
잘못된 열 속성 설정으로 비효율적으로 작성한 나쁜 SQL문
현황 분석
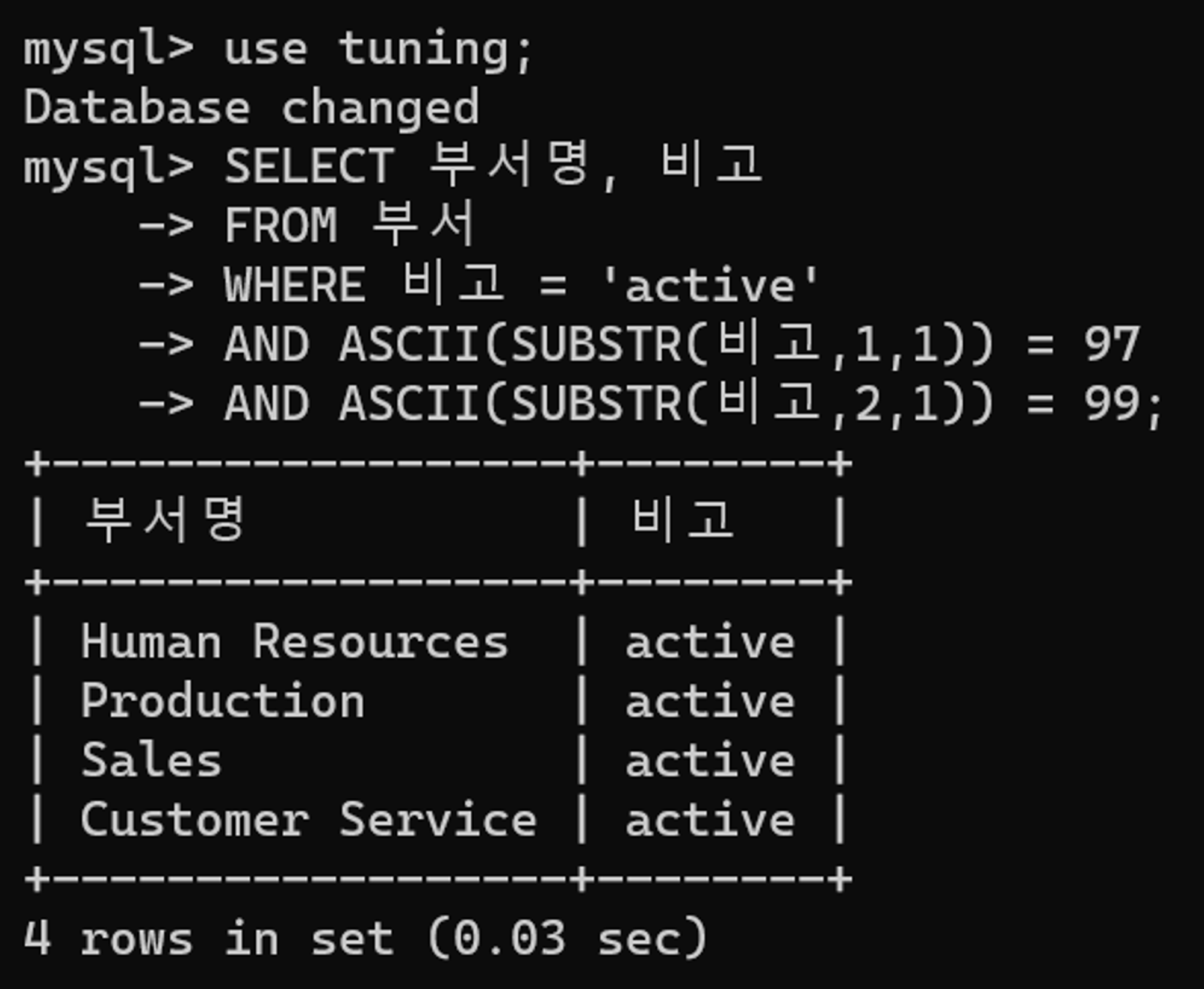
튜닝 전 SQL문
SELECT 부서명, 비고
FROM 부서
WHERE 비고 = 'active'
AND ASCII(SUBSTR(비고,1,1)) = 97
AND ASCII(SUBSTR(비고,2,1)) = 99부서 테이블에서 비고 칼럼의 값이 active 인 데이터들을 추출하는 쿼리이다. 비고 값의 첫 문자가 아스키 코드 97(a), 두번째 문자가 아스키 코드 99(c)일 떄만 결과를 구한다.
튜닝 전 수행 결과
튜닝 수행
분석을 위해 두 개의 조건절을 나누어 실행해보자.

첫 조건절을 실행해보면 대소문자가 섞인 상태로 총 7건의 데이터가 출력된다.
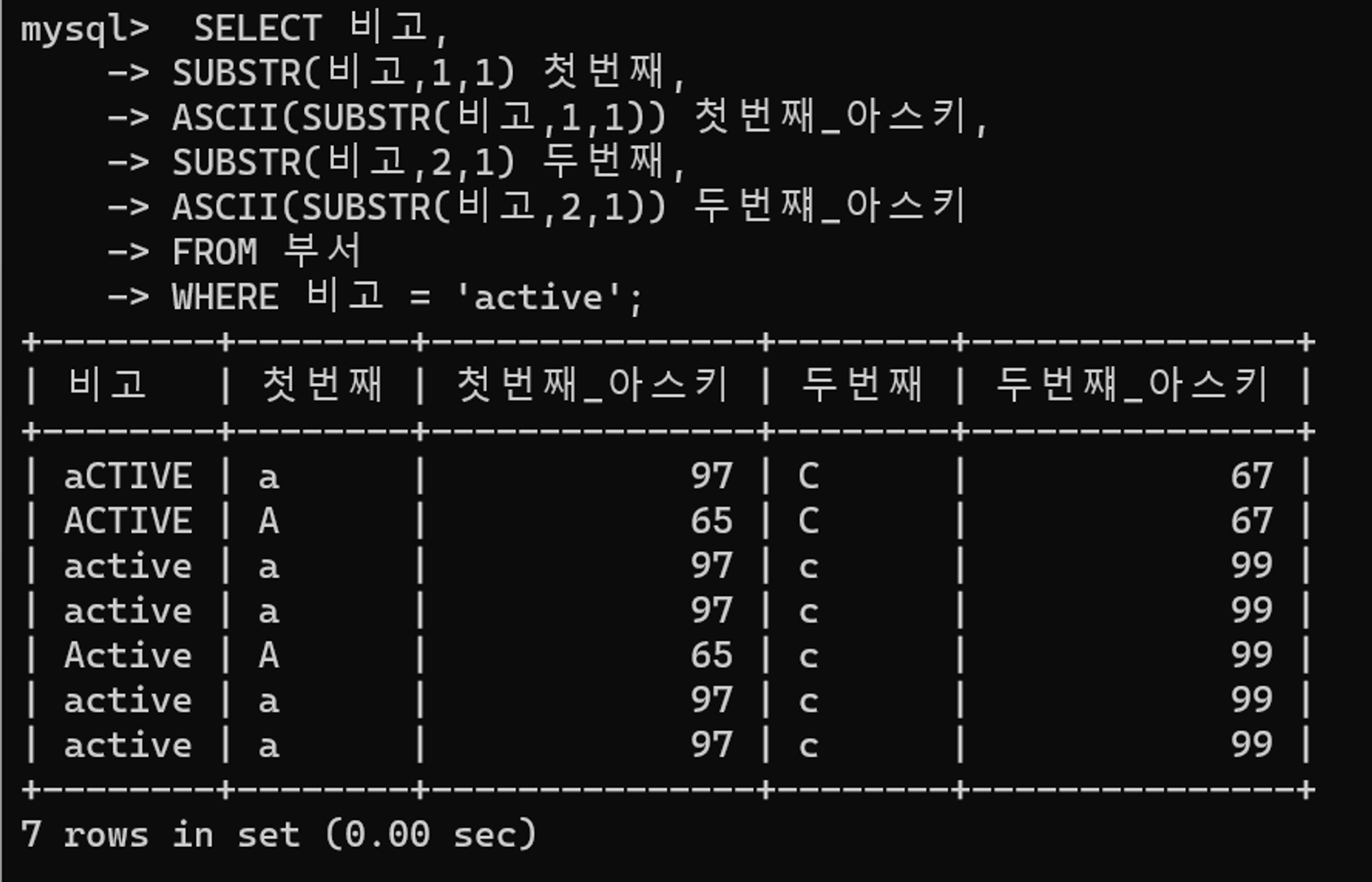
소문자 아스키 코드 값을 확인해보면 두번쨰 조건절은 소문자가 포함된 결과만 쿼리를 통해 도출되어야 한다는 것을 파악할 수 있다. 하지만 소문자 여부를 판단하기 위해 굳이 아스키 코드 추출 함수를 사용해야 할까?
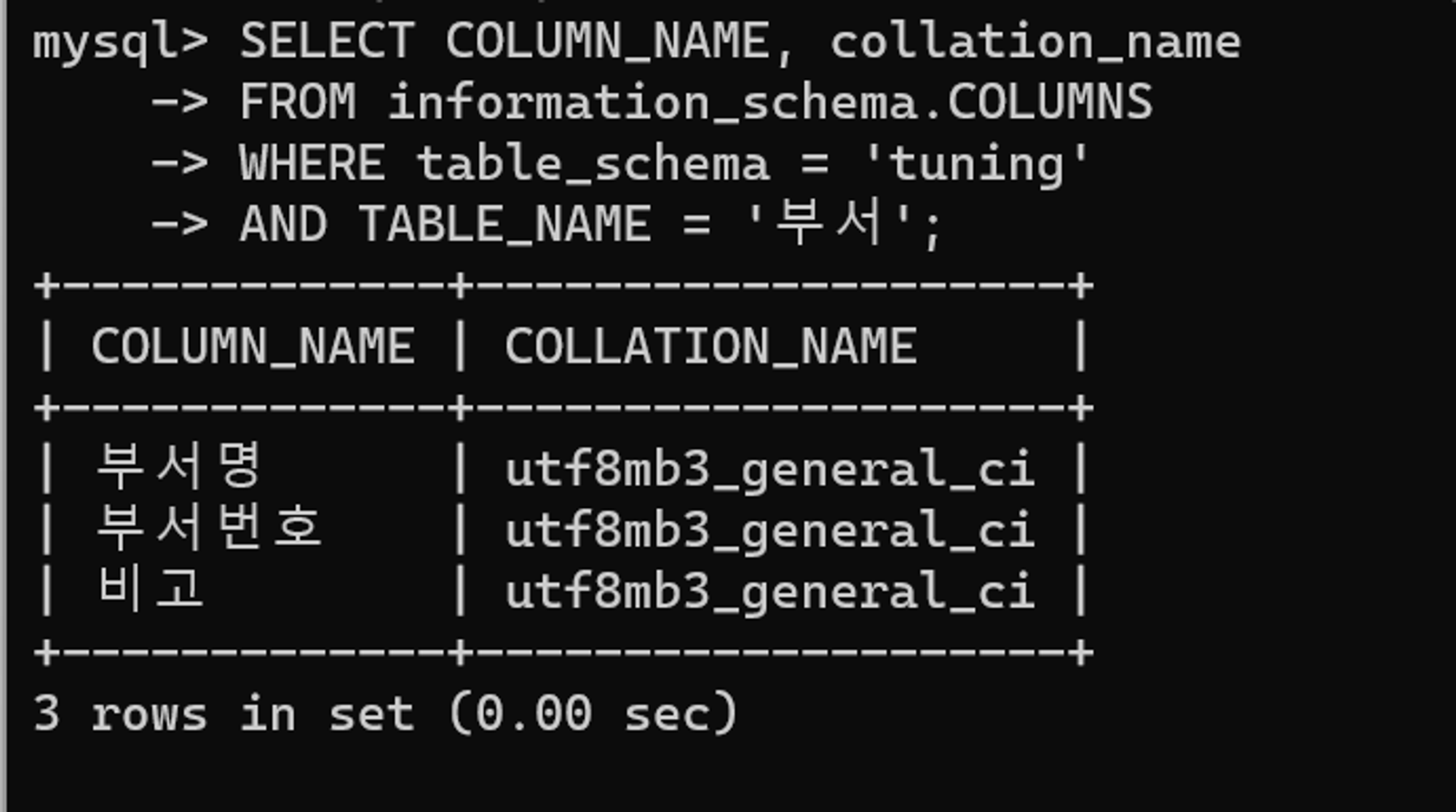
위와 같이 부서 테이블의 콜레이션을 확인해보면 대소문자를 구분하지 않는 utf8_general_ci 콜레이션임을 확인할 수 있다. 하지만 예제에서와 같이 대소문자를 구분하려면 콜레이션의 변경이 불가피하다. 비고 열의 콜레이션을 이모지까지 지원하는 UTF8MB4_bin으로 변경한다. 이를 통해 SUBSTR , ASCII 를 통해 수행되던 불필요한 작업을 제거할 수 있다.
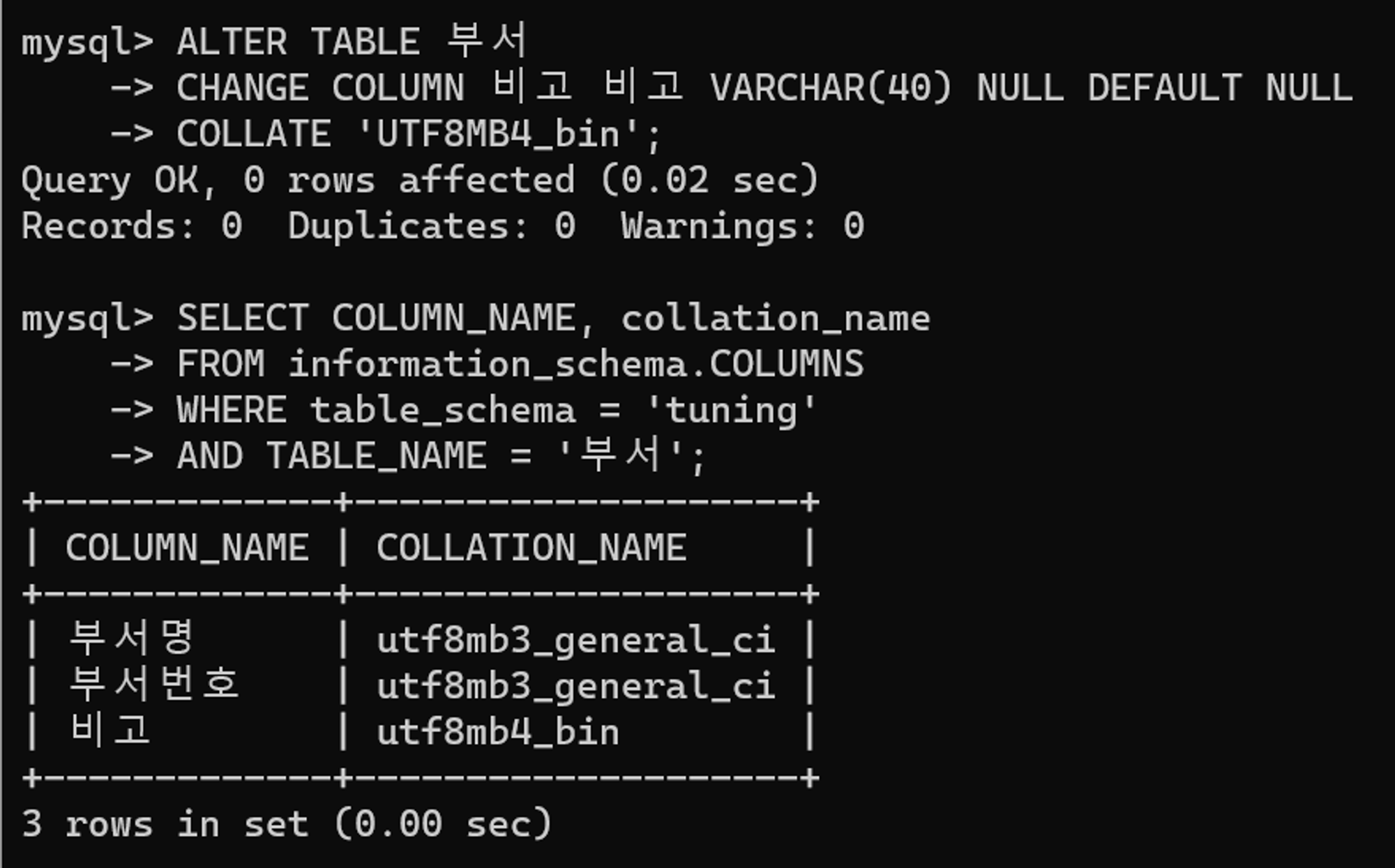
튜닝 결과
튜닝 후 SQL문
불필요한 함수를 제거한 형태이다.
SELECT 부서명, 비고
FROM 부서
WHERE 비고 = 'active'튜닝 후 수행 결과

비고 열에 대한 동등 조건만으로 소문자 active 데이터만 출력한다.
대소문자가 섞인 데이터와 비교하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT 이름 ,성, 성별, 생년월일
FROM 사원
WHERE LOWER(이름) = LOWER('MARY')
AND 입사일자 >= STR_TO_DATE('1990-01-01', '%Y-%m-%d')사원 테이블에서 입사일자가 1990년 이후이고, 이름이 MARY인 사원정보를 조회하는 쿼리이다.
튜닝 전 수행결과

튜닝 전 실행 계획

- 조건문에 이름, 입사일자 칼럼이 명시되어 있지만 테이블 풀 스캔으로 수행된다.
- 이름 칼럼이
LOWER로 가공되어, 관련 인덱스가 있어도 활용할 수 없다.
튜닝 수행
튜닝 대상인 테이블에서 조건절로 조회되는 데이터 건수를 확인해본다.

- 입사일자 칼럼의 조건문에 해당하는 데이터는 전체 데이터 대비 43%정도라 인덱스를 활용할 수 없다고 예상할 수 있다.
- 반면 함수에 의해 가공된 이름 조건절은 매우 적은 범위의 데이터에 접근할 수 있다.
현재 테이블에서 조건절의 칼럼중 인덱스가 생성된 칼럼은 입사일자뿐이다. 이름 칼럼이 카디널리티가 높으니 이에 대한 인덱스를 생성하는 것은 어떨까?

튜닝을 진행하기 위해 가공된 함수를 제거하고 결과를 확인해보면, 데이터가 조회되지 않는 것을 확인할 수 있다. LOWER 는 값을 소문자로 변경하여 비교하기 위해 사용되었다고 예상할 수 있다.

사원 테이블의 콜레이션을 확인해보면 이름 칼럼의 콜레이션은 대소문자를 구분하는 utf8_bin 이다. 데이터를 삽입할 때는 대소문자 구분이 필요하나, 검색할 때는 구분이 필요하지 않은 상황이다. 이에 따라 LOWER 를 적용하여 인덱스가 있어도 활용하지 못하는 문제가 발생했다고 볼 수 있다.
이름 칼럼에 대해 대소문자 구분없이 비교 처리를 수행하는 별도 칼럼이 있다면 어떨까? 이름 칼럼 옆에 소문자_이름 이라는 칼럼을 추가해보자. 신규 칼럼은 별도의 콜레이션을 설정하지 않으면 한 테이블의 콜레이션 값을 상속받으므로 utf8_general_ci 로 설정될 것이다. 이는 대소문자 구분을 하지 않는다.
ALTER TABLE 사원 ADD COLUMN 소문자_이름 VARCHAR(14) NOT NULL AFTER 이름;
UPDATE 사원 SET 소문자_이름 = LOWER(이름);위와 같이 열을 생성하고 데이터를 업데이트 해준다.
ALTER TABLE 사원 ADD INDEX I_소문자이름(소문자_이름);이름 정보를 비교하는 로직이 자주 호출된다는 가정 하에 인덱스를 생성해준다.
튜닝 결과
튜닝 후 SQL문
SELECT 이름 ,성, 성별, 생년월일
FROM 사원
WHERE 소문자_이름 = 'MARY'
AND 입사일자 >= '1990-01-01'대소문자 구분 없이 소문자_이름 칼럼을 활용하여 데이터를 추출하도록 변경한다.
튜닝 후 수행 결과

0.01초로 수행 시간이 개선되었다.
튜닝 후 수행 계획

- 카디널리티가 높은
소문자_이름칼럼으로 인덱스를 활용하여 데이터를 조회한다. - 이름 데이터가 중복되므로 디스크 용량이 낭비되는 비효율적인 방식처럼 보일 수 있지만, 인덱스를 활용하여 변별력이 좋은 칼럼을 적절하게 사용하는 쿼리 튜닝 방법이다.
분산 없이 큰 규모의 데이터를 사용하는 나쁜 SQL문
현황 분석
튜닝 전 SQL문
SELECT COUNT(1)
FROM 급여
WHERE 시작일자 BETWEEN STR_TO_DATE('2000-01-01', '%Y-%m-%d')
AND STR_TO_DATE('2000-12-31', '%Y-%m-%d')2000년도의 급여 데이터 건수를 조회하는 쿼리이다.
튜닝 전 수행 결과

튜닝 전 실행 계획

I_사용여부인덱스를 활용해 커버링 인덱스로 수행한다.- 테이블 접근 없이 인덱스만으로 원하는 데이터를 조회하는 것이다.
급여 테이블의 시작일자 칼럼에 대해 월 또는 연 단위의 조회가 빈번히 발생한다고 가정한다.
튜닝 수행
SQL문에 포함된 테이블, 조건절의 현황을 살펴보자. 2000년도의 데이터가 전체 데이터 대비 9% 수준임을 확인할 수 있다.

다른 연도의 데이터는 어떻게 분포되어 있는지 확인해보자. 연도간 데이터 편차는 조금 있으나, 전반적으로 고루 퍼져 있음을 볼 수 있다.

이런 경우 급여 테이블을 시작일자라는 칼럼으로 논리적으로 분할하는 파티셔닝을 할 수 있다. SQL문에서는 시작일자가 범위 기준으로 호출되므로 범위 방식 파티션으로 설정한다.
ALTER TABLE 급여
partition by range COLUMNS (시작일자)
(
partition p85 values less than ('1985-12-31'),
partition p86 values less than ('1986-12-31'),
partition p87 values less than ('1987-12-31'),
partition p88 values less than ('1988-12-31'),
partition p89 values less than ('1989-12-31'),
partition p90 values less than ('1990-12-31'),
partition p91 values less than ('1991-12-31'),
partition p92 values less than ('1992-12-31'),
partition p93 values less than ('1993-12-31'),
partition p94 values less than ('1994-12-31'),
partition p95 values less than ('1995-12-31'),
partition p96 values less than ('1996-12-31'),
partition p97 values less than ('1997-12-31'),
partition p98 values less than ('1998-12-31'),
partition p99 values less than ('1999-12-31'),
partition p00 values less than ('2000-12-31'),
partition p01 values less than ('2001-12-31'),
partition p02 values less than ('2002-12-31'),
partition p03 values less than (MAXVALUE)
)튜닝 결과
튜닝 후 SQL문
SQL문 자체는 변경사항이 없다.
튜닝 후 수행 결과

0.3초로 수행 시간이 극적으로 개선되었다.
튜닝 후 실행 계획

- 범위 파티션을 설정하여 시작일자가 2000년도인 파티션에만 접근하여 효율이 상승한다.
- 2000년도 데이터만 있는 p00 파티션에 접근한 뒤, 2000-12-31 접근일자의 다음 데이터도 2000년인지 확인하는 작업이 수행되어 2001년 데이터까지 접근한다.
