
다익스트라(Dijkstra) 알고리즘을 사용하여 최단 경로 문제를 푸는 방법에 대해 알아보자.
⭐️ 최단 경로 문제
- 최단 경로 알고리즘은 가장 짧은 경로를 찾는 알고리즘을 의미한다.
- 다양한 문제 상황
- 한 지점에서 다른 한 지점까지의 최단 경로
- 한 지점에서 다른 모든 지점까지의 최단 경로
- 모든 지점에서 다른 모든 지점까지의 최단 경로
- 각 지점은 그래프에서 노드로 표현
- 지점 간 연결된 도로는 그래프에서 간선으로 표현
💫 다익스트라(Dijkstra) 알고리즘
- 특정한 노드에서 출발하여 다른 모든 노드로 가는 최단 경로를 계산한다.
- 다익스트라 최단 경로 알고리즘은 음의 간선이 없을 때 정상적으로 동작한다.
- 현실 세계의 도로(간선)은 음의 간선으로 표현되지 않기 때문에 실제로 GPS 소프트웨어의 기본 알고리즘으로 채택되곤 한다.
- 다익스트라 알고리즘은 최단 경로를 구하는 과정에서 각 노드에 대한 현재까지의 최단 거리 정보를 항상 1차원 리스트에 저장하며 리스트를 계속 갱신한다는 특징이 있다.
- 다익스트라 최단 경로 알고리즘은 그리디 알고리즘으로 분류된다.
- 매 상황에서 방문하지 않은 노드 중에서 가장 비용이 적은 노드를 선택해 임의의 과정을 반복하기 때문이다.
알고리즘 원리
- 출발 노드를 설정한다.
- 최단 거리 테이블을 초기화한다.
- 방문하지 않은 노드 중에서 최단 거리가 짧은 노드를 선택한다.
- 해당 노드를 거쳐 다른 노드로 가는 비용을 계산하여 최단 거리 테이블을 갱신한다.
- 위 과정에서 3번과 4번을 반복한다.
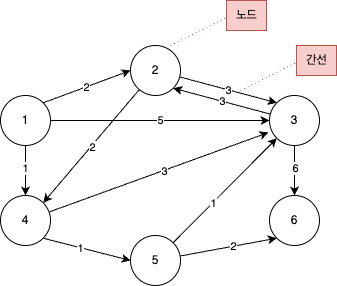
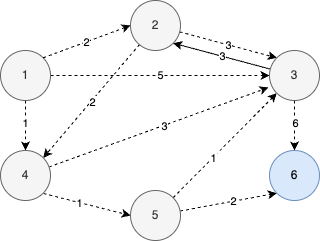
그래프를 통해 알고리즘 동작원리를 자세히 살펴보자.
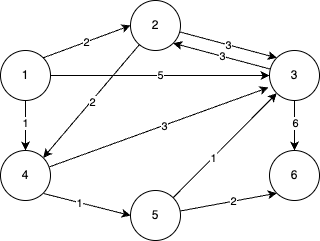
- 다음과 같은 그래프가 있을 때 1번 노드에서 다른 모든 노드로 가는 최단 경로를 구하는 문제를 생각해보자
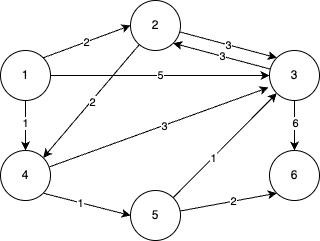
STEP 0
- 먼저 방문하지 않은 노드 중에서 최단거리가 짧은 노드를 선택해야 한다.
- 출발 노드에서 출발 노드로의 거리는 0으로 보기 때문에 처음에는 출발 노드가 선택된다.

STEP 1
- 이제 1번 노드를 거쳐 다른 노드로 가는 비용을 계산한다.
- 1번 노드와 연결된 모든 간선을 하나씩 확인하면 된다.
- 현재 1번 노드까지 오는 비용은 0이므로, 1번 노드를 거쳐서 2번, 3번, 4번 노드로 가는 최소비용은 차례대로 2(0+2), 5(0+5), 1(0+1)이다.
- 무한으로 설정되어 있는 2, 3, 4번 노드로 가는 비용을 각각 새로운 값으로 갱신한다.
- 처리된 결과는 다음과 같다.
- 현재 처리 중인 노드와 간선은 하늘색, 이미 처리한 노드는 회색, 이미 처리한 간선은 점선으로 표시하겠다.
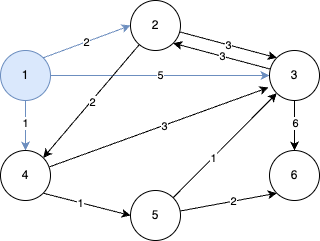

STEP 2
- 이후 단계에서도 마찬가지로 방문하지 않은 노드 중에서 최단 거리가 가장 짧은 노드를 선택해야 한다.
- 따라서 STEP 2에서는 4번 노드가 선택된다.
- 4번 노드를 거쳐서 갈 수 있는 노드를 확인한다.
- 4번 노드에서 갈 수 있는 노드는 3번과 5번이다.
- 4번 노드까지의 최단 거리는 1이므로 4번 노드를 거쳐서 3번과 5번 노드로 가는 최소 비용은 차례대로 4(1+3), 2(1+1) 이다.
- 이 두 값은 기존 리스트에 담겨 있던 값보다 작으므로 리스트가 갱신된다.
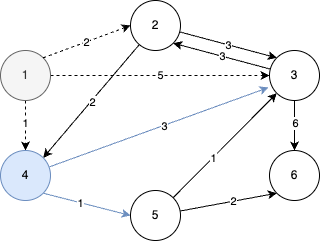

STEP 3
- STEP 3에서는 2번 노드가 선택된다.
- 2번과 5번 노드 까지의 최단 거리가 2로 값이 같은데, 이럴 때는 일반적으로 번호가 작은 노드를 선택한다.
- 2번 노드를 거쳐서 도달할 수 있는 노드 중에서 거리가 더 짧은 경우가 있는지 확인한다.
- 이번 단계에서 2번 노드를 거쳐서 가는 경우, 현재의 최단 거리를 더 짧게 갱신 할 수 있는 방법은 없다.
- 예를 들어 2번 노드를 거쳐 3번 노드로 이동하는 경우, 5(2+3)만큼의 비용이 발생하지만,
- 이미 현재 최단 거리 테이블에서 3번 노드까지의 최단 거리가 4이므로 값이 갱신되지 않는다.
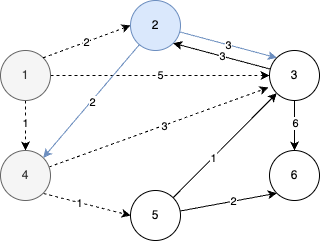

STEP 4
- 이번에는 5번 노드가 선택된다.
- 5번 노드를 거쳐 3번과 6번 노드로 갈 수 있다.
- 현재 5번 노드까지 가는 최단 거리가 2이므로 5번 노드에서 3번 노드로 가는 거리인 1을 더한 3이 기존 값인 4보다 작기 때문에 새로운 값 3으로 갱신된다.
- 6번 노드로 가는 거리도 마찬가지로 4로 갱신된다.
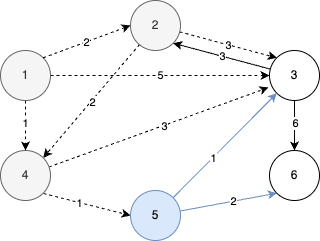

STEP 5
- 이어서 3번 노드를 선택한 뒤에 동일한 과정을 반복한다.
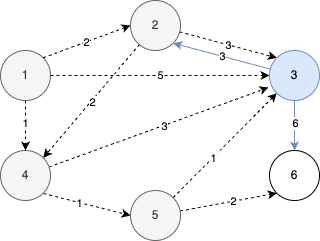

STEP 6
- 6번 노드를 선택한 후 같은 과정을 반복한다.
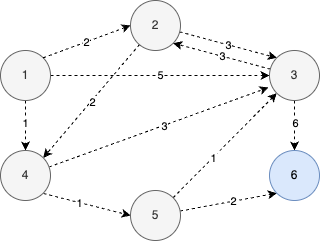
- 최종 최단 거리 테이블은 다음과 같다.

정리
- 최단 거리 테이블이 의미하는 바는 1번 노드로부터 출발 했을 때 2번, 3번, 4번, 5번, 6번 노드까지 가기 위한 최단 경로가 각각 2, 3, 1, 2, 4 라는 의미이다.
- 다익스트라 알고리즘에서는 방문하지 않은 노드 중에서 가장 최단 거리가 짧은 노드를 선택하는 과정을 반복한다.
- 이렇게 선택된 노드는 최단 거리가 완전히 선택된 노드이므로, 더이상 알고리즘을 반복해도 최단 거리가 줄어들지 않는다.
- 예를 들어, STEP 2에서는 4번 노드가 선택되어서 4번 노드를 거쳐서 이동할 수 있는 경로를 확인했다.
- 이후에 STEP 3 ~ STEP 6이 진행되었으나, 4번 노드에 대한 최단 거리는 더 이상 감소하지 않았다.
- 다시 말해 다익스트라 알고리즘이 진행되면서 한 단계당 하나의 노드에 대한 최단 거리를 확실히 찾는 것으로 이해할 수 있다.
📝 다익스트라 알고리즘 구현하기
방법 1. 간단한 다익스트라 알고리즘
- 간단한 다익스트라 알고리즘은 다익스트라에 의해서 처음 고안되었던 알고리즘이며,
O(V²)의 시간 복잡도를 가진다.- V는 노드의 개수를 의미한다.
- 작성한 코드는 다음과 같다. (코드 출처)
import sys
input = sys.stdin.readline
INF = int(1e9) # 무한을 의미하는 값으로 10억을 설정
# 노드의 개수, 간선의 개수를 입력받기
n, m = map(int, input().split())
# 시작 노드 번호를 입력받기
start = int(input())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트를 만들기
graph = [[] for i in range(n + 1)]
# 방문한 적이 있는지 체크하는 목적의 리스트를 만들기
visited = [False] * (n + 1)
# 최단 거리 테이블을 모두 무한으로 초기화
distance = [INF] * (n + 1)
# 모든 간선 정보를 입력받기
for _ in range(m):
a, b, c = map(int, input().split())
# a번 노드에서 b번 노드로 가는 비용이 c라는 의미
graph[a].append((b, c))
# 방문하지 않은 노드 중에서, 가장 최단 거리가 짧은 노드의 번호를 반환
def get_smallest_node():
min_value = INF
index = 0 # 가장 최단 거리가 짧은 노드(인덱스)
for i in range(1, n + 1):
if distance[i] < min_value and not visited[i]:
min_value = distance[i]
index = i
return index
def dijkstra(start):
# 시작 노드에 대해서 초기화
distance[start] = 0
visited[start] = True
for j in graph[start]:
distance[j[0]] = j[1]
# 시작 노드를 제외한 전체 n - 1개의 노드에 대해 반복
for i in range(n - 1):
# 현재 최단 거리가 가장 짧은 노드를 꺼내서, 방문 처리
now = get_smallest_node()
visited[now] = True
# 현재 노드와 연결된 다른 노드를 확인
for j in graph[now]:
cost = distance[now] + j[1]
# 현재 노드를 거쳐서 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distance[j[0]]:
distance[j[0]] = cost
# 다익스트라 알고리즘을 수행
dijkstra(start)
# 모든 노드로 가기 위한 최단 거리를 출력
for i in range(1, n + 1):
# 도달할 수 없는 경우, 무한(INFINITY)이라고 출력
if distance[i] == INF:
print("INFINITY")
# 도달할 수 있는 경우 거리를 출력
else:
print(distance[i])- 위에서 살펴본 예시를 나타낸 입력과 출력 결과는 다음과 같다.
6 11
1
1 2 2
1 3 5
1 4 1
2 3 3
2 4 2
3 2 3
3 6 5
4 3 3
4 5 1
5 3 1
5 6 20
2
3
1
2
4방법 2. 개선된 다익스트라 알고리즘
- 힙 자료구조를 활용하면 시간복잡도
O(ElogV)를 보장하여 해결할 수 있다.- 여기서
V는 노드의 개수이고,E는 간선의 개수이다. - 힙 자료구조에 대한 설명 및 heapq 모듈 사용 방법은 이전 게시물을 참고
- 여기서
- 파이썬 라이브러리에서는 기본적으로 최소 힙 구조를 이용하는데 다익스트라 최단 경로 알고리즘에서는 비용이 적은 노드를 우선으로 하여 방문하므로, 최소 힙 구조를 기반으로 하는 파이썬의 우선순위 큐 라이브러리를 그대로 사용하면 적합하다.
- 단순히 우선순위 큐를 이용해서 시작 노드로부터 거리가 짧은 노드 순서대로 큐에서 나올 수 있도록 다익스트라 알고리즘을 작성하면 된다.
이전에 살펴본 알고리즘 원리를 우선순위 큐가 어떻게 변하는지 중심으로 살펴보자.
- 알고리즘이 동작하는 기본 원리는 동일하며, 현재 가까운 노드를 저장하기 위한 목적으로 우선순위 큐를 추가로 이용한다.
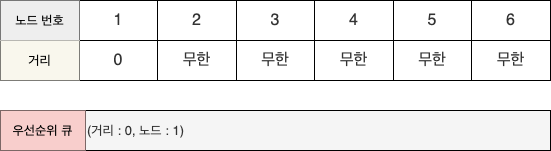
STEP 0
- 출발 노드를 제외한 모든 노드의 최단 거리를 무한으로 설정하고 1번 노드를 우선순위 큐에 넣는다.
- 1번 노드로 가는 거리는 자기 자신까지 도달하는 거리이기 때문에 0이고,
- (거리:0, 노드:1)의 정보를 가지는 객체를 우선순위 큐에 넣으면 된다.
- 파이썬에서는 간단히 튜플 (0, 1)을 우선순위큐에 넣는다.
- 파이썬의 heapq 라이브러리는 원소로 튜플을 받으면 튜플의 첫 번째 원소를 기준으로 우선순위 큐를 구성한다.
- 따라서 (거리, 노드번호) 순서대로 튜플 데이터를 구성해 우선순위 큐에 넣으면 거리순으로 정렬된다.
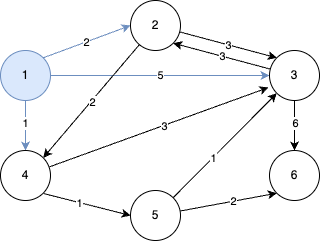
STEP 1
- 거리가 가장 짧은 노드를 선택하기 위해서는 우선순위 큐에서 그냥 노드를 꺼내면 된다.
- 거리가 가장 짧은 원소가 우선순위 큐의 최상위 원소로 위치해 있기 때문
- 우선순위 큐에서 노드를 꺼낸 뒤에 해당 노드를 이미 처리한 적이 있다면 무시하고, 아직 처리하지 않은 노드에 대해서만 처리하면 된다.
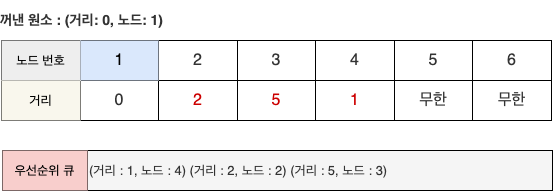
- STEP 1의 우선순위 큐에서 원소를 꺼내면 (0, 1)이 나온다.
- 1번 노드를 거쳐서 2번, 3번, 4번 노드로 가는 최소 비용을 계산한다.
- 차례대로 2(0+2), 5(0+5), 1(0+1)이다.
- 최단 경로 테이블을 갱신한다.
- 이번에도 마찬가지로 현재 처리 중인 노드와 간선은 하늘색, 이미 처리한 노드는 회색, 이미 처리한 간선은 점선으로 표시하겠다.
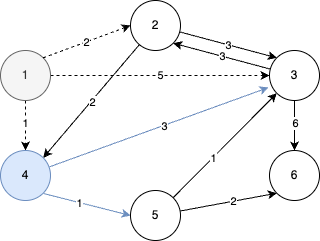
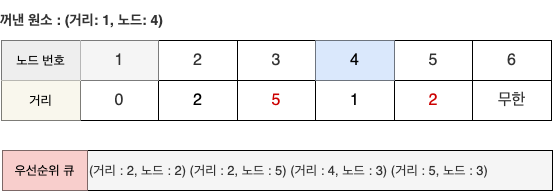
STEP 2
- 원소 (1, 4)를 꺼내서 알고리즘을 수행한다.
- 아직 노드 4를 방문하지 않았으며, 현재 최단 거리가 가장 짧은 노드가 4이다.
- 따라서 노드 4를 기준으로 노드 4와 연결된 간선들을 확인한다.
- 이때 4번 노드까지의 최단 거리는 1이므로 4번 노드를 거쳐서 3번과 5번 노드로 가는 최소 비용은 4(1+3), 2(1+1) 이다.
- 이는 기존 리스트에 담겨 있던 값들보다 작기 때문에 리스트는 갱신되고, 우선순위 큐에는 (4, 3), (2, 5)라는 원소가 추가로 들어간다.
STEP 3
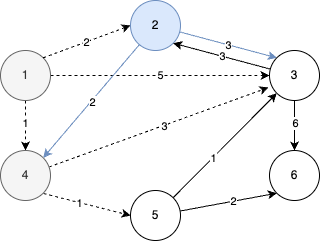
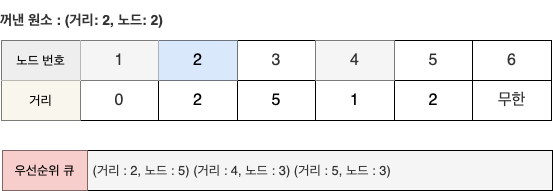
- 원소 (2, 2)를 꺼내서 알고리즘을 수행한다.
- 2번 노드를 거쳐서 가는 경우 중 현재의 최단 거리를 더 짧게 갱신할 수 있는 방법은 없으므로 우선순위 큐에는 어떠한 원소도 들어가지 않는다.
STEP 4
- 원소 (2, 5)를 꺼내서 알고리즘을 수행한다.
- 5번 노드를 거쳐 3번과 6번 노드로 갈 수 있다.
- 현재 5번 노드까지 가는 최단 거리가 2이므로 5번 노드에서 3번 노드로 가는 거리인 1을 더한 3이 기존 값인 4보다 작기 때문에 새로운 값 3으로 갱신된다.
- 6번 노드로 가는 거리도 마찬가지로 4로 갱신된다.
- 우선순위 큐에는 (3, 3)과 (4, 6)이 들어간다.
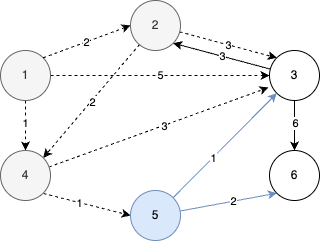
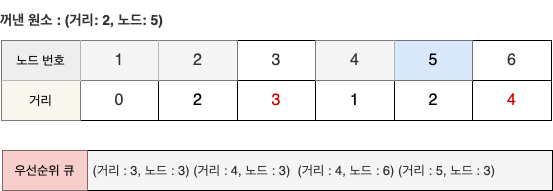
STEP 5
- 원소 (3, 3)을 꺼내서 알고리즘을 수행한다.
- 최단 거리 테이블은 갱신되지 않으며 결과는 다음과 같다.
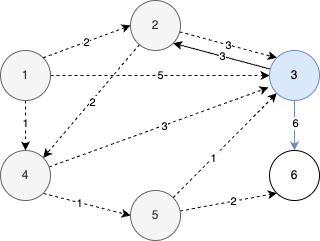
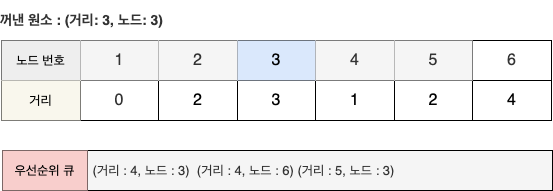
STEP 6
- 원소 (4, 3)을 꺼내 알고리즘을 수행한다.
- 3번 노드는 앞서 처리된 적이 있고, 현재 최단경로 또한 3이므로 무시한다.
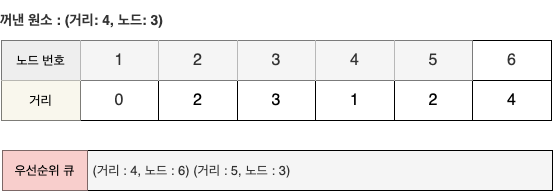
STEP 7
- 원소 (4, 6)을 꺼내 알고리즘을 수행한다.
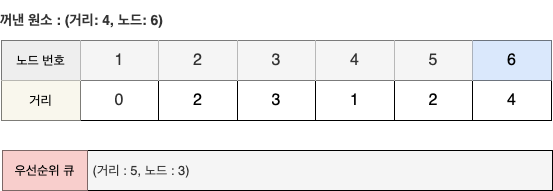
STEP 8
- 마지막으로 남은 원소인 (5, 3)을 꺼내지만 이미 처리된 노드이므로 무시한다.
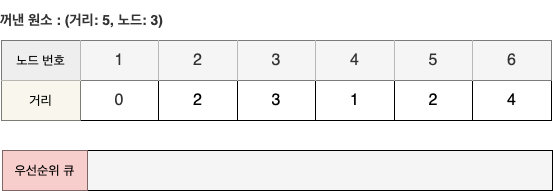
이제 코드를 작성해보자 !
- 위 방법에서는 최단 거리가 가장 짧은 노드를 찾기 위해 우선순위 큐를 이용하고 있으며, 앞선 방법 1과 비교했을 때 훨씬 빠르게 동작한다.
- 또한 방법 1처럼 get_small_node() 함수를 작성할 필요가 없다.
- 최단 거리가 가장 짧은 노드를 선택하는 과정을 다익스트라 최단 경로 함수 안에서 우선순위 큐를 이용하는 방식으로 대체할 수 있기 때문이다.
- 작성한 코드는 다음과 같다. (코드 출처)
import heapq
import sys
input = sys.stdin.readline
INF = int(1e9) # 무한을 의미하는 값으로 10억을 설정
# 노드의 개수, 간선의 개수를 입력받기
n, m = map(int, input().split())
# 시작 노드 번호를 입력받기
start = int(input())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트를 만들기
graph = [[] for i in range(n + 1)]
# 최단 거리 테이블을 모두 무한으로 초기화
distance = [INF] * (n + 1)
# 모든 간선 정보를 입력받기
for _ in range(m):
a, b, c = map(int, input().split())
# a번 노드에서 b번 노드로 가는 비용이 c라는 의미
graph[a].append((b, c))
def dijkstra(start):
q = []
# 시작 노드로 가기 위한 최단 경로는 0으로 설정하여, 큐에 삽입
heapq.heappush(q, (0, start))
distance[start] = 0
while q: # 큐가 비어있지 않다면
# 가장 최단 거리가 짧은 노드에 대한 정보 꺼내기
dist, now = heapq.heappop(q)
# 현재 노드가 이미 처리된 적이 있는 노드라면 무시
if distance[now] < dist:
continue
# 현재 노드와 연결된 다른 인접한 노드들을 확인
for i in graph[now]:
cost = dist + i[1]
# 현재 노드를 거쳐서, 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distance[i[0]]:
distance[i[0]] = cost
heapq.heappush(q, (cost, i[0]))
# 다익스트라 알고리즘을 수행
dijkstra(start)
# 모든 노드로 가기 위한 최단 거리를 출력
for i in range(1, n + 1):
# 도달할 수 없는 경우, 무한(INFINITY)이라고 출력
if distance[i] == INF:
print("INFINITY")
# 도달할 수 있는 경우 거리를 출력
else:
print(distance[i])- 입출력 결과는 방법 1과 동일하다.
시간 복잡도 : O(ElogV)
- 한 번 처리된 노드는 더이상 처리되지 않는다.
- 즉, 노드를 하나씩 꺼내 검사하는 반복문(while)은 노드의 개수
V이상의 횟수로는 반복되지 않는다.
- 즉, 노드를 하나씩 꺼내 검사하는 반복문(while)은 노드의 개수
- V번 반복될 때마다 각각 자신과 연결된 간선들을 확인한다.
- 따라서 현재 우선순위 큐에서 꺼낸 노드와 연결된 다른 노드들을 확인하는 총 횟수는
총 최대 간선의 개수(E)만큼 연산이 수행될 수 있다.
- 따라서 현재 우선순위 큐에서 꺼낸 노드와 연결된 다른 노드들을 확인하는 총 횟수는
- 전체 다익스트라 최단 경로 알고리즘은 E개의 원소를 우선순위 큐에 넣었다가 모두 빼내는 연산과 매우 유사하다.
- 힙에 N개의 데이터를 모두 넣고 이후에 빼는 과정은
O(NlogN)
- 힙에 N개의 데이터를 모두 넣고 이후에 빼는 과정은
- 최대 E개의 간선을 힙에 넣었다가 다시 빼면 시간 복잡도는
O(ElogE)- 만약 모든 노드끼리 서로 다 연결되어 있다고 하면, 간선의 개수를 약 V²개로 볼 수 있고, E는 항상 V²이하이기 때문에 다익스트라 알고리즘의 전체 시간 복잡도는
O(ElogV)라고 볼 수 있다.
- 만약 모든 노드끼리 서로 다 연결되어 있다고 하면, 간선의 개수를 약 V²개로 볼 수 있고, E는 항상 V²이하이기 때문에 다익스트라 알고리즘의 전체 시간 복잡도는
📍 References
- 이것이 취업을 위한 코딩 테스트다 with 파이썬 - 나동빈 저
- https://www.youtube.com/watch?v=acqm9mM1P6o

코드로 꿈을 펼치는 개발자의 이야기, 노력과 열정이 가득한 곳 🌈