Chapter1. 컴퓨터 구조
Chapter1-1. 컴퓨터의 구조와 특징
Chapter1-2. CPU와 Memory
Chapter2. 운영체제(OS)
Chapter2-1. 운영체제
Chapter2-2. 프로세스
Chapter2-3. 스레드
Chapter3. 문자열과 그래픽
Chapter4. 가비지 컬렉션과 캐시
현대의 운영체제는 여러 프로그램을 동시에 실행해야 하고, 또한 각종 장치를 관리함.
현대의 웹 애플리케이션 역시 동시에 다양한 일을 처리해야 하는 경우가 발생한다. 그리고 다양한 일을 처리하는 일은 운영체제에서 오랫동안 고민하고 발전시킨 주제임
-> 웹 개발자에게 운영체제 지식이 필요한 이유
웹 개발의 프론트엔드 영역에서 UI를 갱신하면서 복잡한 계산이 필요하다면, 브라우저에 표시되는 과정이 느려지는 일이 발생할 수 있다. 웹 개발의 백엔드 영역에서는 다양한 요청이 하나의 데이터베이스, 또는 하나의 프로세스에 접근하면서, 하나의 데이터를 여러 요청이 동시에 수정하면서 데이터가 오염되는 문제(동시성 문제)가 발생할 수 있다. 이미 많은 애플리케이션은 이러한 문제를 풀기 위한 방법을 마련해놓고 있다. 웹 개발자는 때때로 이 방법을 그대로 사용하는 것으로 문제를 해결할 수도 있다. 그러나 이 방법을 이해하고 사용하기 위해서는, 이러한 문제를 풀기 위한 컴퓨터 공학의 이론을 알아야 한다
컴퓨터의 구조와, 2진법, 16진법에 대한 이해, 문자열을 다루는 방법, 운영체제의 프로세스, 스레드 개념을 학습해보자.
Chapter1. 컴퓨터 구조
컴퓨터는 단순히 말하자면 계산기에 가깝다. 컴퓨터는 0과 1이라는 이진수를 가지고 단순하게 계산할 뿐이지만, 이런 컴퓨터를 기반으로 한 컴퓨터 공학은 현대 정보화 사회에서 알고리즘, 계산 및 정보에 대한 이론적 연구에서부터 하드웨어와 소프트웨어의 계산 시스템 구현에 대한 실질적인 문제에 이르기까지 다양한 주제에 걸쳐 있다.
- 컴퓨터의 구조 및 기능에 대해 학습합니다.
- 데이터를 처리하는 역할인 CPU의 구조 및 성능에 대해 학습합니다.
- 명령어와 명령어 수행 과정, 처리 방식에 대해 학습합니다.
- 데이터를 저장하는 기능을 수행하는 Memory의 분류별 특성에 대해 학습합니다.
- 메모리의 성능 및 종류, 캐시 메모리에 대해 학습합니다.
Chapter1-1. 컴퓨터의 구조와 특징
컴퓨터 구조
컴퓨터는 단순하게 말하자면 하드웨어와 소프트웨어가 합쳐진 형태이다.
- 하드웨어는 전자 회로 및 기계 장치로 되어 있어 입출력 장치, 중앙처리장치(CPU), 기억장치 등으로 구성되어 있다.
- 소프트웨어는 그 하드웨어 위에서 하드웨어를 제어하며 작업을 수행하는 프로그램이다.
컴퓨터의 기본 구성 요소
컴퓨터는 키보드와 마우스로 입력을 받아들이고, 모니터를 통해 출력한다. 또한 그런 화면을 출력하기 위해 컴퓨터의 어디선가는 연산하고 있을 것이고, 필요에 따라 복사한 텍스트나 이미지 같은 것들을 기억하거나, 혹은 만들어진 파일을 영구적으로 저장하는 등의 기능 또한 하고 있다.
즉, 컴퓨터는 입력장치(Input), 출력장치(Output)가 갖춰져 있고, 내부에는 연산을 하기 위한 중앙처리장치(CPU), 저장을 하기 위한 주 기억장치와 보조 기억장치를 가지고 있다.
입력 장치
입력장치는 컴퓨터가 처리할 수 있는 형태로 데이터와 명령을 받아들이는 물리적인 장치.
기본적으로 키보드와 마우스에서부터, 스캐너와 타블렛, 혹은 조이콘 같이 컴퓨터에 연결하여 무언가를 입력할 수 있는 장치를 입력 장치라고 볼 수 있다.
출력 장치
출력장치는 처리된 데이터를 사람이 이해할 수 있는 형태로 출력하는 물리적인 장치를 의미한다.
가장 대표적인 출력장치는 모니터로, 컴퓨터에서 나오는 글자, 그림 등의 결과를 화면에 보여주는 장치이다.
모니터의 해상도는 화면에 나타나는 그림이나 글자의 선명도를 결정하는 요소인데 실제 화면의 해상도는 모니터와 그래픽 카드에 의해 결정이 된다. 그리고 프린터 또한 출력 장치에 들어가며 전자 장비에 저장되어 있는 문서를 종이 등에 인쇄하는 장치이다.
중앙처리장치
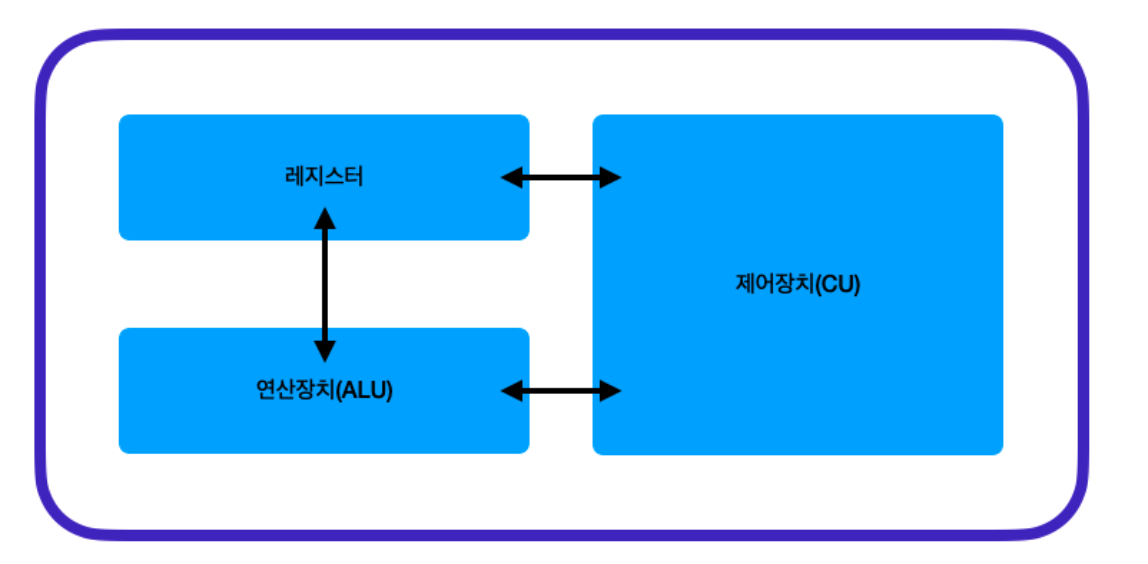
*CPU의 내부 구성은 다음과 같이 구성되어 있다.
- 산술/논리 연산 장치(ALU)
- 제어 장치
- 레지스터
산술은 덧셈을 수행하고, 제어 장치는 프로그램에 따라 명령과 제어 신호를 생성하여 각종 장치의 동작을 제어한다. 레지스터는 CPU의 내부 메모리로서, CPU에서 사용하는 데이터를 일시적으로 저장하는 장소이다.
저장 장치
저장장치는 데이터나 프로그램을 보관하기 위한 일차 기억 장치인 주 기억 장치(Memory)와 주 기억 장치를 보조하기 위한 디스크와 씨디 같은 보조 기억 장치가 존재한다.
*프로그램 수행을 위해 필요한 정보에 비해 중앙처리장치 내에 구비되어 있는 레지스터의 용량이 너무 작기 때문에, 주 기억 장치는 주로 정보를 저장해 두었다가 필요할 때 읽어들이는 저장소로 사용된다. 주 기억 장치의 종류로는 RAM과 ROM이 있다.
보조 기억 장치는 그런 주 기억 장치를 보조하기 때문에 주 기억 장치에 비해 기억된 내용을 읽는 속도는 느리지만 대용량의 기억이 가능하며 현재 사용하지 않는 프로그램은 보조 기억 장치에 저장된다
보조 기억 장치의 종류로는 플로피 디스크와 하드 디스크 같은 자기 디스크가 있고, CD와 DVD 같은 광 디스크, 그리고 USB와 SSD 같은 플래쉬 메모리가 존재.
- 프로그램 수행을 위해 필요한 정보를 중앙처리장치 내에 구비되어 있는 레지스터가 충분히 처리할 수 있지만 주 기억 장치가 레지스터가 다 처리하지 못하는 정보를 저장해 두었다가 필요할 때 읽어들이는 저장소로 사용이 됩니다.(x)
Chapter1-2. CPU와 Memory
CPU
- 컴퓨터 시스템을 이루는 구성요소는 CPU, 주기억장치(메모리), 보조 기억 장치(디스크와 씨디)
- 컴퓨터를 이루는 기본 골격 = 컴퓨터 시스템을 이루는 구성요소 + I/O(입출력장치)
이것을 제안한 사람이 폰 노이만임
폰 노이만이 제안한 폰 노이만 구조는,
중앙 처리 장치(CPU)라는 것이 있고 이 중앙 처리 장치를 통해서 연산을 수행하게 되는 구조이며, 이 CPU(중앙처리 장치)는 각종 연산을 수행하고 기억장치에 기억되어 있는 명령어들을 수행하는 컴퓨터 시스템을 이루는 핵심 부품이다.
CPU의 구조
CPU 의 내부 구성
- 산술/논리 연산 장치(ALU),
- 제어 장치
- 레지스터
산술은 덧셈을 수행하는 것, 제어 장치는 시그널을 통해서 데이터 흐름을 통제하는 것, 레지스터는 CPU 내부의 메모리임
산술/논리 연산 장치 (Arithmetic Logic Unit, ALU)
산술논리연산장치(ALU: Arithmetic Logic Unit)는 산술적인 연산과 논리적인 연산을 담당하는 장치로 가산기, 보수기, 누산기, 기억 레지스터, 데이터 레지스터 등으로 구성됨
캐시나 메모리로부터 읽어 온 데이터는 레지스터(Register)라는 CPU 전용의 기억장소에 저장되며, ALU는 레지스터에 저장된 데이터를 이용하여 덧셈, 곰셈 등과 같은 산술 연산을 수행한다.
부동소숫연산장치(FPU)와 정수연산장치, 논리연산(AND, OR 등)장치 등이 있다.
레지스터(Register)
레지스터(Register)는 중앙처리장치(CPU) 내부에 있는 기억장치
- 산술 연산 논리장치에 의해 사용되는 범용 레지스터(General-Purpose Register)
- PC 등 특수 목적에 사용되는 전용 레지스터(Dedicated-Purpose Register)
로 구분한다.
레지스터의 종류
- IR (Instruction Register) : 현재 수행 중에 있는 명령어 부호를 저장하고 있는 레지스터
- PC (Program Counter) : 명령이 저장된 메모리의 주소를 가리키는 레지스터
- AC (Accumulator) : 산술 및 논리 연산의 결과를 임시로 기억하는 레지스터
제어장치(Control Unit, CU)
제어장치는 CPU가 자신 및 주변기기들을 컨트롤하는 장치
제어장치 구성
- 프로그램의 수행 순서를 제어하는 프로그램 계수기(program counter)
- 현재 수행중인 명령어의 내용을 임시 기억하는 명령 레지스터(instruction register)
- 명령 레지스터에 수록된 명령을 해독하여 수행될 장치에 제어신호를 보내는 명령해독기(instruction decoder)
*제어 장치 구현의 방식은 고정 배선 제어(Hardwired) 방식과 Micro Program 방식이 있다.
| 고정 배선 제어(Hardwired) | Micro Program |
|---|---|
| 제어신호가 Hardwired Circuit에 의해서 생성 되도록 하드웨어를 구성하며 상태계수기와 PLA(Programmable Logic Array ) 회로로 구성 | 발생 가능한 제어 신호들의 조합을 미리 구성하여 ROM 에 저장했다가 필요 시 신호를 발생시키는 Software 방식 |
| 고속 처리, 고가 | 하드웨어 방식에 비해 속도도 낮고 가격도 저렴 |
| RISC 시스템에 적용 | CISC 에 적용 |
CPU의 기능
CPU의 기능은 명령어와 데이터에 관련이 있다.
명령어 인출 및 해독은 모든 명령어들에 대하여 공통적으로 수행하며 기억 장치로부터 명령어를 읽어온다.
그리고 데이터 인출 및 처리, 쓰기와 같은 것들은 명령어에 따라 필요할 때만 수행한다. 이 명령어 및 명령어 수행 과정과 처리 방식은 CPU에서 중요한 부분을 차지한다.
명령어
명령어는 시스템이 특정 동작을 수행시키는 작은 단위이다. 명령어는 코드로 되어 있는데, 다음과 같이 구성됨
- 동작코드(Op-code : Operational Code): 각 명령어의 실행 동작을 구분하여 표현한다.
- 오퍼랜드(Operand): 명령어의 실행에 필요한 자료나 실제 자료의 저장 위치를 의미한다.
명령어 수행 과정
CPU 가 하나의 명령(Operation)을 처리하는 과정

- 읽기(Fetch Instruction, FI): 메모리에서 명령을 가져온다.
- 해석(Decode Instruction, DI): 명령을 해석한다.
- 실행(Execute Instruction, EI): 명령을 수행한다.
- 기록(Write Back, WB): 수행한 결과를 기록한다.
명령어 처리 방식
명령어 처리 방식에는 RISC와 CISC가 있다.
- RISC(Reduced Instruction Set Computer): 컴퓨터 내부적으로 사용하는 명령어 세트를 단순화 시켜서 처리하는 형태의 구조로, 단순한 명령을 조합해서 하나의 기능을 수행함
- CISC(Complex Instruction Set Computer): 하나의 기능에 해당하는 하나의 명령이 있는 개념이라 보면 됨
CISC
- 여러 사이클로 명령어를 처리한다.
- 많은 명령어가 메모리를 참조하는 처리 방식이다.
- 파이프라이닝의 사용이 어렵다.
- 복잡한 마이크로 프로그램 구조를 갖고 있다.
RISC
- 하나의 사이클로 명령어를 처리한다.
- 메모리 Load / Store 명령만 처리하는 방식이다.
- 파이프라이닝, 슈퍼스칼라의 사용이 가능하다.
- 복잡한 컴파일러 구조를 갖고 있다.
Memory
컴퓨터에서 말하는 메모리는 기억소자 즉 반도체를 의미하는데, 반도체는 특성상 전류를 흐르게도 하고 흐르지 않게도 하는 특징이 있어 이를 이용해서 임시적인 내용들을 기억하게 만든다!
메모리 분류별 특성
기억장소라는 개념에서 확장하면,
저장 장소라는 개념의 하드디스크, CD/DVD, USB 저장장치와 같은 보조 기억장치까지를 의미한다.
이런 보조 기억장치와 메모리의 차이는 “휘발성”인데,
메모리는 시스템이 활성화 된 상태에서 그 값을 기억하고 있지만 시스템이 꺼지게 되면(ShutDown) 지워짐. 그에 비해 보조 기억장치는 시스템이 꺼져도 기억하고 있는 값이 휘발되지 않음
또한 저장/읽기 속도 면에서 메모리와 보조 기억장치는 현저하게 차이남.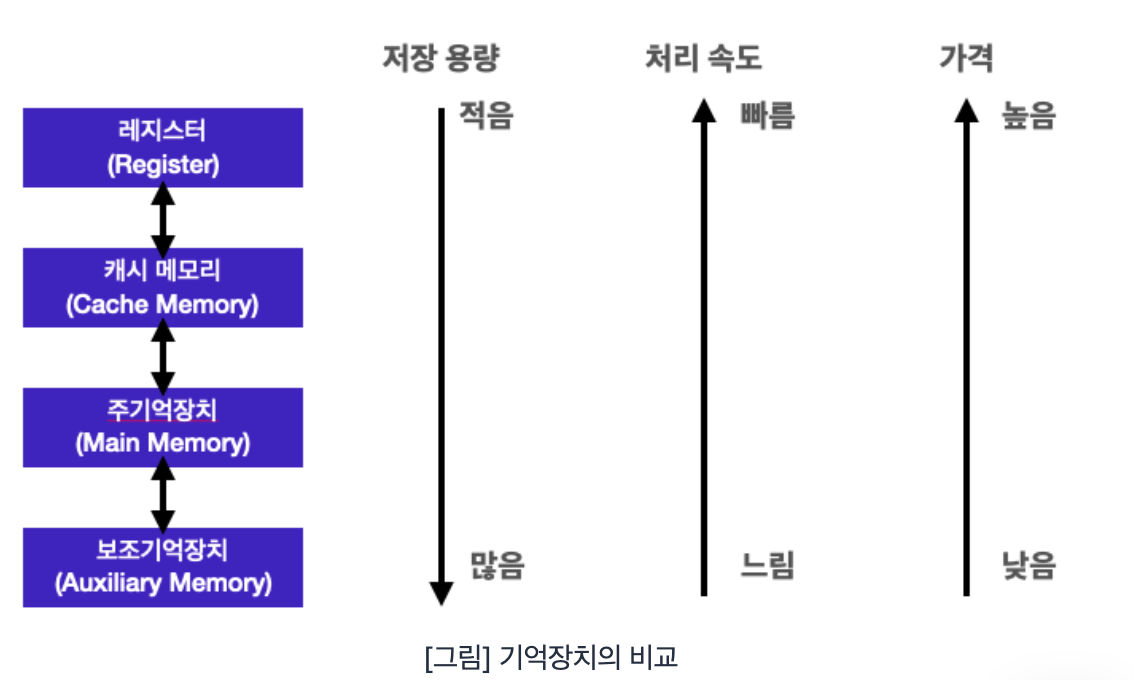
CPU 와 가장 가까이 있는 레지스터 메모리, 캐시 메모리, 주기억 장치, 보조기억 장치는 각각 그 특성에 차이가 있다.
메모리 성능
메모리의 속도는 메모리가 CPU와 데이터를 주고받는 시간을 말한다.
이를 액세스라 부르며 단위는 ns(nano-second) – 10억분의 1초로써 메모리 속도의 기준이 된다. 메모리의 성능은 속도가 빠를 수록 성능이 좋다고 말할수 있다.
- 리프레시 시간
메모리는 일정 시간마다 재충전을 해줘야 하는데, 그렇지 않으면 정보는 사라지게 됨. 이 일정기간을 리프레시 시간이라고 함. 이는 메모리에서 한번 읽고 나서 다시 읽을 수 있는 사이 시간을 말한다. - 메모리 액세스 시간
메모리 액세스 시간은 데이터를 읽어오라는 명령을 받고 데이터를 읽기 시작하기까지의 시간을 말한다. CPU에서 명령어를 처리할 때 명령어가 갖는 주소를 보낸다. 그러면 CPU에 그 주소에 해당하는 값을 가져 오게 되는데 걸리는 시간이 액세스 시간. - 사이클 시간(리프레시 시간 + 메모리 액세스 시간)
사이클 시간은 메모리 액세스 시간과 리프레시 시간을 더한 것으로, 메모리 작업이 완료와 동시에 대기 신호를 내놓은 후 다음 신호를 받을 준비가 되었다는 신호를 주기까지의 시간을 의미한다.
메모리 종류
메모리 중 주 기억 장치의 종류로는 RAM과 ROM,
보조 기억 장치의 종류로는 자기 디스크, 광디스크, 플래시 메모리가 있다.
주기억장치
RAM(Random Access Memory)
- 컴퓨터의 전원이 끊어지면 내용이 휘발되어 보조 저장 장치가 반드시 필요하다. RAM의 크기는 프로그램의 수행 속도에 영향을 준다. (RAM의 크기가 작으면 게임이 잘 돌아가지 않는 경우를 생각각.) 또한 CPU에서 직접 접근이 가능한 유일한 저장 장치이다.
- RAM 종류에는 SRAM과 DRAM이 있는데, SRAM은 리프레쉬가 필요 없고 전력 소모가 적으나 비싸며, DRAM은 리프레쉬가 필요하고 SRAM보다 저가이며 많이 사용되는 편.
ROM(Read Only Memory)
대부분 읽을 수만 있는 장치로 구성되어 있으며 전원이 끊겨도 내용이 보존이 된다.
보조기억장치
자기 디스크
- 원판 표면의 철 입자의 방향(N/S극)으로 0과 1을 표현한다. 디스크 드라이브는 자기 디스크로부터 데이터를 읽는 주변 장치를 의미한다.
- 자기 디스크에는 플로피 디스크(FDD)와 하드 디스크(HDD)가 존재한다.
광 디스크
- 광 디스크(optical disc, OD)는 빛의 반사를 이용하여 자료를 읽어내는 저장 매체.
- 1세대인 CD부터 시작해 2세대 DVD를 거쳐 3세대인 블루레이 디스크까지 존재. 차세대 디스크로는 테라 디스크나 HVD등이 존재.
플래시 메모리
- 전자적으로 데이터를 지우고 쓸 수 있는 비휘발성 메모리로 충격에 강하여 휴대용 기기에 널리 쓰임.
- 플래시 메모리에는 USB와 SSD가 존재하며, SSD는 HDD와 달리 디스크, 헤더와 같은 기계적 장치는 빠졌지만 저전력, 저소음, 저중량이라는 특징을 가지고 있다.
캐시 메모리(Cache Memory)
캐시 메모리는 CPU 내 또는 외에 존재하는 메모리로써, 메인 메모리와 CPU 간의 데이터 속도 향상을 위한 중간 버퍼 역할을 한다.
여기서 ‘Cache’라는 의미는 보관이나 저장의 의미를 가지고 있다. 캐시 메모리는 이러한 역할을 하는 물리적 장치를 말한다. CPU와 메인 메모리 사이에 존재한다고 말할 수 있는데, CPU 내에 존재할 수도 있고 역할이나 성능에 따라서는 CPU 밖에 존재할 수도 있다.
특히 빠른 CPU 의 처리속도와 상대적으로 느린 메인 메모리에서의 속도의 차이를 극복하는 완충 역할을 해준다. 쉽게 표현하면 CPU 는 빠르게 일을 진행하고 있는데, 메인 메모리가 데이터를 가져오고, 가져가는 게 느려서 캐시 메모리가 중간에 미리 CPU 에 전달될 데이터를 들고 서 있는 형태라고 생각하면됨.
캐시 메모리의 성능 결정 요소
캐시 메모리는 메인 메모리의 일정 블록 사이즈의 데이터를 담아 두었다가 CPU에 워드 사이즈 만큼의 데이터를 전송하게 됨.
이때 이 사이즈들이 캐시의 성능에 영향을 미치게 되는데. 블록사이즈나 워드 사이즈가 상대적으로 크다면 그만큼 Cache의 Hit Ratio율이 높아지기 때문.
CPU는 필요한 데이터가 Cache Memory 내에 들어와 있으면 ‘Cache Hit’라 하고,
접근하고자 하는 데이터가 없을 경우를 ‘Cache Miss’라 한다.
이러한 원하는 데이터가 있을 수도 있고 없을 수도 있는데, 이때 원하는 데이터가 Cache에 있을 확률을 ‘Hit Ratio’라 한다.
| 요소 | 내용 |
|---|---|
| Cache 크기 | Cache Memory의 Size의 크기가 크면 Hit Ratio율과 반비례 관계 |
| 인출 방식 (Fetch Algorithm) | 요구 인출(Demand Fetch): 필요 시 요구하여 인출하는 방식 선 인출(Pre-Fetch): 예상되는 데이터를 미리 인출하는 방식 |
| 쓰기 정책 (Write Policy) | Write-Through: 주기억 장치와 캐시에 동시에 쓰는 방식. Cache와 메모리의 내용이 항상 일치하며 구성 방법이 단순하다. Write-Back: 데이터 변경만 캐시에 기록하는 방식. 구성방법이 복잡하다. |
| 교체(Replace) 알고리즘 | Cache Miss 발생시 기존 메모리와 교체하는 방식. FIFO, LRU, LFU, Random, Optimal Belady’s MIN(향후 가장참조 되지 않을 블록을 교체) 등이 있다. |
| 사상(Mapping) 기법 | 주기억장치의 블록을 적재할 캐시 내의 위치를 지정하는 방법 직접 매핑(direct mapping), 어소시에이티브 매핑(associative mapping), 셋 어소시에이티브 매핑(set associative mapping) 등이 있다. |
표와 같이 캐시 메모리의 성능 결정 요소에는 캐시의 크기 뿐 아니라 다양한 요소들이 관여하고 있다.
Chapter2. 운영체제(OS)
컴퓨터나 스마트폰의 기기 그 자체(하드웨어)는 스스로 할 수 있는 일이 없다. 하드웨어의 설계를 바탕으로 하드웨어에게 일을 시켜야만 그 의미가 있다. 하드웨어에게 일을 시키는 주체가 바로 운영체제임.
- 운영체제의 개념 및 목적, 운영체제의 기능에 대해 학습합니다.
- 운영체제의 운용 기법의 발달 과정과 종류에 대해 학습합니다.
- 프로세스의 주요개념 및 특징에 대해 학습합니다.
- 프로세서의 특징 및 프로세스와 프로세서의 차이점에 대해 학습합니다.
- 스레드의 주요개념 및 특징, 종류에 대해 학습합니다.
- 싱글스레드와 멀티스레드의 특징을 학습하고, 장단점 및 차이점을 학습합니다.
Chapter2-1. 운영체제
폰 노이만이 제시한 컴퓨터 모델에 따르면 컴퓨터 시스템은 크게 CPU, 메모리, 디스크로 구성되어 있다고 볼 수 있다.
이 각각의 하드웨어를 연결했다고 해서 우리가 원하는 프로그램을 수행할 수 있는 것은 아님. 하드웨어는 단지 그 하드웨어의 특정 기능을 수행 할 뿐인데, 이 컴퓨터라는 하드웨어 상에 프로그램들이 동작되려면 이 하드웨어들과 적절하게 데이터틀 주고 받으며 논리적인 일들을 해야만 함.
그 하드웨어에게 일을 시키는 주체가 바로 운영체제임.
운영체제의 목적 및 기능
운영체제의 목적은 처리능력 향상, 사용 가능도 향상, 신뢰도 향상, 반환 시간 단축 등에 있으며,
이런 운영체제의 기능은 여러 가지가 있다.
- 프로세서, 기억장치, 입출력장치, 파일 및 정보 등의 자원을 관리한다.
- 자원을 효율적으로 관리하기 위해 자원의 스케줄링 기능을 제공한다. 스케줄링이란 어떤 자원을 누가, 언제, 어떤 방식으로 사용할지를 결정해주는 것을 뜻한다.
- 사용자와 시스템 간의 편리한 인터페이스를 제공한다.
- 시스템의 각종 하드웨어와 네트워크를 관리하고 제어한다.
운영 체제의 시스템 자원 관리
운영체제가 없다면, 응용 프로그램이 실행될 수 없다.
응용 프로그램은 컴퓨터를 이용해 다양한 작업을 하는 것이 목적이고, 운영체제는 응용 프로그램이 하드웨어에게 일을 시킬 수 있도록 도와준다.
하드웨어를 구성하는 일을 하는 CPU, 자료를 저장하는 RAM, 디스크 등의 시스템 자원을 관리하는 주체가 바로 운영체제이다.
- 프로세스 관리(CPU)
- 메모리 관리
- I/O(입출력) 관리 (디스크, 네트워크 등)
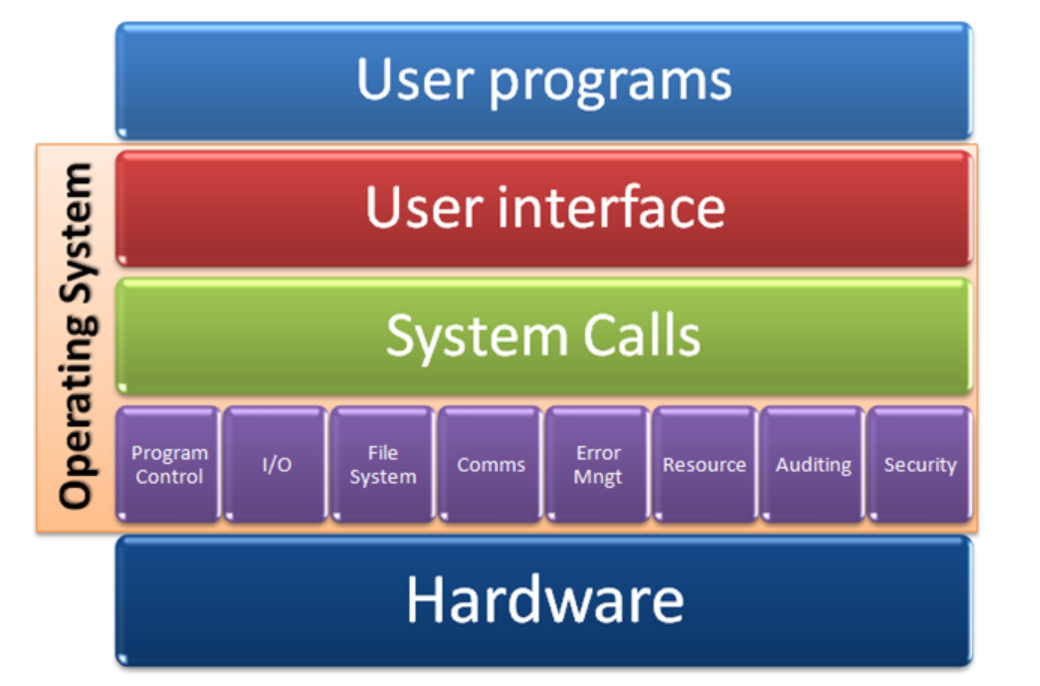
[운영체제의 구조 모식도]
응용 프로그램 관리
모든 응용 프로그램이 시스템의 자원을 마음대로 사용한다면, 해커에 의한 공격에 무방비한 상태가 된다.
악의적인 목적을 가진 프로그램이 디스크의 모든 민감한 정보에 접근하거나, 내 스마트폰의 특정 앱이 카메라를 아무 때나 실행해서 촬영한다고 생각하면 끔찍함.
따라서, 응용 프로그램은 권한에 대한 관리가 필요하다.
또한 여러 사람이 하나의 기기를 사용하는 경우에는 사용자를 관리하는 일도 매우 중요하다.
- 응용 프로그램이 실행되고, 시스템 자원을 사용할 수 있도록 권한과 사용자를 관리한다.
응용 프로그램: 운영체제를 통해 컴퓨터에게 일을 시키는 것
응용 프로그램이 운영체제를 통해 컴퓨터에게 일을 시키려면, 컴퓨터를 조작할 수 있는 권한을 운영체제로부터 부여받아야 한다. 권한을 부여받고 난 후에는, 운영체제가 제공하는 기능을 이용할 수 있다.
응용 프로그램이 운영체제와 소통하기 위해서는, 운영체제가 응용 프로그램을 위해 인터페이스(API)를 제공해야 한다. 응용 프로그램이 시스템 자원을 사용할 수 있도록, 운영체제 차원에서 다양한 함수를 제공하는 것을 시스템 콜(System call)이라고 부른다.
스마트폰에서 사용자에게 어떤 디바이스(카메라 등)의 사용을 허락받는 화면을 본 적이 있을 것. 이와 마찬가지로, 응용 프로그램 역시 운영체제가 프린터 사용을 허가해 주지 않는다면 사용할 수 없다. 워드프로세서 프로그램이 프린터를 사용해서 인쇄하기 위해서는, 워드프로세서 프로그램은 운영체제로부터 프린터 사용에 대한 권한을 부여받아야 함.
응용 프로그램이 프린터 사용에 대한 권한을 획득한 후에는, 프린터를 사용할 때 필요한 API를 호출해야 한다. 이 API는 시스템 콜로 이루어져 있다.
참고자료
공룡책 https://codex.cs.yale.edu/avi/os-book/OS10/index.html
한글문서 : https://parksb.github.io/article/5.html
Chapter2-2. 프로세스
프로세스는 프로그램이 실행 중인 상태로 특정 메모리 공간에 프로그램의 코드가 적재되고 CPU 가 해당 명령어를 하나씩 수행하고 있는 상태를 의미한다.
운영 체제에서는 프로세스를 사용하여 프로그램을 수행하게 되는데, 실행 중인 하나의 애플리케이션을 프로세스라고 부른다.
사용자가 애플리케이션을 실행하면, 운영체제로부터 실행에 필요한 메모리를 할당받아 애플리케이션의 코드를 실행한다. 이때 실행되는 애플리케이션을 프로세스라고 부른다.
예를 들어 Chrome 브라우저를 두 개 실행하면, 두 개의 프로세스가 생성된다. 이렇게 하나의 애플리케이션은 여러 프로세스(다중 프로세스)를 만들기도 한다.
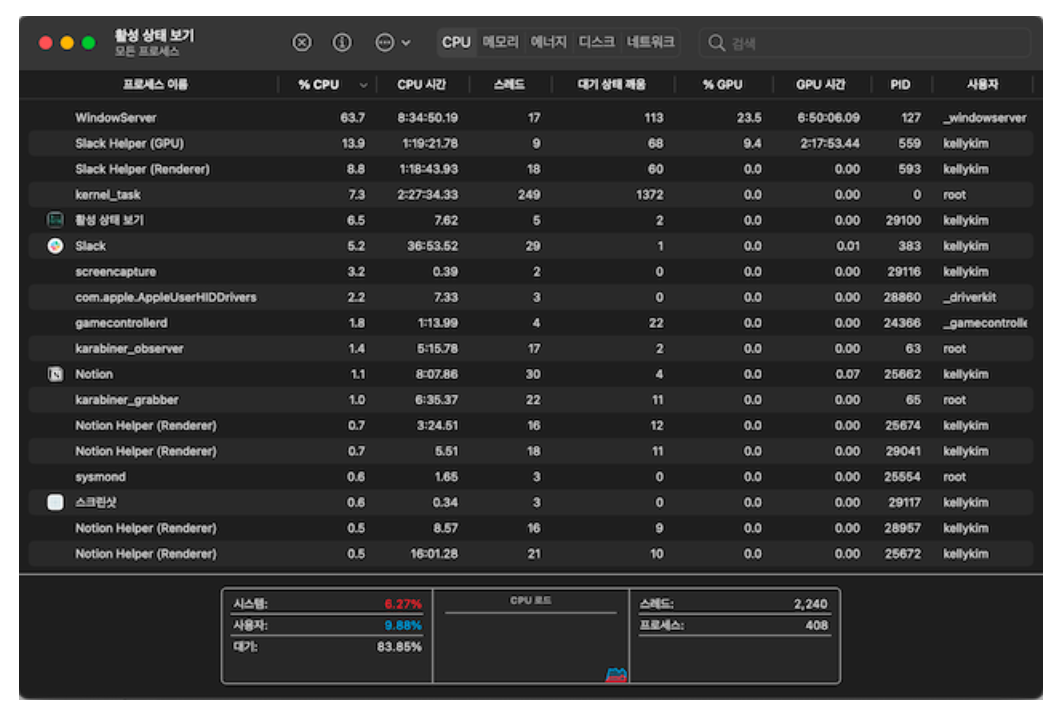
사진에서 확인할 수 있는 항목 하나하나가 전부 프로세스
*프로세스 구성 요소
프로세스의 구조체에는 프로세스마다 독립적으로 관리해야 하는 유저 메모리 영역이나 프로세스가 사용하는 각종 객체들의 포인터를 관리하는 핸들 테이블을 가지고 있다.
- 유저 메모리 영역 관리(Virtual Address Descriptors)
프로세스 별로 독립된 영역을 가지게 되는 곳은 유저 메모리 공간임.
커널 메모리 공간의 경우 모든 프로세스가 공유하여 사용하고 있다.
프로세스 별로 독립적인 유저 메모리 영역을 관리하기 위해서 VAD(Virtual Address Descriptors)라는 관리 테이블이 존재한다.
- 핸들 테이블(Handle Table)
핸들 테이블은 프로세스에서 사용하는 모든 핸들에 대한 커널 객체 포인터 정보를 배열 형태로 가지고 있는 공간.
프로세스가 종료하게 될 때 이 테이블의 정보를 참고하여 이 프로세서에서 사용하고 있는 모든 커널 객체를 자동으로 반환한다.
- 독립적인 메모리 공간
프로세스 단위로 관리되는 자원 중 가장 중요한 구별점은 가상 메모리이다. 페이징 기법을 이용하여 프로세스마다 별도의 고유한 메모리를 사용할 수 있게 하고 있다(윈도우의 경우).
*프로세스 특징
-
자원 소유의 단위
각각의 프로세스는 자신의 실행 이미지 로드와, 실행에 필요한 추가적인 메모리 공간을 가지고 있어야 한다.
이것은 각 프로세스마다 구별되어야 하며 해당 프로세스가 접근하고자 하는 파일, I/O 장치들에 대해서 또한 프로세서 단위로 할당 받아 관리되어야 합니다. -
디스패칭의 단위
프로세스는 하나의 프로그램이 운영체제로부터 CPU 의 자원을 일정 기간 동안 할당 받아 명령어를 실행하는 것이며, 운영체제는 여러 개의 프로세스가 병렬적으로 실행되게 하기 위해서 CPU 의 사용 시간을 각각의 프로세스에 골고루 나누어 주어야 한다.
하나의 프로세스에서 여러 개의 디스패칭 단위가 실행될 수 있도록 하고 있으며, 이러한 디스패칭 단위를 스레드라 부른다.
프로세스 상태
- 실행(Run) : 프로세스가 프로세서를 차지하여 서비스를 받고 있는 상태를 말한다.
- 준비(Ready) : 실행될 수 있도록 준비되는 상태를 말한다.
- 대기(Waiting) : CPU 의 사용이 아니라 입출력의 사건을 기다리는 상태를 말한다.
프로세서 VS 프로세스
프로세서와 프로세스는 엄밀히 다른 존재이다.
프로세서(Processor)
프로세서는 하드웨어적인 측면과 소프트웨어적인 측면으로 나누어 볼 수 있다.
- 하드웨어적인 측면 : 컴퓨터 내에서 프로그램을 수행하는 하드웨어 유닛으로, 중앙처리장치(CPU)를 의미하며 적어도 하나 이상의 ALU와 레지스터를 내장하고 있다.
- 소프트웨어적인 측면 : 데이터 포맷을 변환하는 역할을 수행하는 데이터 처리 시스템을 의미한다. 워드프로세서나 컴파일러 등이 여기에 속한다.
프로세스(Process)
프로세스는 특정 목적을 수행하기 위해 나열된 작업의 목록을 의미한다. 메모리에 적재 되어 프로세서에 의해 실행 중인 프로그램을 프로세스라고 볼 수 있다.
Chapter2-3. 스레드
스레드?
스레드는 명령어가 CPU 를 통해서 수행되는 객체의 단위이다.
하나의 프로세스 내에는 반드시 1개 이상의 스레드가 존재하며, 이러한 스레드는 같은 프로세스에 있는 자원과 상태를 공유한다.
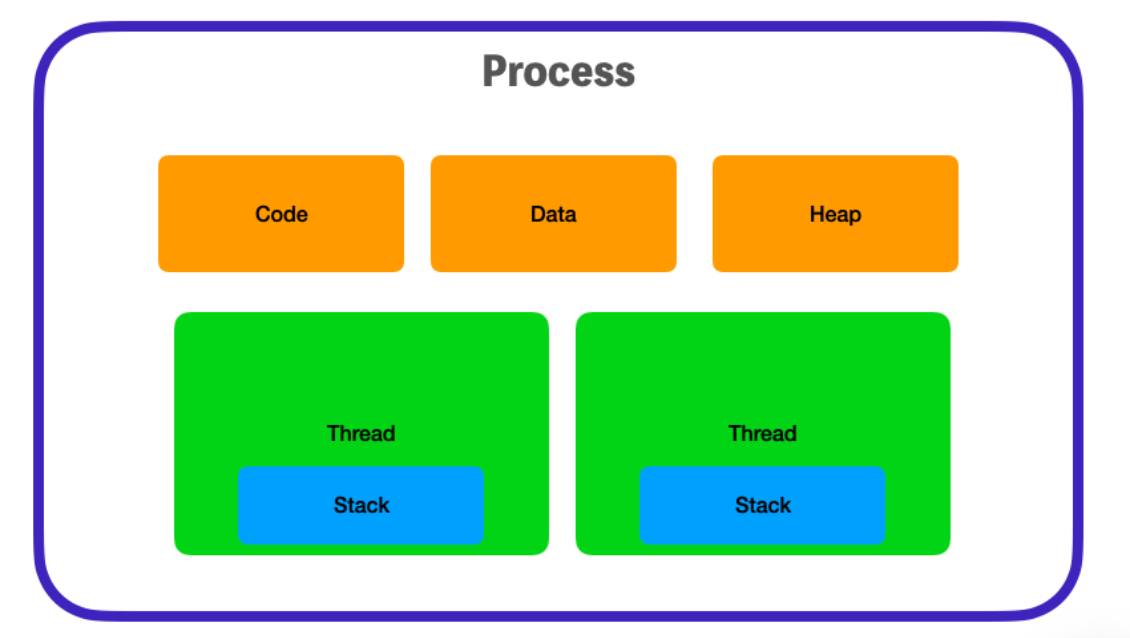
[프로세스 내에 스레드가 존재하므로 서로 자원과 상태를 공유할 수 있다.]
스레드는 왜 필요한가?
하나의 프로세스 안에서 여러 개의 루틴을 동시에 수행하여서 수행 능력을 향상하려고 할 때 스레드를 사용하게 되는데, 독립적으로 수행하여 처리하려고 할 때 사용하게 된다. 즉 여러 개의 작업 단위로 구성된 프로그램에서 요청을 동시에 처리하기 위해서이다.
예를 들어, 워드 프로세서에서 사용자로부터 키보드 입력 받거나, 그래픽 or UI를 그리고, 문법 오류를 체크하는 등 워드 프로세서 내에서 여러 요청들을 동시에 처리해야 하는데, 이때 스레드가 필요함
스레드의 구성요소
- 가상 CPU : 인터프리터, 컴파일러에 의해 내부적으로 처리되는 가상 코드.
- 수행 코드 : Thread Class에 구현되어 있는
run()Method 코드. - 처리 데이터 : Thread에서 처리하는 데이터.
스레드의 특징
- 프로세스 내에서 실행되는 흐름의 단위이다. 하나의 스레드는 시작해서 종료할 때까지 한번에 하나씩 명령들을 수행한다.
- 각 스레드마다 call stack이 존재(call stack: 실행 중인 서브루틴을 저장하는 자료 구조)하며, 나머지 Code, Data, Heap 영역은 스레드 끼리 공유한다. 반면에 프로세스는 다른 프로세스의 메모리에 직접 접근할 수 없다.
- 스레드는 다른 스레드와 독립적으로 동작한다. 독립적으로 동작하기 때문에 두 개 이상의 스레드가 동작되는 경우, 두 개 이상의 스레드의 실행 및 종료순서는 예측할 수 없다.
싱글 스레드와 멀티 스레드
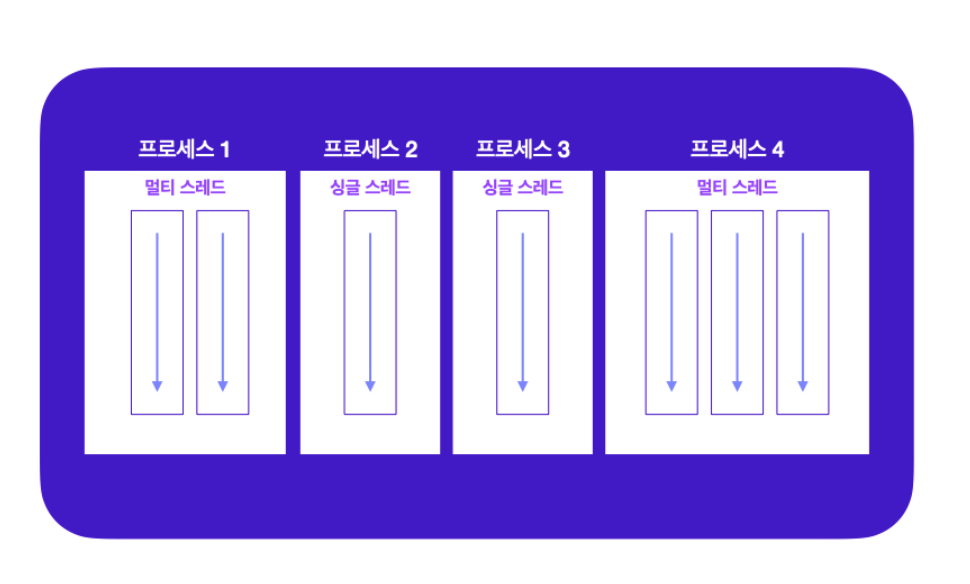
싱글 스레드(Single-Thread)
프로세스가 단일 스레드로 동작하는 방식으로 일련의 처리를 단일 스레드만으로 직렬 처리하는 프로그래밍 방법
하나의 레지스터, 스택으로 표현한다.자바스크립트가 가장 대표적인 싱글 스레드 언어이다.
싱글 스레드의 장점
- 자원 접근에 대한 동기화를 신경쓰지 않아도 된다.
- 여러 개의 스레드가 프로세스의 자원을 공유할 경우,각 스레드가 원하는 결과를 얻게 하려면 공용 자원에 대한 접근을 제어해야 한다. 쉽게 말해서, 모든 스레드가 일정 자원에 동시에 접근하거나, 똑같은 작업을 실행하려는 경우,에러가 발생하거나 원하는 값이 나오지 않는다. 그래서, 스레드들이 동시에 같은 자원에 접근하지 못하도록 제어해줘야만 한다.
- 자원 접근에 대한 동기화를 신경쓰지 않아도 되므로 문맥 교환(context switch) 작업 또한 요구하지 않는다. 문맥 교환은 여러 개의 프로세스가 하나의 프로세서를 공유할 때 발생하는 작업으로 많은 비용을 필요로 한다.
- 프로그래밍 난이도가 쉽고, CPU 메모리를 적게 사용합니다.
싱글 스레드의 단점
- 여러 개의 CPU를 활용하지 못한다.
- 싱글 스레드는 하나의 물리적 코어밖에 사용하지 못해 멀티 코어 머신에서 CPU 사용을 최적화할 수 없다. 최적화를 위해선 Cluster 모듈을 이용하여 여러 프로세스를 사용할 수 있다. 하지만 앞서 프로세스끼리의 자원 공유는 어렵기 때문에 Redis와 같은 부가 인프라가 필요하다.
- 연산량이 많은 작업을 하는 경우, 그 작업이 완료되어야 다른 작업을 수행할 수 있다.
- 싱글 스레드 모델은 에러 처리를 못하는 경우 멈춰버리게 된다. 멀티 스레드 모델은 에러 발생 시 새로운 스레드를 생성하여 극복할 수 있다.
멀티 스레드 (Multi-Thread)
일반적으로 하나의 프로세스는 하나의 스레드를 가지고 작업을 수행하게 된다.
그러나, 멀티 스레드(multi thread)란 하나의 프로세스 내에서 둘 이상의 스레드가 동시에 작업을 수행하는 것을 의미한다.
또한, 멀티 프로세스(multi process)는 여러 개의 CPU를 사용하여 여러 프로세스를 동시에 수행하는 것을 의미한다.
시스템 자원의 활용 극대화 및 처리량을 증대할 수 있어 단일 프로세스 시스템의 효율성을 높일 수 있다.
멀티 스레딩의 장점
- 싱글 스레드인 경우, 작업이 끝나기 전까지 사용자에게 응답하지 않지만 반면 멀티스레드인 경우 작업을 분리해서 수행하므로 실시간으로 사용자에게 응답할 수 있다.
- 싱글 스레드인 경우 한 프로세스는 오직 한 프로세서에서만 수행 가능하지만 반면 멀티 스레드인 경우 한 프로세스를 여러 프로세서에서 수행할 수 있으므로 훨씬 효율적이다.
멀티 스레딩의 문제점
- 주의 깊은 설계가 필요하며, 디버깅이 까다롭다.
- 단일 프로세스 시스템의 경우 효과를 기대하기 어려우며 다른 프로세스에서 스레드를 제어할 수 없다. (즉, 프로세스 밖에서 스레드 각각을 제어할 수 없다.)
- 멀티 스레드의 경우 자원 공유의 문제가 발생합니다. 하나의 스레드에 문제가 발생하면 전체 프로세스가 영향을 받게 된다.
- 문맥 교환 작업을 요구한다. CPU에서 여러 프로세스를 돌아가면서 작업을 처리하는 데 이 과정을 문맥 교환(Context Switching)이라 한다. 문맥 교환이란 다른 태스크(프로세스, 스레드)가 시작할 수 있도록 이미 실행 중인 태스크(프로세스, 스레드)를 멈추는 것을 말한다.
관련 키워드
- 데드락(Deadlock, 교착 상태)
- 뮤텍스(Mutex), 세마포어(Semaphore)
동시성과 병렬성의 차이
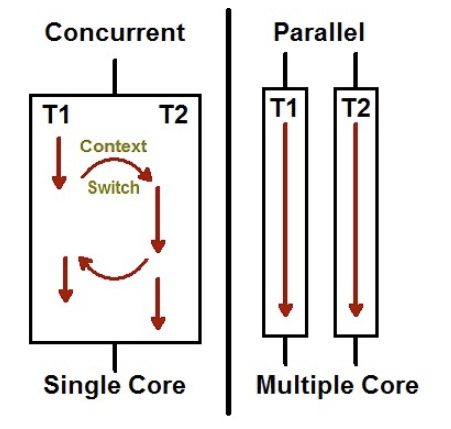
동시에 돌릴 수 있는 스레드 수는 컴퓨터에 있는 코어 개수로 제한된다.
운영체제(또는 가상 머신)는 각 스레드를 시간에 따라 분할하여, 여러 스레드가 일정 시간마다 돌아가면서 실행되도록 한다. 이런 방식을 시분할이라고 한다.
- Concurrency(동시성, 병행성): 여러 개의 스레드가 시분할 방식으로 동시에 수행되는 것처럼 착각을 불러일으킴
- Parallelism(병렬성): 멀티 코어 환경에서 여러 개의 스레드가 실제로 동시에 수행됨
Chapter3. 문자열과 그래픽
컴퓨터 과학은 이론적인 부분과 실용적인 부분으로 나뉘어져 있으나 컴퓨터가 받아들이는 기본적인 언어는 프로그래밍 언어이고, 프로그래밍 언어로 다룰 수 있는 가장 기본적인 소스인 문자열과 그래픽에 대해서 알아둘 필요가 있다.
- 문자열을 다루는 기본적인 방식을 학습합니다.
- 문자열의 종류 및 특징에 대해 학습합니다.
- 그래픽의 기본적인 개념에 대해 학습합니다.
- 비트맵(래스터)과 벡터 이미지의 특징 및 차이점에 대해 학습합니다.
문자열
2010년도 이후, 우리는 유니코드라고 불리는 인코딩 방식이 통일된 시대를 살아가고 있다. 문자열을 다루는 디테일한 방식에 대해 전부 알 필요는 없지만, 프로그래밍 언어마다 문자열을 다루는 자료형의 차이를 이해하기 위해 문자열을 다루는 기본적인 방식은 알고 있어야 한다.
문자열 하나는 몇 바이트인가요?
영어의 경우 알파벳 하나가 1 바이트(byte)를 차지하는 시절이 있었다. 그러나 글로벌 시대에는 유니코드를 사용해야 텍스트를 정확하게 저장할 수 있다.
프로그래밍 언어마다 문자열을 저장하는 자료형이 다 다르므로, "문자열 하나가 몇 바이트인가?"에 대한 답변은 이 자료형이 차지하고 있는 바이트를 이해할 때 답변할 수 있다.
유니코드는 무엇인가요?
유니코드(Unicode)는 유니코드 협회(Unicode Consortium)가 제정하는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준
이 표준에는 ISO 10646 문자 집합, 문자 인코딩, 문자 정보 데이터베이스, 문자를 다루기 위한 알고리즘 등을 포함하고 있다.
유니코드가 탄생하기 이전에는, 같은 한글이 적힌 텍스트 파일이라도 표현하는 방법이 제각각이었다. 어떤 파일이, 지원하지 않는 다른 인코딩 형식으로 저장되어 있는 경우에는 파일을 제대로 불러올 수 없었다. 기본적으로 유니코드의 목적은 현존하는 문자 인코딩 방법을 모두 유니코드로 교체하는 것임.
인코딩(부호화)이란?
인코딩이란 어떤 문자나 기호를 컴퓨터가 이용할 수 있는 신호로 만드는 것
이 신호를 입력하는 인코딩과 문자를 해독하는 디코딩을 하기 위해서는 미리 정해진 기준을 바탕으로 입력과 해독이 처리되어야 함.
이렇게 인코딩과 디코딩의 기준을 문자열 세트 또는 문자셋(charset)이라고 한다. 이 문자셋의 국제 표준이 유니코드.
ASCII 문자는 무엇인가요?
영문 알파벳을 사용하는 대표적인 문자 인코딩으로 7 비트로 모든 영어 알파벳을 표현할 수 있다.
52개의 영문 알파벳 대소문자와, 10개의 숫자, 32개의 특수 문자, 그리고 하나의 공백 문자를 포함한다.
유니코드는 ASCII를 확장한 형태이다.
UTF-8과 UTF-16의 차이점은 무엇인가요?
UTF-8과 UTF-16은 인코딩 방식의 차이를 의미한다.
UTF-8은 Universal Coded Character Set + Transformation Format – 8-bit의 약자로, UTF- 뒤에 등장하는 숫자는 비트(bit)이다.
1. UTF-8 특징: 가변 길이 인코딩
UTF-8은 유니코드 한 문자를 나타내기 위해 1 byte(= 8 bits)에서 4 bytes까지 사용한다.
- 원리
예를 들어,코라는 문자의 유니코드는U+CF54(16진수, HEX)로 표현된다.
이 문자를 이진법(binary number)으로 표시하면, 1100-1111-0101-0100 이 된다. 이 문자를 UTF-8로 표현하면, 다음과 같이 3byte의 결과로 표현된다.
1110xxxx 10xxxxxx 10xxxxxx # x 안에 순서대로 값을 채워넣습니다.
11101100 10111101 10010100[데이터] UTF-8로 표현된 '코'
let encoder = new TextEncoder(); // 기본 인코딩은 'utf-8'
encoder.encode('코') // Uint8Array(3) [236, 189, 148]
(236).toString(2) // "11101100"
(189).toString(2) // "10111101"
(148).toString(2) // "10010100"[코드] '코'라는 문자를 UTF-8로 표현할 수 있다.
ASCII 코드는 7비트로 표현되고, UTF-8에서는 다음과 같이 1 byte의 결과로 만들 수 있다. 다음 예제는 b 라는 문자를 UTF-8로 인코딩한 결과다.
0xxxxxxx
01100010 encoder.encode('b') // Uint8Array [98]
(98).toString(2) // "1100010"이처럼, UTF-8은 1 byte에서 4 bytes까지의 가변 길이를 가지는 인코딩 방식이다.
네트워크를 통해 전송되는 텍스트는 주로 UTF-8로 인코딩된다. 사용된 문자에 따라 더 작은 크기의 문자열을 표현할 수 있기 때문. ASCII 문자는 1 바이트만으로 표현 가능한 것처럼,,
UTF-8은 ASCII 코드의 경우 1 byte, 크게 영어 외 글자는 2byte, 3byte, 보조 글자는 4byte를 차지합니다. 이모지는 보조 글자에 해당하기 때문에 4byte가 필요함.
2. UTF-8 특징: 바이트 순서가 고정됨
UTF-16에 비해 바이트 순서를 따지지 않고, 순서가 정해져 있다.
3. UTF-16 특징: 코드 그대로 바이트로 표현 가능, 바이트 순서가 다양함
UTF-16은 유니코드 코드 대부분(U+0000부터 U+FFFF; BMP) 을 16 bits로 표현한다.
대부분에 속하지 않는 기타 문자는 32 bit(4 bytes)로 표현하므로 UTF-16도 가변 길이라고 할 수 있으나, 대부분은 2 바이트로 표현한다.
U+ABCD라는 16진수를 있는 그대로 이진법으로 변환하면 1010-1011-1100-1101 이다. 이 이진법으로 표현된 문자를 16 bits(2 bytes)로 그대로 사용하며, 바이트 순서(엔디언)에 따라 UTF-16의 종류도 달라진다.
즉, UTF-8에서는 한글은 3 바이트, UTF-16에서는 2 바이트를 차지한다.
그래픽
비트맵(Bitmap)과 벡터(Vector)는 디지털 이미지의 종류이다.
디지털 이미지, 또는 이미지라고 불리는 용어는 디지털 카메라를 이용하여 현실세계의 사물을 촬영하거나 스캐너를 이용하여 사진이나 그림을 디지털 형태로 받아들인 것을 가리킨다.
서로 상반된 방식으로 이미지를 표현하기 때문에 비트맵(Bitmap)과 벡터(Vector)는 큰 차이점이 있다.
비트맵
비트맵(Bitmap)은 웹 상에서 디지털 이미지를 저장하는 데에 가장 많이 쓰이는 이미지 파일 포맷 형식이다.
일반적으로는 래스터 그래픽(점 방식)이라고 한다.
이미지의 각 점들을 격자형의 픽셀 단위로 구성되며, 한 지역을 차지하는 셀은 위치에 따라 다른 값을 갖는다.
이런 비트맵은 사각의 픽셀 형태로 모여 있기 때문에 확대를 하면 ‘계단현상’ 또는 ‘깨짐 현상’이 발생하며, 경계가 뚜렷하지 않다는 특징이 있다.
이런 식으로 픽셀 단위로 이미지를 표현하는 방식은 컴퓨터에게 부담을 덜 주는 구조로 되어 있다. 또한 픽셀 하나 당 모두 색상 값을 가지고 있다. 따라서 이미지의 사이즈가 커질수록 용량 또한 무거워진다는 특징이 있다.
벡터
벡터(Vector)는 비트맵과는 완전히 다른 방식으로 이미지를 표현한다. 비트맵이 격자형의 픽셀 단위로 이미지를 구성한다면 벡터는 이미지를 수학적인 공식으로 표현을 한다.
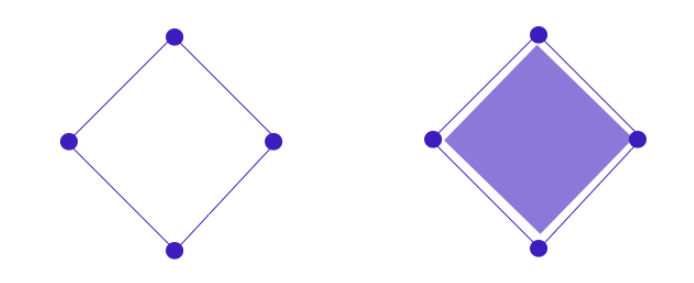
점과 점을 연결해 선을 표현하고 선과 선을 연결해 면을 표현하는 식의 수학적 원리로 그림을 그리기 때문에 비트맵과는 달리 아무리 확대를 해도 ‘계단현상’ 또는 ‘깨짐 현상’이 발생하지 않다.
그러나 그렇기 때문에 벡터 방식으로 이미지를 표현하는 것은 비트맵에 비해 컴퓨터에게 부담을 가하는 방식이므로 주로 도형, 글자 등을 그리는 작업에 사용된다.
또한 수학적인 연산으로 만들어진 이미지이기 때문에 사이즈를 키워도 용량에는 변화가 없다는 특징 또한 있다.
비트맵(래스터)과 벡터 이미지의 차이점

| 구분 | 비트맵(래스터) | 벡터 |
|---|---|---|
| 기반 기술 | 픽셀 기반 | 수학적으로 계산된 Shape 기반 |
| 특징 | 사진과 같이 색상의 조합이 다양한 이미지에 적합 | 로고, 일러스트와 같이 제품에 적용되는 이미지에 적합 |
| 확대 | 확대에 적합하지 않음, 보다 큰 사이즈의 이미지가 필요할 때 사용하려는 크기 이상으로 생성하거나 스캔해야 함 | 품질 저하 없이 모든 크기로 확대 가능하며, 해상도의 영향을 받지 않음 |
| 크기(dimension)에 따른 파일 용량(file size) | 큰 크기의 이미지는, 큰 파일 사이즈를 가짐 | 큰 크기의 벡터 그래픽은 작은 파일 사이즈를 유지할 수 있음 |
| 상호 변환 | 이미지의 복잡도에 따라 벡터로 변환하는 것에 오랜 시간이 걸림 | 쉽게 래스터 이미지로 변환 가능 |
| 대표적인 파일 포맷 | jpg, gif, png, bmp, psd | svg, ai |
| 웹에서의 사용성 | jpg, gif, png 등이 널리 쓰임 | svg 포맷은 현대의 브라우저에서 대부분 지원 |
Chapter4. 가비지 컬렉션과 캐시
- 가비지 컬렉션은 무엇이고, 가비지 컬렉션을 가진 언어가 무엇인지 학습합니다.
- 대표적인 가비지 컬렉션의 방법에 대해 학습합니다.
- 캐시의 개념과 작동 원리에 대해 학습합니다.
- 캐시의 장점과 적용 예제에 대해 학습합니다.
가비지 컬렉션
1. 가비지 컬렉션은 무엇이며, 가비지 컬렉션 기능을 가진 언어는 무엇인가요?
가비지 컬렉션은 프로그램에서 더 이상 사용하지 않는 메모리를 자동으로 정리하는 것이다. 이 기능을 가진 언어(혹은 엔진)는 자바, C#, 자바스크립트 등이 있다.
2. 대표적인 가비지 컬렉션의 방법은 무엇이 있나요?
-
트레이싱: 한 객체에 flag를 두고, 가비지 컬렉션 사이클마다 flag에 표시 후 삭제하는 mark and sweep 방법.
- 객체에 in-use flag를 두고, 사이클마다 메모리 관리자가 모든 객체를 추적해서 사용 중인지 아닌지를 표시(mark)한다. 그 후 표시되지 않은 객체를 삭제(sweep)하는 단계를 통해 메모리를 해제한다.
-
레퍼런스 카운팅: 한 객체를 참조하는 변수의 수를 추적하는 방법.
- 객체를 참조하는 변수는 처음에는 특정 메모리에 대해 레퍼런스가 하나뿐이지만, 변수의 레퍼런스가 복사될 때마다 레퍼런스 카운트가 늘어난다.
- 객체를 참조하고 있던 변수의 값이 바뀌거나, 변수 스코프를 벗어나면 레퍼런스 카운트는 줄어든다. 레퍼런스 카운트가 0이 되면, 그 객체와 관련한 메모리는 비울 수 있다. 레퍼런스 카운트가 0이 된다는 말은 아무도 그 객체에 대한 레퍼런스를 가지고 있지 않다는 말과 같다.
-
질문
- 크롬 브라우저 및 node.js의 v8 엔진은, 어떻게 가비지 컬렉팅을 하고 있나요?
- Memory terminology를 읽어보세요.
웹 서비스에서의 캐시
1. 캐시란 무엇인가요?
많은 시간이나 연산이 필요한 작업의 결과를 저장해두는 것을 의미한다.
컴퓨팅에서 캐시는 일반적으로 일시적인(temporarily) 데이터를 저장하기 위한 목적으로 존재하는 고속의 데이터 저장 공간이다.
첫 작업 이후에 이 데이터에 대한 요청이 있을 경우, 데이터의 기본 저장 공간에 접근할 때보다 더 빠르게 요청을 처리할 수 있다.
캐싱을 사용하면 이전에 검색하거나 계산한 데이터를 효율적으로 재사용할 수 있다.
2. 캐시의 일반적인 작동원리
캐시의 데이터는 일반적으로 RAM(Random Access Memory)과 같이 빠르게 액세스할 수 있는 하드웨어에 저장되며, 소프트웨어 구성 요소와 함께 사용될 수도 있다.
캐시는 기본 스토리지 계층(SSD, HDD)에 액세스하여 데이터를 가져오는 더 느린 작업의 요구를 줄이고, 데이터 검색의 성능을 높인다.
속도를 위해 용량을 절충하는 캐시는 일반적으로 데이터의 하위 집합을 일시적으로 저장한다. 완전하고 영구적인 데이터가 있는 데이터베이스와는 대조적이다.
3. 캐시의 장점은 무엇인가요?
- 애플리케이션 성능 개선
- 데이터베이스 비용 절감
- 백엔드 부하 감소
- 예측 가능한 성능
- 데이터베이스 핫스팟 제거
- 읽기 처리량 증가
- 읽기 처리량: IOPS; Input/output operations per second. HDD, SSD 등의 컴퓨터 저장 장치의 성능 측정 단위
- 디스크를 사용하는 데이터베이스에 비해, 주로 인메모리를 사용하는 캐시 때문에 더 빠른 읽기 작업을 할 수 있다.
4. 웹서비스에서 캐시가 적용되는 예제로는 어떤 것들이 있나요?
- 클라이언트: HTTP 캐시 헤더, 브라우저
- 네트워크: DNS 서버, HTTP 캐시 헤더, CDN, 리버스 프록시
- 서버 및 데이터베이스: 키-값 데이터 스토어(e.g. Redis), 로컬 캐시(인-메모리, 디스크)
Reference
https://aws.amazon.com/ko/caching/
퀴즈
CPU의 명령어 수행 과정
명령어 수행 과정에서 처음에는 메모리에서 명령을 가져오는 것으로, 읽기(FI)에 해당.
그리고 가져온 명령어를 해석해야 하는데, 이 과정을 해석(DI) 과정이라고 한다.
이어 해석이 완료된 명령을 수행하는데, 이를 실행(EI)이라 한다.
마지막으로 수행한 결과를 기록하는데, 이를 기록(WB)이라 합니다.
메모리의 분류별 특성
- 캐시 메모리(Cache Memory)는 레지스터(Register)에 비해 처리 속도가 느리다.
- 주 기억장치는 보조 기억장치에 비해 가격이 높다.
스레드
- 프로세스는 각각 독립된 메모리 영역(Code, Data, Stack, Heap의 구조)을 할당받습니다. 할당 받을 시에, 스레드는 프로세스 내에서 각각 Stack만 따로 할당받고 Code, Data, Heap 영역은 공유한다.
- 스레드는 다른 스레드와 독립적으로 작동한다.
- 싱글 코어에서 동시에 돌릴 수 있는 스레드 수는 한 개뿐이다
가비지 컬렉션
가비지 컬렉션은 개발자가 직접 메모리를 다룰 때에 생길 수 있는 메모리 누수를 방지할 수 있다.
UTF-8에서 한글은 보통 3바이트를 사용한다.
프로그램과 프로세스, 스레드
- 하나의 프로그램이 여러 프로세스를 가질 수 있습니다.
- 프로세스는 프로그램이 메모리에 적재되어 운영체제로부터 필요한 공간, 파일, 메모리를 할당받는다.
- node.js는 싱글 스레드로만 작동한다.(x)
- node.js의
Event loop는 싱글 스레드로 작동되지만,Worker pool은 멀티 스레드로 작동된다. - 즉, node.js의 초기화와 callback은
Event loop라는 하나의 프로세스, 하나의 스레드에서 작동되지만 I/O intensive, CPU intensive한 모듈은Worker pool에서 작동한다.
- node.js의
운영체제에는 커널이라는 것이 존재한다. 컴퓨터 과학에서 커널(kernel)은 컴퓨터 운영 체제의 핵심이 되는 컴퓨터 프로그램으로, 시스템의 모든 것을 완전히 통제한다.
운영 체제의 다른 부분 및 응용 프로그램 수행에 필요한 여러 가지 서비스를 제공하는 부분이므로, 해당 개념도 정리하자!!
