
100명의 신입생을 데리고 MT를 갔다. 예약한 숙소는 3개일 때, 학생회장은 어떻게 방을 배정해야 할까?
해시를 설명하기에 가장 적절한 예시다.
해시테이블은 키-원소 데이터 항목(사전)을 메모리에 어떻게 하면 효율적으로 저장하게 할 수 있을까를 고민한다. 학생회장이 100명의 학생들을 3개의 방에 어떻게 하면 골고루 배분할 수 있을까를 고민하는 것과 같다.
해시테이블, 해시
해시테이블은 사전 ADT이므로 삽입, 삭제, 탐색이 주요 작업이다. 삽입은 학생회장이 애들을 방에 넣는 것일테고, 탐색은 그 학생이 어떤 방에 있는지 찾는 것이다.
bst도 해시테이블처럼 사전 ADT이다. 둘의 차이점은 해시테이블에서는 키값을 비교하는 것이 아니라 키값을 조작하여 메모리에 배정한다는 것인데 이처럼 키값을 건드리는 것을 hash라고 한다.
해시테이블은 버켓과 해시함수 로 구성된다.
버켓
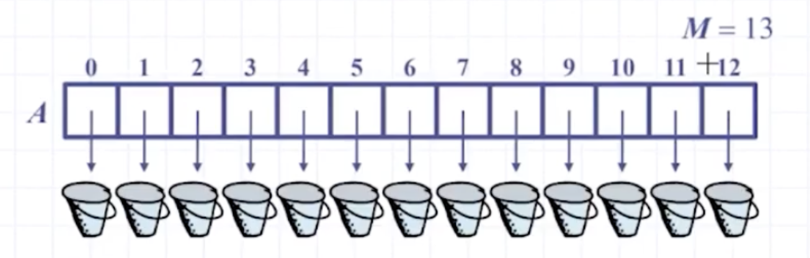
버켓은 해시테이블을 나타내는 어떠한 배열을 의미한다. 키값 k를 가지는 원소 e는 A[k]에 삽입된다.
만약 배열 사이즈 범위 내에 원소들이 뿔뿔이 잘 흩어지면 탐색, 삽입, 삭제에 상수 시간 소요된다. 이를 위해서는 각 키값이 버켓 내에서 유일해야 하는데 사실상 어렵다.
해시함수
해시함수는 주어진 데이터의 키값을 통해 0 ~ M-1 범위 내에 매핑하는 것이다.
h(key) = key % M해시함수의 가장 간단한 예다. h(key)는 key에 대한 해시값이라 한다. i=h(key) 라고 했을 때, key값을 가진 데이터는 버켓의 i번째에 저장된다.
해시코드맵
해시함수는 보통 해시코드맵과 압축맵의 복합체로 정의된다. 해시코드맵은 어떤 키값을 integer의 형으로 변환하는 작업을 한다.
학생회장이 방에 배치하기 위해 학번을 이용하려 했을 때, 해시코드맵은 학번을 정수의 형태로 바꾸는 것을 수행한다.
해시코드맵 설계
해시코드맵 설계에는 메모리 주소, 정수 캐스트, 요소합, 다항 누적 등이 있다. 메모리 주소는 주소값을 정수로 치환한다. 이는 문자열에 적용이 힘들다는 단점이 있다. 정수 캐스트는 키의 비트값을 정수로 치환한다. `
요소합`은 키의 비트들을 고정길이로 분할한 후 각 요소를 합한 값을 정수로 사용한다. 그러나 문자열에서 stop, tops, spot, pots들을 요소합으로 처리할 경우 모두 동일한 정수를 뱉어내어 동일한 주소로 매핑되는 문제점이 있다.
다항 누적은 요소합처럼 키의 비트들을 고정길이로 분할한 후 각 요소를 합하는데 차이점은 위치에 따라 가중치를 두어 합한다. 다항 누적은 문자열 키에 적합한 해시코드맵이다. z를 33으로 하고 50,000개의 영단어에 대해 6회의 충돌밖에 발생하지 않았다.
압축맵
압축맵은 정수를 버켓에 매핑한다. 위에서 예로 든 해시함수가 압축맵이다.
압축맵 설계
압축맵은 보통 나머지셈과 승합제가 쓰인다.
h(k) = |k| % M나머지셈은 h(k) 값을 해시테이블의 크기로 나눈다. 이 때 M은 골고루 분배하기 위해 prime을 선택하는 것이 좋다.
h(k) = |ak + b| % M승합제는 키값에 상수를 곱하고 다른 상수를 더한 것을 M으로 나눈다. 이 때, a와 b는 음이 아닌 정수고 a는 M의 배수가 아니어야 한다. a가 M의 배수 즉, a % M이 0이게 되면 모두 b로 갈 것이다.
📌충돌
앞서 해시코드맵 설계의 방법 중 하나인 다항 누적을 말하며 충돌을 언급했다. 충돌은 서로 다른 원소가 동일한 메모리에 매핑되는 것을 말한다.
배열 사이즈를 M, 원소 개수를 N이라 했을 때,
M < N 인 경우 충돌은 필연적이고
M > N 의 경우라도 충돌은 일어날 수 있다.
충돌을 방치하면 탐색, 삽입, 삭제 작업 성능이 크게 저하되는데 따라서 이 충돌을 해결해야 한다.
충돌 해결에는 크게 분리연쇄법과 개방주소법이 있다.
📙분리연쇄법
분리연쇄법(separate chaining)에서 각 버켓 A[i]는 리스트에 대한 참조를 저장한다. 다시 말해, 버켓의 셀들은 연결리스트의 헤더 역할을 수행하고 그 헤더들에 원소들이 딸려 나오는 구조다.
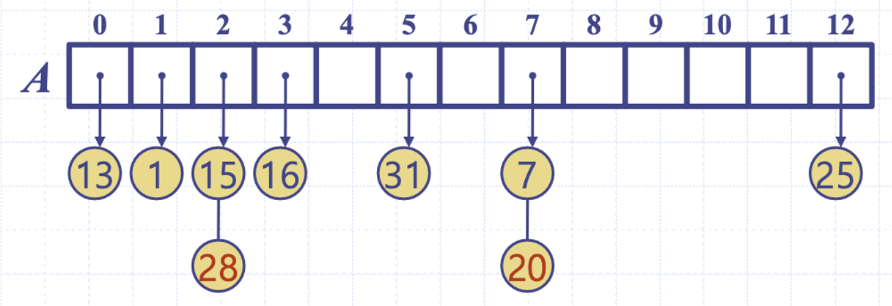
이렇게 구현했을 때, 같은 주소로 2개 이상이 반환되더라도 충돌을 피할 수 있다. 분리연쇄법은 단순하고 빠르다는 장점이 있지만, 추가 메모리를 필요로 한다는 단점이 있다.
분리연쇄법 의사코드
Alg find(k)
input bucket array A[0...M-1], hash func h, key k
output elem with key k
v <- h(k)
return A[v].elem()Alg insert(k, e)
v <- h(k)
A[v].insertData(k, e)
returnALg remove(k)
v <- h(k)
return A[v].remove()탐색, 삽입, 삭제 메서드 모두 해싱부터 시작한다.
추가로 버켓을 초기화할 때는 배열 원소에 null 포인터를 지정하고 원소가 삽입되었을 때 해당 셀이 원소 쌍을 가리키게 한다. (각 버켓은 리스트에 대한 참조를 저장한다.)
📙개방주소법
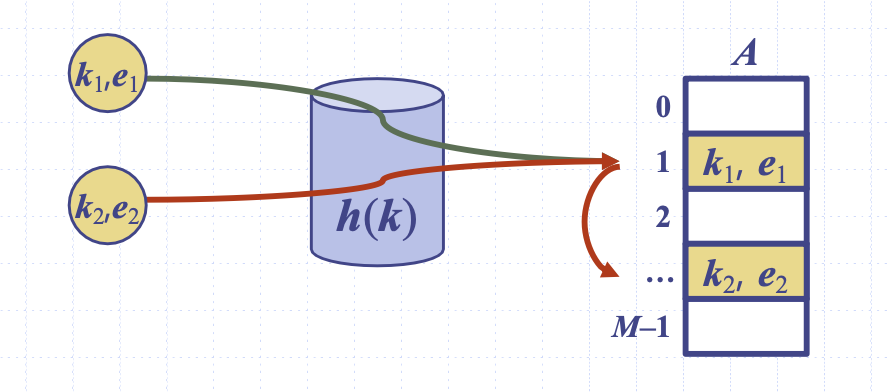
개방주소법에서 충돌 항목이 테이블의 다른 셀로 저장된다.
몇 칸 떨어져 갈 것이냐에 대한 다양한 전략을 세울 수가 있다. 예를 들어 x가 1에 매핑되고 y도 1에 매핑되면 충돌로 인해 3칸 떨어져 4에 저장된다 하자. 다음 z가 1에 매핑되면 충돌 해결로 인해 z는 7에 매핑된다.
z를 탐색하기 위해 z를 해싱해 1번이 나온다. 1번이 z가 아니니 4번을 보고 그 다음 7번을 봐서 z를 찾아낸다. 그런데 만약 y가 remove 되었다면 어떻게 될까? 1번을 본 후 4번을 볼 때, 4번이 null이 되어 탐색에 실패한다. 그래서 active, inactive와 같은 라벨을 달아 탐색을 더 진행해도 되는지 아닌지에 대한 안전 장치를 걸어주어야 한다.
개방주소법은 공간을 절약하지만 삭제에 대해 어려울 뿐만 아니라 군집화(clustering) 의 단점도 있다.
개방주소법은 충돌 위치에서 얼마나 떨어진 셀에 저장하냐에 따라 선형조사법, 2차 조사법, 이중해싱으로 나뉜다.
선형조사법
충돌 항목에서 바로 다음 셀에 저장한다. 선형조사법의 예시를 보자.
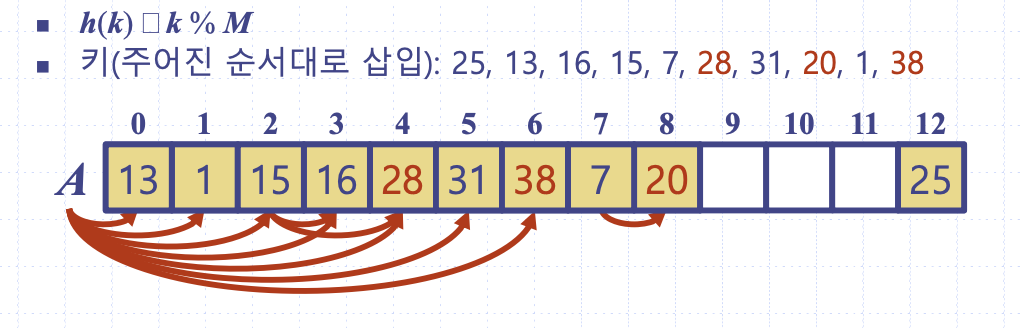
나머지셈의 압축맵을 쓰고 25, 13, 16 ... 1, 38의 순서로 버켓에 삽입된다 하자. 최종 버켓의 모양은 다음과 같다.
선형조사법은 충돌 항목들이 매우 군집화되어 이후 충돌에 대해 더욱 긴 충돌이 발생하고 군집되는 단점이 있다. 이를 1차 군집화(primary clustering)이라 한다.
2차 조사법
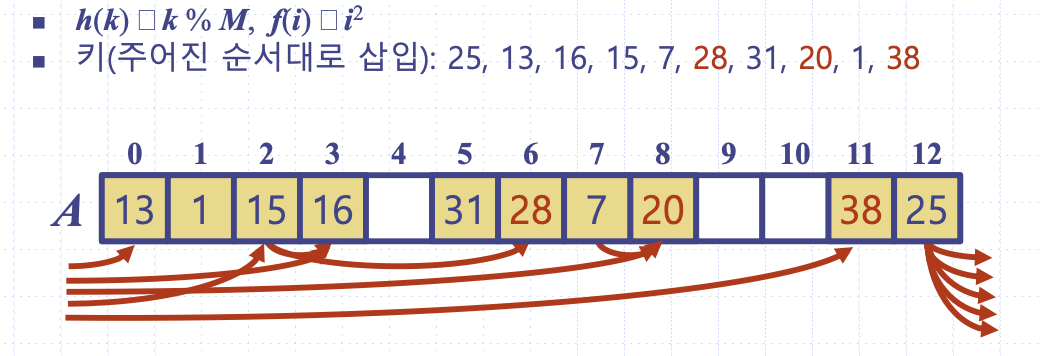
2차 조사법은 선형조사법의 군집화 문제를 해소하고자 한다. 충돌이 발생하면 1칸, 4칸, 9칸 순으로 빈 셀을 찾아간다. 그러나 해시값이 동일한 키에 대해 동일한 조사를 하게되어 나름의 군집을 형성한다. 또한 배열 사이즈가 prime이 아니거나 적재율이 반을 넘어가면 빈 셀이 있더라도 삽입할 셀을 찾지 못할 수 있다는 것이 큰 단점이다.
이중해싱
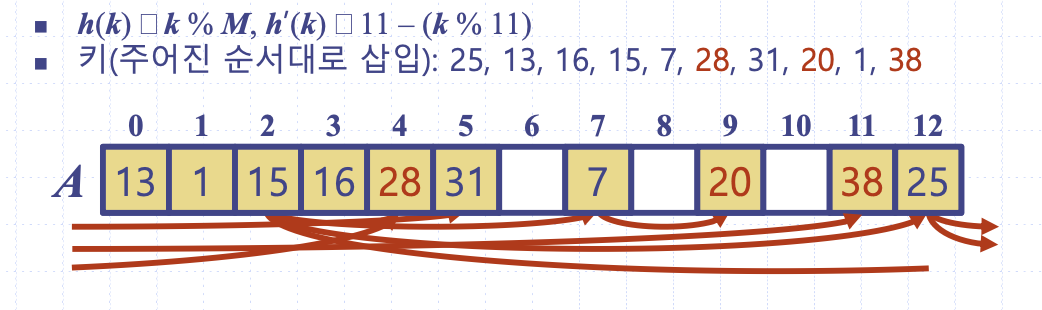
이중해싱은 말 그대로 해시함수를 이중으로 사용하는 것이다.
h(k) = k % M //1차 해싱
h'(k) = 11 - (k % 11) //2차 해싱, 충돌 시 보폭이 됨이중해싱은 동일한 해시값을 갖더라도 2차 해싱에서 서로 상이한 보폭을 갖게 하기 때문에 군집화를 최소화한다.
이중해싱은 보폭이 0이 되지 않도록 설계해야 한다는 점과 보폭(h')과 배열 사이즈(M)가 서로소이도록 설계해야 최선의 결과를 유도할 수 있다는 점을 알아야 한다.
//q는 배열 사이즈 M보다 작은 수 중 제일 큰 prime
h'(k) = q - (k%q)
h'(k) = 1 + (k%q)일반적으로 이 둘을 사용하면 좋다.
개방주소법 의사코드
Alg find(k)
input bucket array A, hash func h, key k
output elem with key k
v <- h(k)
i <- 0
while(i < M){
b <- getNextBucket(v, i)
if(isEmpty(A[b])){
return NotFoundKey
} else if(k = key(A[b])){
return element(A[b])
} else{
i++
}
}
return NotFoundKey먼저 파라미터의 키값을 해싱한다. i는 0부터 배열 사이즈가 될 때까지 반복문을 돈다. 해싱한 v와 i를 인자로 넘겨 보폭을 알아낸다. getNextBucket()은 개방주소법 전략에 따라 나뉠 수 있다. 선형조사법이면 i만큼 v에 더해서 셀을 알아낼 것이고 2차 조사법이면 i의 제곱만큼 v에 더해서 셀을 구할 것이다.
i가 0에서 시작하는 이유는 맨 처음에 해싱한 v값에 삽입하기 위해 try할 것이기 때문!
개방주소법 갱신(비활성화 전략)
윗 부분에서 개방주소법을 소개할 때 x, y, z의 예를 들며 삭제에 대한 어려움이 있다고 했다. 그리고 삭제에 대한 안전 장치를 언급했는데 이 안전 장치에 대한 전략으로 비활성화 전략이 있다.
비활성화 전략은 각 셀에 active, inactive, empty 3가지 라벨을 사용해 셀을 구분한다. 탐색 시 empty를 만나면 탐색을 중단하고 inactive를 만나면 keep going 한다.
해시테이블 성능
모든 원소가 충돌이 난다면 해시테이블의 탐색, 삽입, 삭제는 O(n) 시간에 수행된다. 하지만 적재율을 잘 관리하고 해싱이 잘 되고 있다면 모든 작업들이 상수 시간에 가능하다.
그렇다면 해시테이블 성능 유지를 위해 적재율과 재해싱에 대해 알아보자.
적재율(load factor)
해시테이블의 적재율은 n/M으로 정의된다. 적재율은 가용 공간 M 중 데이터가 얼마나 있나를 보는데 적재율이 낮을수록 성능이 좋다. 적재율을 a라 했을 때, 탐색과 삽입, 삭제 메서드의 성능이 O(a)이기 때문이다.
분리연쇄법에서의 적재율
a가 1이 넘어갈 수 있고 1이 넘어가게 되면 비효율적이다. a가 0.75 미만을 유지했을 때, O(a) 성능을 기대할 수 있다.
개방주소법에서의 적재율
a는 항상(당연) 1을 넘지 않는다. a가 0.5를 넘어가면 선형조사법, 2차 조사법에서 군집화 가능성이 커지고 0.5 미만에서 O(a) 성능을 기대한다.
재해싱
적재율의 설명을 보니 성능을 위해 가능한 낮은 적재율을 유지하는 것이 중요하다는 것을 알 수 있다. 해시테이블의 적재율을 일정 이하로 유지하기 위해서 적재율의 분모, 배열 사이즈를 관리해야 한다.
언제 재해싱을 하나?
- 적재율이 일정을 넘어감
- 삽입 실패가 일어났음
- *너무 많은 inactive로 탐색, 삭제 성능이 저하되었음
어떻게 재해싱을 하나?
- 버켓 사이즈 2배
- 새로운 버켓 사이즈에 대한 압축맵을 수정한다.
- 기존 원소들을 새로운 압축맵으로 삽입
참고 : 국형준. 알고리즘 원리와 응용. 21세기사, 2018.
