힙(heap)이란 힙순서를 가진 완전이진트리의 자료구조다. 힙 구조는 최솟값 혹은 최댓값을 쉽게 추출할 수 있도록 하는 일종의 우선순위 큐다. 하지만, 힙은 느슨한 정렬 상태 정도를 유지한다.
힙의 속성은 부모의 키값이 자식의 키값보다 작거나 같아야 한다.(최소힙이라는 가정 하에 그렇다. 최대힙의 속성은 이의 반대가 된다.)
해당 포스트에서는 최소힙을 가정하고 설명한다.
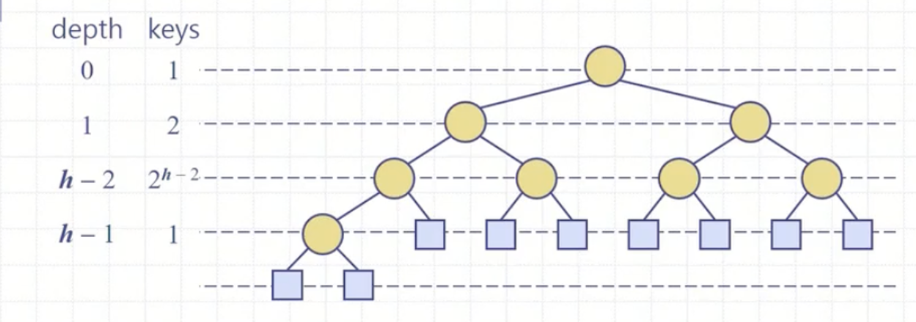
완전이진트리 형태이기 때문에 N개의 원소에 대한 트리의 높이는 O(log N)이다.
힙에서 가장 중요한 것은 lastNode를 잘 관리해야 하는 것이다. lastNode를 통해 insert, delete가 이루어지기 때문이다.
힙 삽입
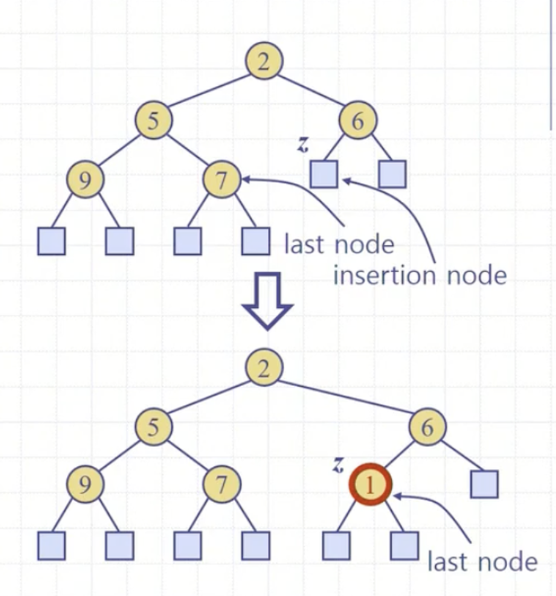
lastNode를 활용해 삽입 방법을 알아보자.
- lastNode를 찾는다.
- lastNode 다음 노드를 찾아 삽입하고자 하는 키값을 저장한다.
여기서 그치게 되면 힙 속성을 위배하게 된다. UpHeap으로 힙 속성 복구 작업을 해주어야 한다.
다음은 힙 삽입에 대한 의사 코드다.
Alg insert(k)
input key k, node lastNode
output none
advanceLastNode()
z <- lastNode
z.key <- k
expandExternal(z)
upHeap(z)
returninput으로는 삽입하려는 key값과 힙의 현재 lastNode를 받는다.
가장 먼저 lastNode의 위치를 한 칸 전진시켜 삽입을 위해 노드의 위치를 갱신해주어야 한다. 그 후, z에 새로 갱신한 lastNode를 저장한다.
z에 key값을 저장한 후, 외부노드를 내부노드로 확장해준다.(현재 설명하는 힙 개념은 각 노드들을 linked하기 때문이다. 힙이 만약 index 0을 비워 놓는 배열로 구현된다면 해당 작업은 하지 않는다.)
노드를 성공적으로 삽입 후에는 upHeap(z) 메서드를 호출하여 힙 속성을 복구한다.
upHeap
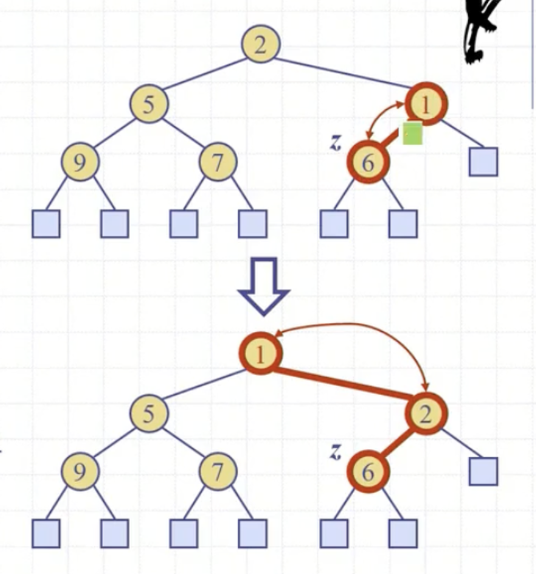
upHeap은 삽입한 노드로부터 부모노드로 쭉 따라 올라가면서 진행이 된다.
부모와 삽입노드의 키값을 비교해 삽입노드의 키값이 더 클 때까지 올라간다.
수행 시간은 힙의 높이인 O(log N)이다.
다음은 힙 속성을 복구하는 upHeap에 대한 의사 코드다.
Alg upHeap(v)
input node v
ouput none
if(isRoot(v)){
return
}
if(key(v) >= key(parent(v)){
return
}
swap(v, parent(v))
upHeap(parent(v))upHeap()은 노드를 파라미터로 받고 재귀적으로 수행된다. 최초에 upHeap()을 호출할 때는 v가 삽입 노드가 될 것이다.
재귀 함수이기 때문에 base case를 먼저 작성한다.
upHeap()이 멈출 때는 노드가 트리의 root에 도착했을 때와 파라미터 노드의 키값이 부모 노드의 키값보다 클 경우다.
파라미터 노드가 부모노드의 키값보다 작다면 이 둘을 swap해준다.
swap에서 그치면 안 된다. 스왑 이후에도 힙 속성이 위배되어 있을 가능성이 여전히 있기 때문에 스왑 이후 그 부모노드를 파라미터로 전달하여 upHeap()한다.
힙 삭제
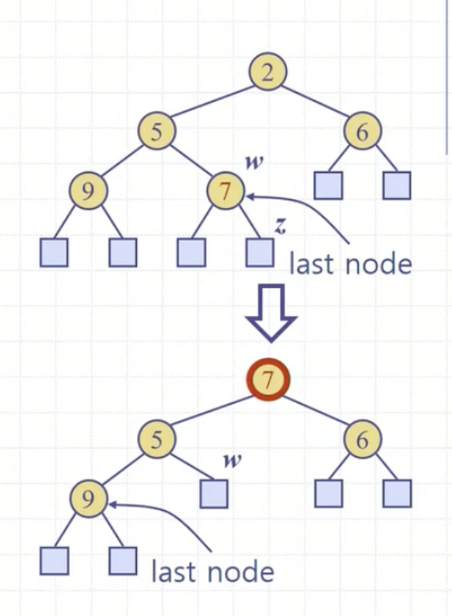
힙의 삭제는 키 값이 가장 작은 힙 트리의 root를 삭제하는 것이 해당 된다.
lastNode를 활용해 삭제 방법을 알아보자.
- root를 lastNode의 키값으로 대체시킨다.
- reduceExternal() 작업으로 lastNode 위치를 외부노드로 축소시킨다.
- lastNode의 위치를 갱신한다. (외부노드로 축소했으니)
- downHeap()을 통해 힙 속성을 복구한다.
삽입은 upHeap()을 사용하지만, 삭제는 downHeap()을 사용한다.
삽입은 expandExternal()을 하지만, 삭제는 reduceExternal()을 한다.
다음은 remove()에 대한 의사 코드다.
Alg remove()
input node lastNode
output key
k <- key(root())
w <- lastNode
root.key <- w.key //key값 대치
retreatLastNode(lastNode) //lastNode 위치 갱신
z <- rightChild(w)
reduceExternal(z) //lastNode였던 녀석의 오른쪽 자식을 파라미터로 전달
downHeap(root()) //root부터 downHeap
return kremove()의 파라미터로는 lastNode만 전달한다.
k에는 삭제 후 반환해줄 루트의 키값을 저장해 놓는다. w는 현재의 lastNode를 저장한다. w는 이후 reduce될 예정이다.
루트의 키값은 lastNode의 키값으로 대체한다. 이후, retreatLastNode()를 통해 lastNode의 위치를 갱신해준다.
node z에는 예전 lastNode의 오른쪽 자식을 전달한다. 왜 오른쪽 자식을 전달하는지에 대해서는 뒤에 설명한다.
예전 lastNode의 오른쪽 자식을 파라미터로 전할하여 reduceExternal() 작업을 하고 난 후, downHeap()을 루트에서부터 검사한다. 마지막으로 remove한 루트의 키값을 반환하면 remove() 작업은 완료된다.
삭제가 삽입보다 조금 까다로운 작업으로 다가오는 이유는 reduceExternal() 때문이라고 생각한다. reduceExternal을 위한 파라미터에서도 예전 lastNode의 오른쪽 자식을 전달하고 있기 때문이다.
downHeap
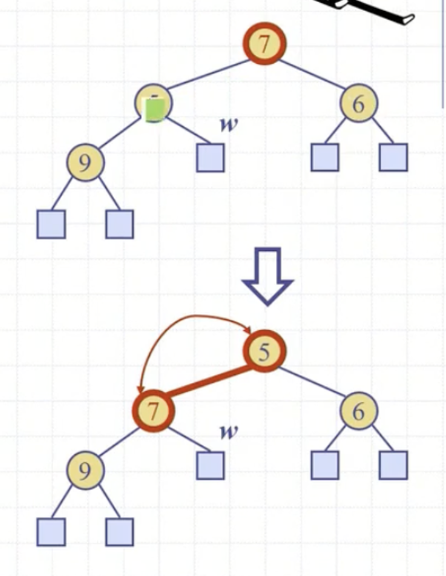
downHeap()은 루트에서 시작하여 자식들을 통해 통해 내려간다.(그래서 down이다.)
downHeap()은 파라미터로 전달되는 노드의 키값이 자식 2놈보다 작을 때까지 검사한다.
노드의 키값이 자식의 키값보다 크다면 swap을 해줘야 하는데, 둘 중 더 작은 놈과 swap을 한다.
downHeap() 역시 upHeap()과 수행 시간은 힙의 높이인 O(log N)이다.
다음은 downHeap()의 의사 코드다.
Alg downHeap(v)
input node v
ouput none
if(isExternal(left(v)) & isExternal(right(v)))
return
smaller <- left(v)
if(!isExternal(right(v))) {
if(key(right(v)) < key(smaller)){
smaller <- right(v)
}
}
if(key(v) <= key(smaller))
return
swap(v, smaller)
downHeap(smaller)downHeap()은 노드를 파라미터로 받고 재귀적으로 수행한다. 최초에 downHeap()을 호출할 때의 파라미터는 루트 노드가 될 것이다.
재귀 함수이기 때문에 base case를 먼저 작성한다. 자식이 모두 외부노드라면 비교할 원소가 없기 때문에 리턴한다.
그게 아니라면, 비교를 해 스왑을 할지 말지 결정한다. smaller에 왼쪽 자식을 먼저 저장한다. (왼쪽 자식이 없는데 오른쪽 자식이 있는 경우는 없다.) 여기서 오른쪽 자식도 있다면 두 자식의 키를 비교해 smaller에 더 작은 놈을 저장한다.
이제 여기서 smaller와 파라미터로 전달된 노드의 키를 비교하는데, 노드가 smaller보다 작다면 swap의 이유가 없기 때문에 리턴한다. 그게 아니라면 smaller와 파라미터 노드 v를 swap한다.
마지막에 downHeap()을 호출해 같은 로직으로 한 번 더 검사한다.
reduceExternal
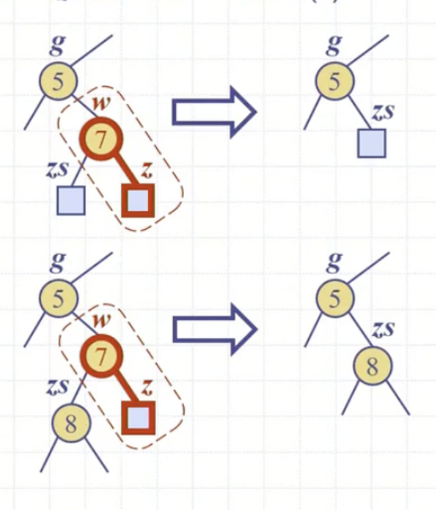
삭제 전 lastNode를 외부노드로 축소하는 reduceExternal() 작업은 노드에 대한 포인터가 4개까지 나오기에 생각을 조금 요구한다.(하지만, 힙을 배열로 구현하게 되면 expandExternal과 같이 고려하지 않아도 된다.)
그림을 살펴보면 위 그림은 자식 모두 외부 노드인 경우, 아래 그림은 자식이 하나 있는 경우를 말하고 있다. 힙에서 노드를 reduce할 때에는 사실 아래 그림의 case는 나오지 않는다. lastNode를 축소하는데 자식이 있을 리가 없기 때문이다. 하지만, 이후 bst와 AVL tree 개념에서 다시 등장하기에 살펴보자.
다음은 reduceExternal()의 의사 코드다.
Alg reduceExternal(z)
input external node z
output the siblng of z node that replace parent of z node
w <- z.parent
zs <- z.sibling
if(isRoot(w)) //z의 부모가 root
root <- zs
zs.parent <- ∅
else
g <- w.parent
zs.parent <- g
if(w = g.left) //w의 부모와 zs를 연결
g.left <- zs
else
g.right <- zs
putNode(z) //파라미터 노드 z 메모리 해제
putNode(w) //z의 부모(lastNode 였던) 메모리 해제
return zsw와 zs를 먼저 정의한다. 각각 파라미터 노드의 부모, 형제 노드다. w는 예전의 lastNode이기도 하다.
w가 루트노드라면 root 노드를 가리키는 포인터와 zs를 곧바로 이어주면 된다.
w가 부모를 가지고 있다면 그 노드와 zs를 연결한다.
z와 w는 이제 필요없다. 메모리 해제를 해준다.
lastNode 갱신
삽입 시에는 advanceLastNode()로, 삭제 시에는 retreatLastNode()로 lastNode의 위치를 갱신해주었다.
힙이 배열로 구성되어 있다면야 index를 1늘리거나 1을 줄이는 방식으로 굉장히 편리해진다. 허나, 노드가 서로의 포인터로 연결되어 구현된 것이라면 생각을 조금 해야하는 포인트가 있다.
lastNode의 갱신 작업의 두 가지는 모두 O(log N)개의 노드를 순회함으로써 갱신 위치를 찾는다.
advanceLastNode
삽입 시에 advanceLastNode를 통해 insertNode의 위치를 잡아주었다. (함수명은 꼭 advance가 아니어도 된다. findIsertNodePos 라던지 뭐 등등..)
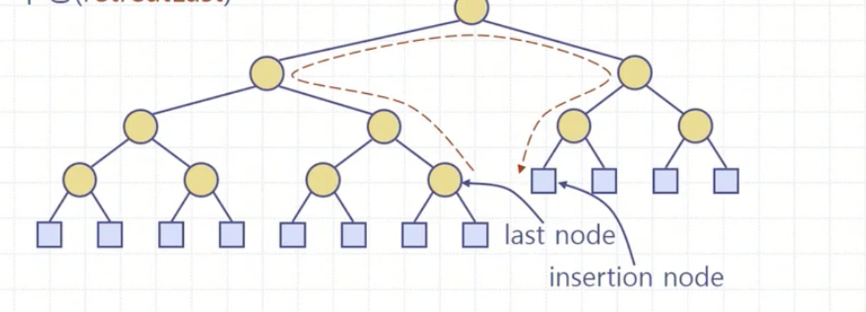
- 현재 노드가 오른쪽 자식인 동안, 노드의 parent로 이동한다.
- 현재 노드가 왼쪽 자식인 경우, 노드의 sibling으로 이동한다.
- 현재 노드가 내부노드인 동안, 왼쪽 자식으로 이동한다.
- 외부노드를 만나면 멈춘다. 이 자리가 insert할 위치가 된다.
retreatLastNode
삭제하기 위한 노드 갱신은 advanceeLastNode의 반대로 한다.
- 현재 노드가 왼쪽 자식인 동안, 노드의 parent로 이동한다.
- 현재 노드가 오른쪽 자식인 경우, 노드의 sibling으로 이동한다.
- 현재 노드가 내부노드인 동안, 오른쪽 자식으로 이동한다.
- 외부노드를 만나면 그 parent를 lastNode로 지정한다.
배열 힙 구현
힙은 사실 배열로 구현하면 구현 난이도가 상당히 쉬워진다. 노드를 축소하거나 확장해줄 필요도 없고 lastNode의 갱신도 매우 쉬워진다.
배열 힙의 핵심은 어떠한 idx에 대하여 왼쪽 자식은 idx*2, 오른쪽 자식은 idx*2 + 1이고, 어떠한 idx에 대하여 부모는 idx/2다. 따라서 배열의 0번째 인덱스는 사용하지 않는다.
lastNode idx가 N이라면, 삽입 시에 N+1에 삽입하고, 삭제시에 N을 삭제후 위치를 N-1로 해준다.
성능
힙에 대한 연결리스트 구현과 배열 구현을 알아보았다(연결리스트 얘기가 90%이긴 하지만.).
두 힙 구조에 대한 성능의 공통점과 차이점이 있다.
공통점은 힙 사이즈, 힙이 비어있는지 확인 작업, 최소키 원소 확인 작업 모두 O(1)이고, insert, remove 모두 O(logN)이다.
차이점은 lastNode 갱신에 있다. 연결리스트의 갱신은 O(logN)이지만, 배열의 갱신은 O(1). 상수 시간이다.
다음 포스트는 이 힙 자료구조를 이용한 heap sort에 대해 다룰 것이다.
참고 : 국형준. 알고리즘 원리와 응용. 21세기사, 2018.
