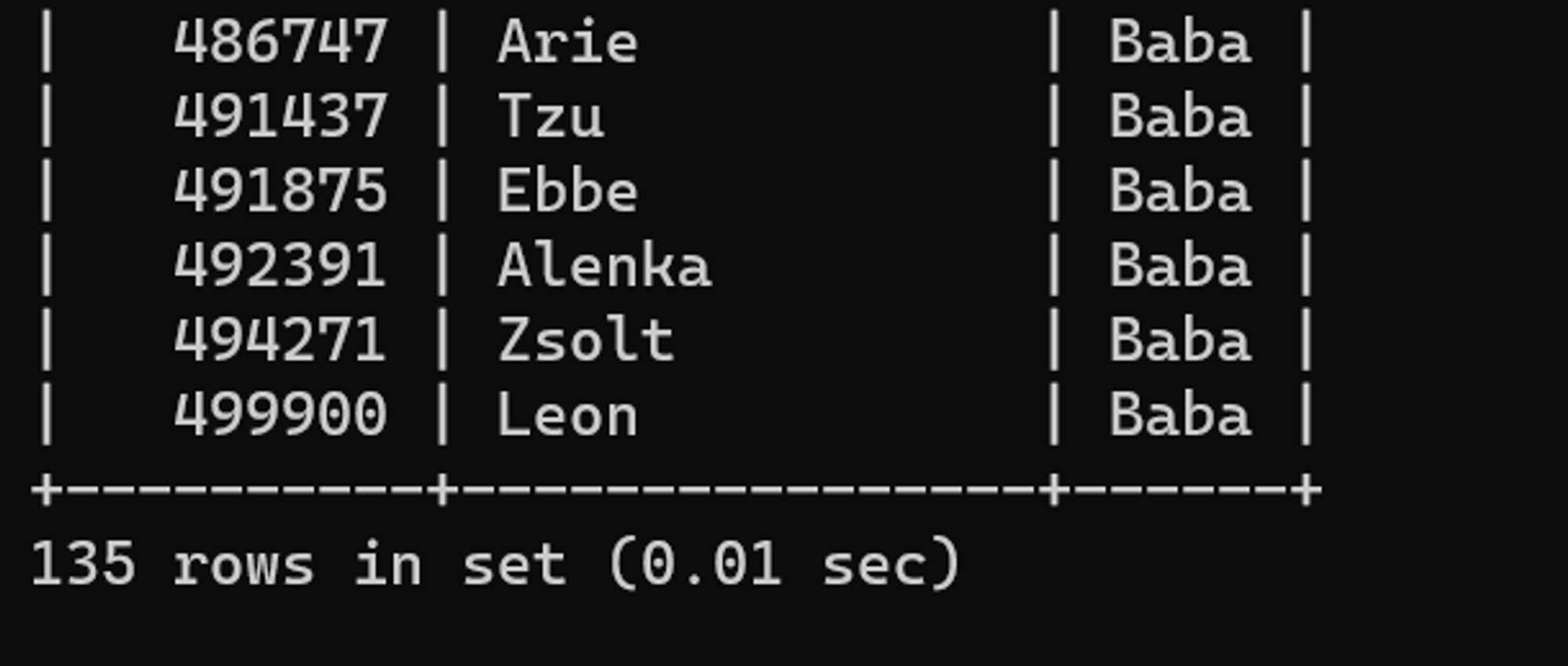
SELECT 사원번호, 이름, 성
FROM 사원
WHERE 성별 = 'M'
AND 성 = 'Baba'튜닝 전 수행 결과
튜닝 전 실행 계획
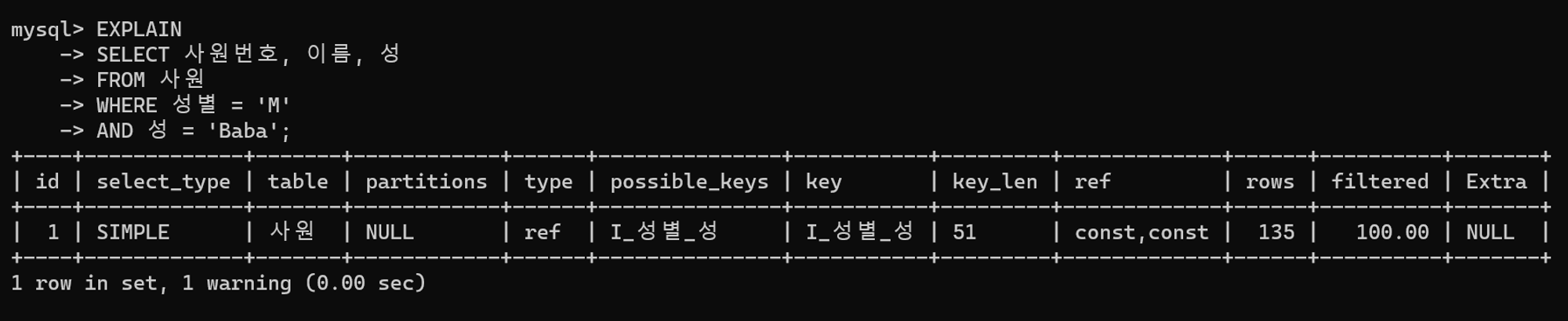
I_성별_성 인덱스를 활용하여 사원 테이블에 접근한다. 고정된 값으로 조건절을 작성하여, 스토리지 엔진에서 인덱스 스캔으로 원하는 데이터를 가져온다.
튜닝 수행
조건절에 작성된 칼럼 현황을 확인해보자.
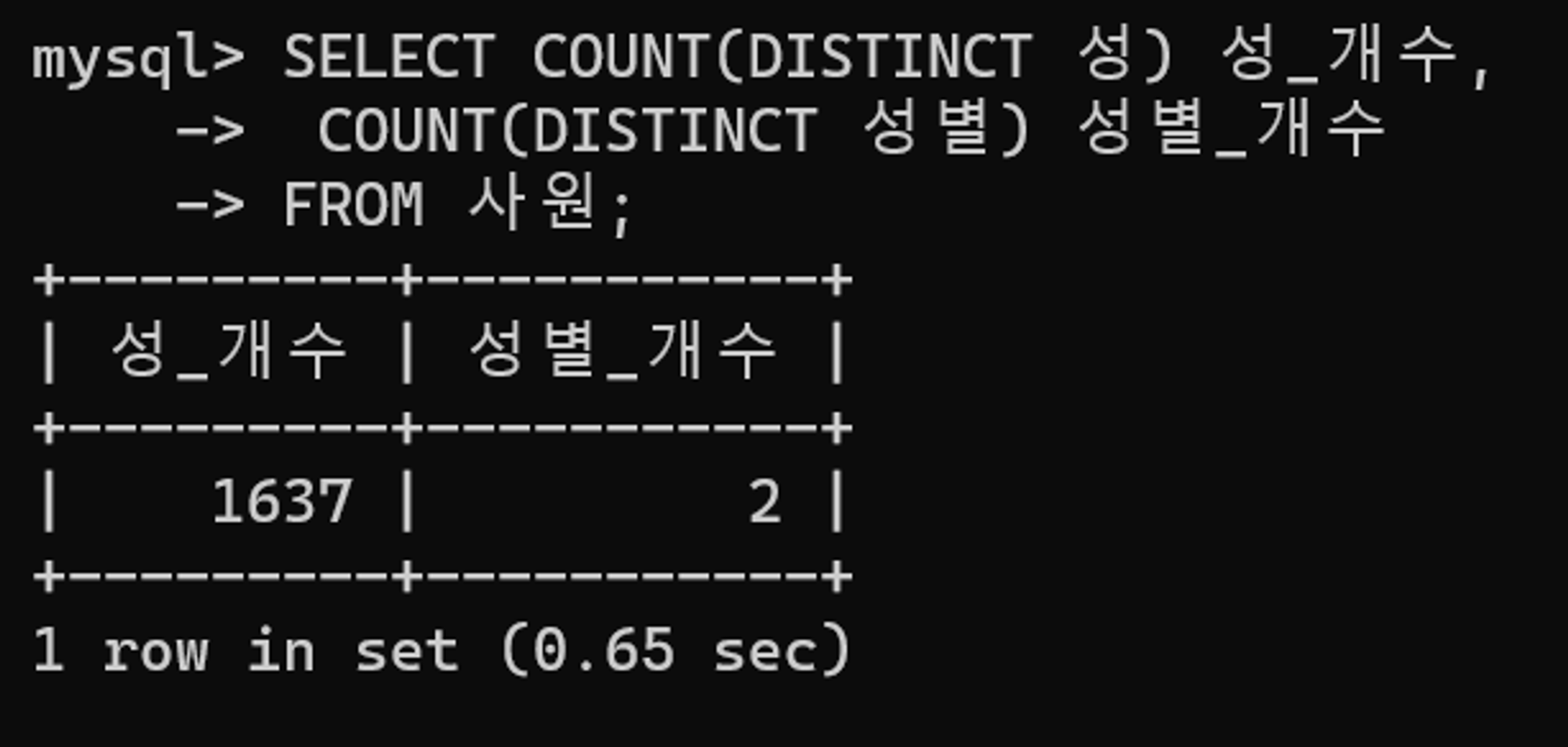
성 칼럼의 데이터에 비해 성별 칼럼의 데이터는 2건에 불과하다. 사원 테이블의 인덱스 목록을 보면 성별+성 순으로 구성된 I_성별_성 인덱스가 보이고 이것이 예제에서 활용되었다. 하지만 데이터가 다양하지 않은 성별을 선두로 구성한 인덱스가 과연 효율적일까? 접근 범위를 줄이기 위해 기존 인덱스를 성+성별 순서의 I_성_성별 인덱스로 변경하자.
ALTER TABLE 사원
DROP INDEX I_성별_성,
ADD INDEX I_성_성별(성, 성별);튜닝 결과
튜닝 후 SQL문
SQL문 자체는 변경이 없다.
튜닝 후 수행 결과
튜닝 후 실행 계획
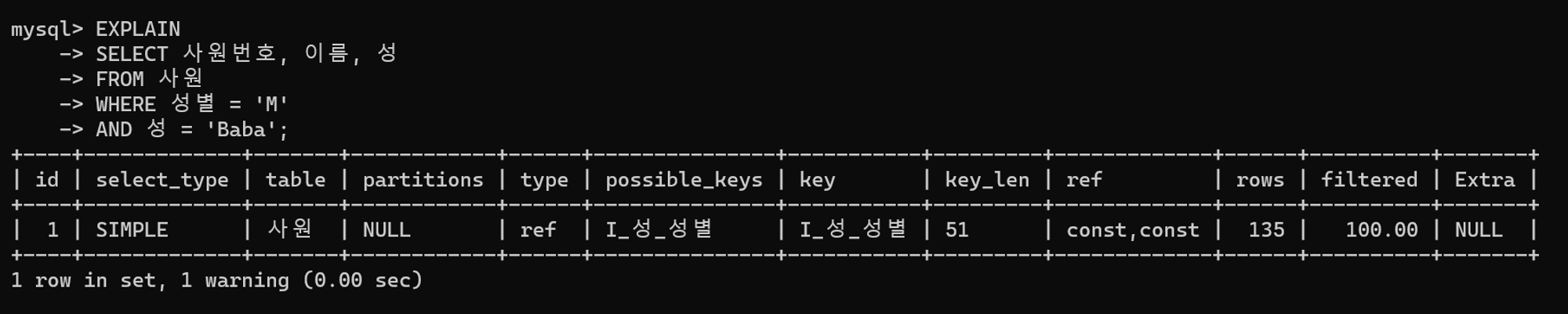
튜닝 전과 크게 다르지 않다. 단, 더 효율적으로 구성된 인덱스를 사용하게 된다.
