Chapter1. GraphQL
Chapter2. GraphQL 다루기
Chapter1. GraphQL

GraphQL은 페이스북에서 만든 쿼리 언어. 2016년 처음으로 등장해 현재까지 인지도 및 만족 부분에서 높은 비율을 차지하고 있는 언어
- GraphQL의 특징에 대해서 학습합니다.
- GraphQL과 REST API를 비교하여 장단점을 파악하고 이해합니다.
GraphQL
GraphQL은 Facebook에서 처음으로 개발했고, 오픈 소스로 제공된 쿼리 언어이다.
Graph + Query Language의 줄임말로 Query Language 중에서도 Server API 를 통해 정보를 주고받기 위해 사용하는 Query Language를 뜻한다. 쉽게 말해 API를 위한 쿼리 언어라고 할 수 있다.
왜 Graph를 사용하나요?
GraphQL의 아이디어는 그래프로 생각하기에서부터 출발한다. 그래프라는 자료구조는 인간의 뇌 구조 및 언어적인 설명과 비슷하기 때문에 실제 현실 세계의 많은 현상들을 모델링할 수 있는 강력한 도구임
따라서 그래프 자료구조를 살펴보면 우리가 특정 개념을 학습하고 이를 다른 개념과 연관시킬 때 자연스럽게 사용하는 마인드맵과 유사한 데이터 구조를 가진다는 것을 알 수 있다.
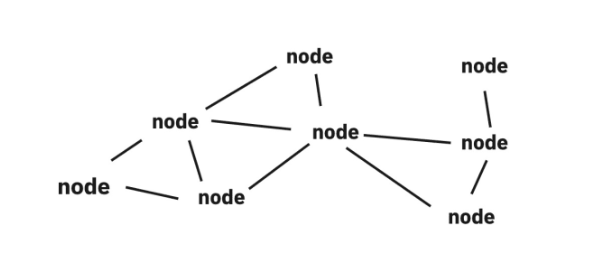
그래프는 여러 개의 점들이 서로 복잡하게 연결되어 있는 관계를 표현한 자료구조를 뜻한다. 하나의 점을 그래프에서는 Node 또는 정점(vertex)이라고 표현하고, 하나의 선은 간선(edge) 이라고 한다.
직접적인 관계가 있는 경우 두 점 사이를 이어주는 선이 있으며 간접적인 관계라면 몇 개의 점과 선에 걸쳐 이어진다. 또한 각 노드간의 간선을 통해 특정한 순서에 따라 그래프를 재귀적으로 탐색할 수 있다.
그래프 자료구조와 트리 자료구조의 차이
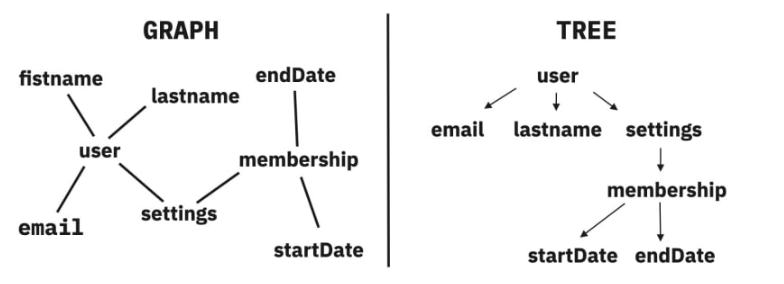
GraphQL에서는 모든 데이터가 그래프 형태로 연결되어 있다고 전제한다. 일대일로 연결된 관계도, 여러 계층으로 이루어진 관계도 모두 그래프이다. 트리나 그래프나 노드와 노드를 연결하는 간선으로 구성된 자료구조인데, 단지 그 그래프를 누구의 입장에서 정렬하느냐(클라이언트가 어떤 데이터를 필요로 하느냐)에 따라 트리 구조를 이룰 수 있다.
트리 구조로 정렬된 그래프와 GraphQL
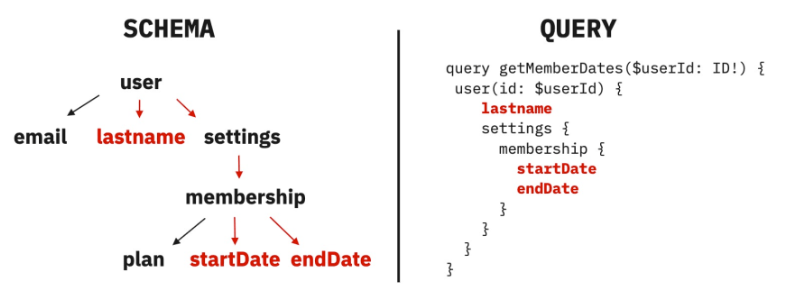
이를 통해 GraphQL은 클라이언트 요청에 따라 유연하게 트리 구조의 JSON 데이터를 응답으로 전송할 수 있다.
다시 말해 GraphQL은 REST API 방식의 고정된 자원이 아닌 클라이언트 요청에 따라 유연하게 자원을 가져올 수 있다는 점에서 엄청난 이점을 갖는다.
GraphQL로 그래프 순회
GraphQL로 그래프를 순회하기 위해 도서관의 도서 목록 시스템을 구축한다고 가정해보자.
하나의 도서 목록에는 많은 책과 저자가 있을 것이며, 각 책에는 최소한 한 명의 저자가 있다. 또한 최소한 한 권의 책을 같이 쓴 공동저자 또한 있을 것이다.
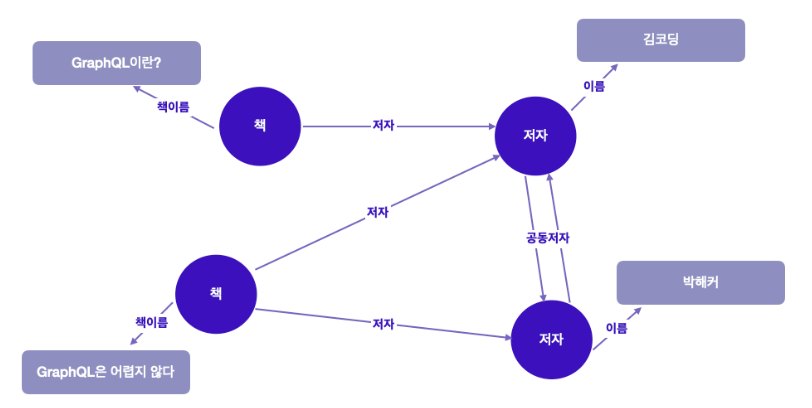
위의 그래프는 예시에서 설명한 관계를 그래프 형태로 시각화한 것이다. 이런 식으로 그래프로 표현하게 되면 우리가 가지고 있는 데이터의 조각들이나 나타내고자 하는 엔티티(책, 혹은 저자) 간의 관계를 나타낼 수 있다.
엔티티는 사물의 구조나 상태, 동작 등을 모델로 표현하는 경우, 그 모델의 구성요소를 말한다. 예를 들어 학생이라는 객체는 “학번”, “이름”, “학과”라는 3개의 속성으로 구성되어 있는 것처럼, 위의 엔티티는 책이라는 객체가 존재한다면 “책이름"이라는 1개의 속성으로 구성되어 있는 셈.
정보의 측면에서 볼 때 이 속성은 그 자체만으로는 중요한 의미를 표현하지 못하기 때문에 단독으로 존재하지는 못한다. 앞의 예에서 각 속성들 즉 “학번”, “이름”, “학과”는 개별적으로는 우리에게 어떤 정보를 제공해 주지 못하지만 이것들이 모여 “학생”이라는 객체를 구성해서 표현할 때는 큰 의미를 제공할 수 있게 됨.
이렇게 그래프를 그릴 수 있게 된다면, GraphQL을 사용해 트리를 추출할 수 있게 된다.
기본적으로 트리는 방향성은 존재하나 사이클은 존재하지 않는 비순환 그래프이다. 루트와 모서리를 통해 노드를 따라 순회할 수 있으나 동일한 노드로 돌아올 수 없는 속성을 갖고 있는 특별한 그래프임.
그래프에서 트리 추출하는 방법
위의 그래프에서 실행할 수 있는 쿼리는 다음과 같다.
query {
책(ISBN이 "9780674430006") {
책 이름
저자 {
이름
}
}
}위의 그래프는 간단하게 표현했지만 사실 책이란 객체가 가지는 속성은 책 이름 외에도 많을 것임. 따라서 한 권의 책만 검색하기 위해, ISBN이 "9780674430006인 조건을 걸어주자. 이 방식으로 서버에 요청을 보내고, 서버가 해당 요청을 해결한다면, 돌아온 쿼리는 이럴 것이다.
{
책 : {
책 이름 : "GraphQL은 어렵지 않다",
저자 : [
{ 이름 : "김코딩"},
{ 이름 : "박해커"},
]
}
}그럼 이것을 그래프의 관점에서 본다면 어떨까?
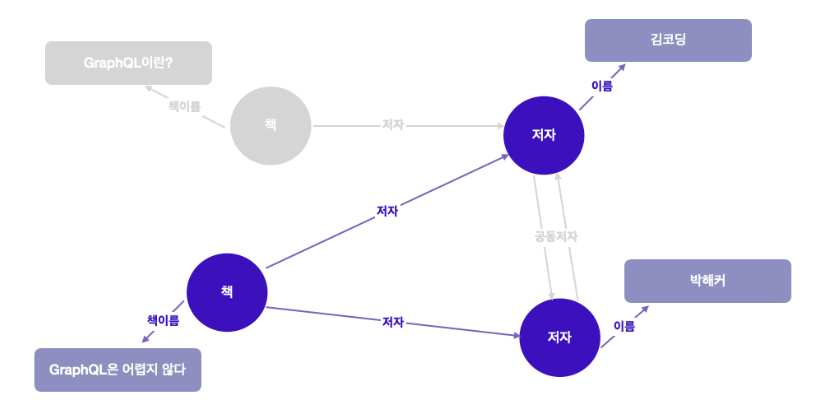
이 예에서는 ISBN 번호를 사용하여 선택한 “책" 노드에서 시작한다. 그 다음 GraphQL은 중첩된 각 필드로 표시된 간선을 따라 그래프를 탐색하기 시작한다. 즉 쿼리 내 중첩된 “책 이름” 필드를 통해 책의 제목이 있는 노드로 이동한다.
그러면서 “저자”로 레이블이 지정된 “책”의 간선을 따라가 “저자” 노드를 가져오고, 각 저자의 “이름"을 얻어오는 것. 이것을 트리 구조로 표현하면 이렇게 보임.
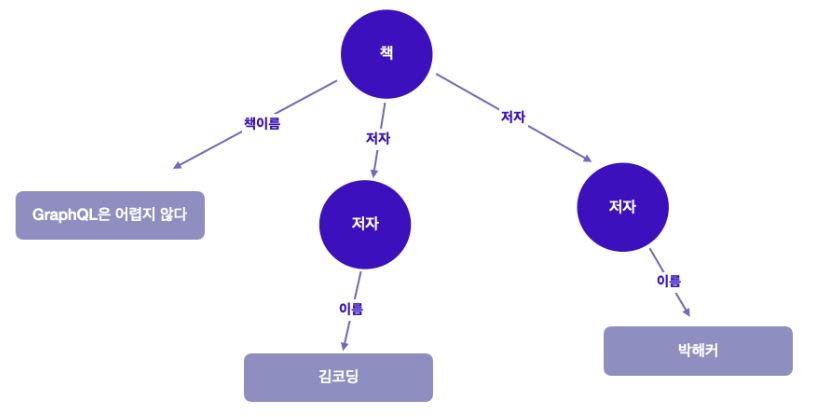
이렇게 GraphQL의 중첩된 필드를 그래프의 계층 구조로 표현하면 이렇게 트리 구조로도 표현할 수 있게 된다. 즉, GraphQL은 트리 구조로 쿼리 결과를 받기 위해 그래프를 탐색하는 쿼리 언어라고 볼 수 있다.
GraphQL의 특징
- GraphQL은 HTTP를 통해 API 서버로 요청을 보내고 응답을 받는다.
- 응답을 받을 시, 데이터 결과를 JSON 형식으로 받는다.
- GraphQL은 서버 개발자가 작성한 각 필드에 대응하는 resolver 함수로 각 필드의 데이터를 조회할 수 있다.
- GraphQL은 GraphQL 라이브러리가 조회 대상 schema가 유효한지 검사한다.
GraphQL VS REST API
GraphQL은 API를 위한 쿼리 언어라고 했다. 그렇다면 이전에 이미 REST API라는 방법론이 존재하고 있음에도 불구하고 왜 GraphQL이 탄생했을까? 예제를 통해 REST API의 한계에 대해 알아보자.
REST API의 한계

가상의 블로그 앱을 구현한다고 가정해보자. 위와 같은 화면을 구현하기 위해선 다음의 데이터가 필요함.
- 사용자의 이름
- 사용자의 포스팅 목록
- 사용자의 팔로워 목록
REST API로 Blog 앱을 구현할 때
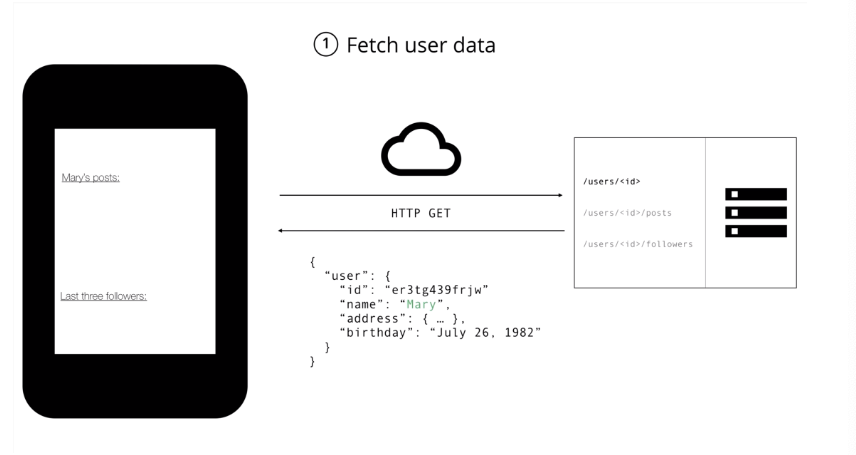
-
Overfetch: 필요 없는 데이터까지 제공함
- 유저의 이름만 필요한 상황에서 REST API를 사용한다면, 응답 데이터에는 유저의 주소, 생일 등과 같이 실제로는 클라이언트에게 필요없는 정보가 포함되어 있을 수도 있다.
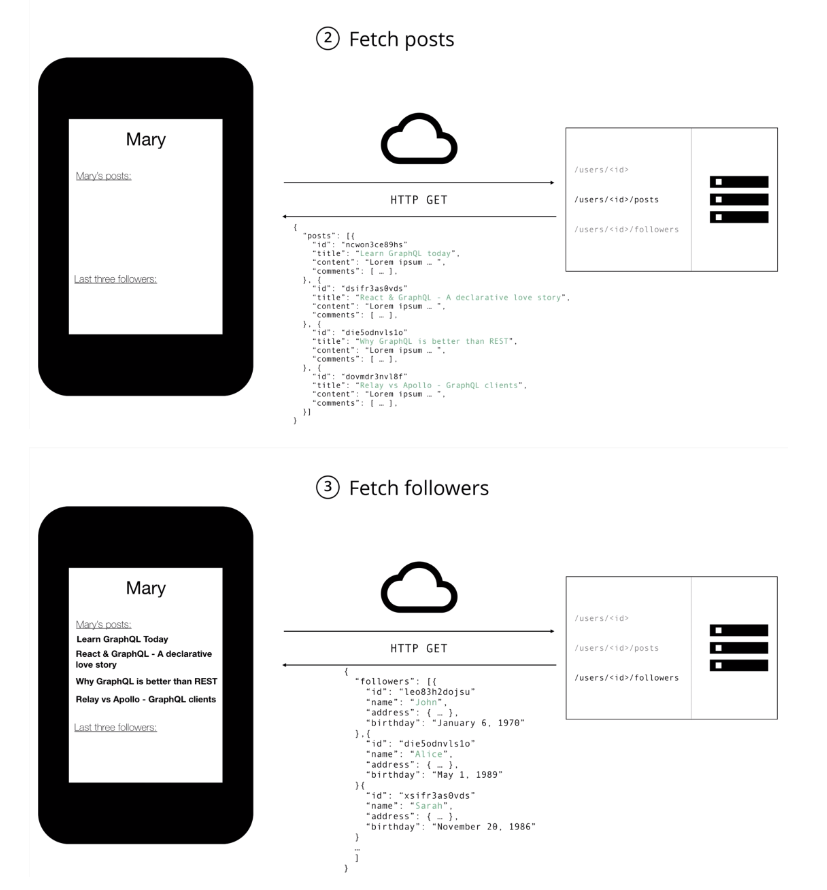
-
Underfetch: endpoint 가 필요한 정보를 충분히 제공하지 못함.
- Underfetch의 경우 클라이언트는 필요한 정보를 모두 확보하기 위하여 추가적인 요청을 보내야만 한다.
- 블로그 앱 예제 화면을 구현하기 위해선 유저 정보 뿐만 아니라 유저의 포스팅 목록 및 유저가 보유한 팔로워까지 필요함. 이때 필요한 정보를 모두 가져오려면 REST API에서는 각각의 자원에 따라 엔드포인트를 구분하기 때문에 3가지 엔드포인트에 요청을 보내야 한다.
-
클라이언트 구조 변경 시 엔드포인트 변경 또는 데이터 수정이 필요함
- REST API에서는 자원의 크기와 형태를 서버에서 결정하기 때문에 클라이언트가 직접 데이터의 형태를 결정할 수 없다. 이로 인해 만약 클라이언트에서 필요한 데이터의 내용이 변할 경우 다른 endpoint를 통해 변경된 데이터를 가져오거나 수정을 해야함.
GraphQL과 REST API의 다른점
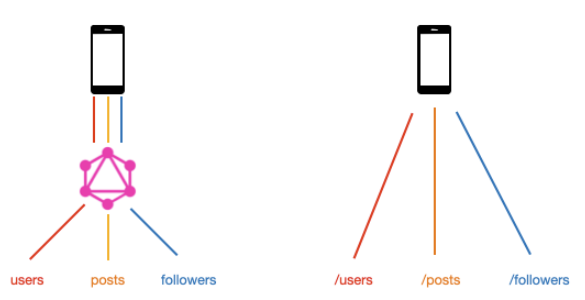
- REST API는 Resource에 대한 형태 정의와 데이터 요청 방법이 연결되어 있지만, GraphQL에서는 Resource에 대한 형태 정의와 데이터 요청이 완전히 분리되어 있다.
- REST API는 Resource의 크기와 형태를 서버에서 결정하지만, GraphQL에서는 Resource에 대한 정보만 정의하고, 필요한 크기와 형태는 클라이언트 단에서 요청 시 결정한다.
- REST API는 URI가 Resource를 나타내고 Method가 작업의 유형을 나타내지만, GraphQL에서는 GraphQL Schema가 Resource를 나타내고 Query, Mutation 타입이 작업의 유형을 나타낸다.
- REST API는 여러 Resource에 접근하고자 할 때 여러 번의 요청이 필요하지만, GraphQL에서는 한번의 요청에서 여러 Resource에 접근할 수 있다.
- REST API에서 각 요청은 해당 엔드포인트에 정의된 핸들링 함수를 호출하여 작업을 처리하지만, GraphQL에서는 요청 받은 각 필드에 대한 resolver를 호출하여 작업을 처리한다.
GraphQL의 장점
위와 같은 REST API의 한계때문에 정보를 사용하는 측에서 원하는 대로 정보를 가져올 수 있고, 보다 편하게 정보를 수정할 수 있도록 하는 표준화된 Query language 를 만들게 되었고 이것이 GraphQL이다. 동일한 예제를 통해 GraphQL의 장점을 알아보자.
GraphQL로 Blog 앱을 구현할 때
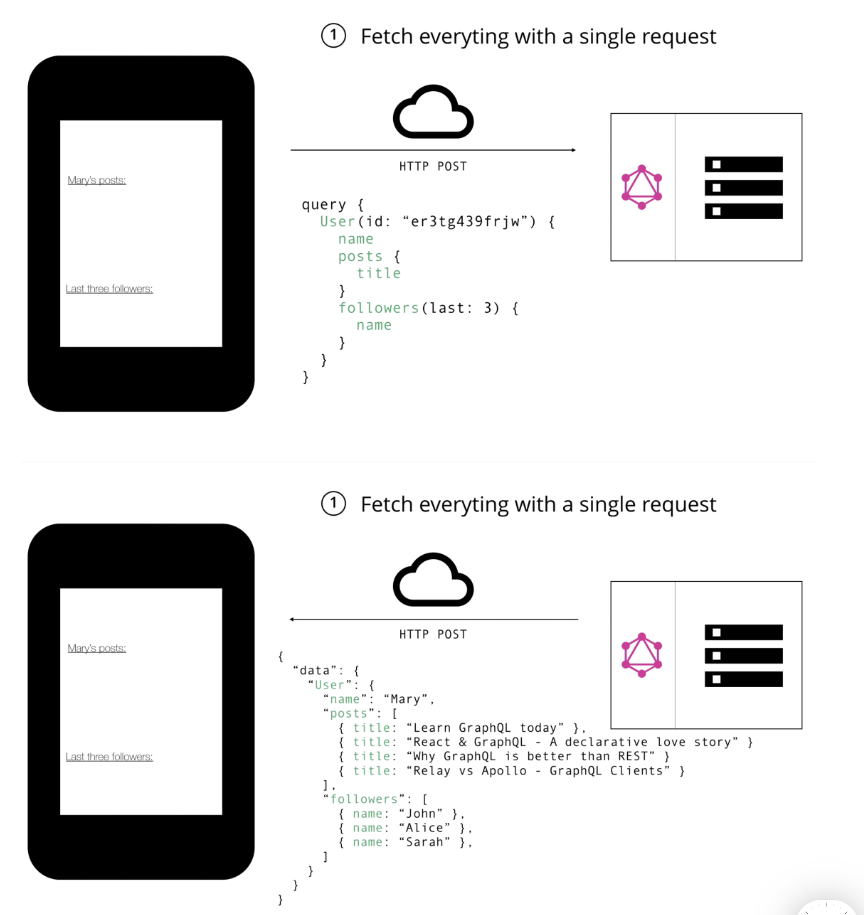
- 하나의 endpoint 요청
/graphql이라는 하나의 endpoint 로 요청을 받고 그 요청에 따라 query , mutation을 resolver 함수로 전달해서 요청에 응답한다. 모든 클라이언트 요청은 POST 메소드를 사용한다.
- No! under & overfetching
- 여러 개의 endpoint 요청을 할 필요없이 하나의 endpoint에서 쿼리를 이용해 원하는 데이터를 정확하게 API에 요청하고 응답으로 받을 수 있다.
- 강력한 playground
- graphql 서버를 실행하면 playground라는 GUI를 이용해 resolver 와 schema 를 한 눈에 보고 테스트 해 볼 수 있다. (POSTMAN 과 비슷합니다.)
- 클라이언트 구조 변경에도 지장이 없음
- 클라이언트 구조가 바뀌어도 필요한 데이터를 결정하고 받는 주체가 클라이언트이기 때문에 서버에 지장이 없다. 클라이언트에서는 무슨 데이터가 필요한 지에 대해서만 요구사항을 쿼리로 작성하면 된다.
GraphQL의 단점
- REST API에 친숙한 개발자의 경우 GraphQL를 학습하는 데 시간이 필요함.
- 캐싱이 REST보다 훨씬 복잡하다.
- HTTP에선 각 메소드에 따라 캐싱이 구현되어 있다. 하지만 GraphQL에선 POST 메소드만을 이용해 요청을 보내기 떄문에 각 메소드에 따른 캐싱을 지원받을 수 없다. 그래서 이를 보안하기 위해 Apollo 엔진의 캐싱과 영속 쿼리 등이 등장하게 됨.
- 고정된 요청과 응답만 필요할 경우에는 Query 로 인해 요청의 크기가 RESTful API 의 경우보다 더 커짐.
Chapter2. GraphQL 다루기
- GraphQL의 구조와 문법에 대해 학습합니다.
GraphQL 구조
GraphQL Keywords
서버로부터 데이터를 조회(Read)하는 경우, REST API에선 GET 요청이 있었다면 GraphQL에서는 Query를 이용해 원하는 데이터를 요청할 수 있다.
또한 Create, Delete와 같이 저장된 데이터를 수정하는 경우에는 Mutation을 이용해 이를 수행할 수 있다.
더 나아가 GraphQL에서는 구독(Subscription)이라는 개념을 제공하며 이를 이용해 실시간 업데이트를 구현할 수 있다.
- Subscription는 전통적인 Client(요청)-Server(응답) 모델을 따르는 Query 또는 Mutation과 달리, 발행/구독(pub/sub)모델을 따른다.
- 클라이언트가 어떤 이벤트를 구독하면, 클라이언트는 서버와
WebSocket을 기반으로 지속적인 연결을 형성하고 유지하게 된다. 그 후 특정 이벤트가 발생하면, 서버는 대응하는 데이터를 클라이언트에 푸시해준다.
정리하면,
- Query: 저장된 데이터 가져오기 (REST의 GET과 비슷)
- Mutation: 저장된 데이터 수정하기
- Create: 새로운 데이터 생성
- Update: 기존의 데이터 수정
- Delete: 기존의 데이터 삭제
- Subscription: 특정 이벤트가 발생 시 서버가 대응하는 데이터를 실시간으로 클라이언트에게 전송
쿼리(query, 데이터 조회)
필드(field)
전달인자(Arguments)
별명(Aliases)
오퍼레이션 네임(Operation name)
변수(Variables)
필드(field)
매우 간단한 query(데이터 조회, 이하 쿼리)와 실행 했을 때 얻은 결과부터 살펴보자
{
hero {
name
}
}[코드] hero의 name을 쿼리
{
"data": {
"hero": {
"name": "R2-D2"
}
}
}[코드] 쿼리를 실행했을 때의 결과
필드의 name은 String 타입을 반환한다. 위의 경우 hero의 name이 “R2-D2”임을 알 수 있다.
보이는 것처럼 쿼리와 결과가 정확하게 같은 모양을 하고 있음을 확인할 수 있는데, 이 부분은 GraphQL에 있어서 필수적이라고 볼 수 있다.
GraphQL은 서버에 요청했을 때 예상했던 대로 돌려받고, 서버는 GraphQL을 통해 클라이언트가 요구하는 필드를 정확히 알기 때문임
다른 예시
{
hero {
name
# 이런 식으로 GraphQL 내에서 주석도 작성할 수 있습니다.
friends {
name
}
}
}[코드] 히어로의 이름과 히어로의 친구 이름을 같이 쿼리
{
"data": {
"hero": {
"name": "R2-D2",
"friends": [
{
"name": "Luke Skywalker"
},
{
"name": "Han Solo"
},
{
"name": "Leia Organa"
}
]
}
}
}이런 식으로 원하는 필드를 중첩하여 쿼리하는 것도 가능함.
위의 예에서 freinds 필드는 배열을 반환한다. GraphQL 쿼리는 관련 객체 및 필드를 순회할 수 있기 때문에 고전적인 REST API에서 그러했듯 다양한 endpoint를 만들어 각기 요청을 보내는 대신 클라이언트가 하나의 요청을 보냄으로써 관련 데이터를 가져올 수 있다.
전달인자(Arguments)
필드에 인수를 전달하는 부분을 추가하게 되면 쿼리의 필드 및 중첩된 객체들에 전달하여 원하는 데이터만 받아올 수 있다.
{
human(id: "1000") {
name
height
}
}[코드] id가 1000인 human의 name과 height를 쿼리
{
"data": {
"human": {
"name": "Luke Skywalker",
"height": 1.72
}
}
}이런 식으로 id가 1000인 human의 이름과 키를 쿼리해 올 수 있다. REST와 같은 시스템에서는 단일 인수 집합(요청의 쿼리 매개변수 및 URL 세그먼트)만 전달할 수 있다.
예를 들어 REST API를 이용한다면 ?id=1000 이거나 /1000(/:id)일 때와 같은 목적으로 쿼리할 수 있다.
별명(Aliases)
필드 이름을 중복해서 사용할 수 없으므로, 필드 이름을 중복으로 사용해서 쿼리를 해야 할 때는 별명을 붙여서 쿼리를 한다.
{
hero(episode: EMPIRE) {
name
}
hero(episode: JEDI) {
name
}
}[코드] 이런 식으로 중복해 쿼리할 수 없다.
{
empireHero: hero(episode: EMPIRE) {
name
}
jediHero: hero(episode: JEDI) {
name
}
}[코드]앞에 알아볼 수 있는 별명을 붙여주면 쿼리할 수 있다.
{
"data": {
"empireHero": {
"name": "Luke Skywalker"
},
"jediHero": {
"name": "R2-D2"
}
}
}[코드] 쿼리 결과
위와 같이 다른 이름으로 별명을 지정하면 한 번의 요청으로 두 개의 결과를 모두 얻어낼 수 있다.
오퍼레이션 네임(Operation name)
여태껏 쿼리와 쿼리 네임을 모두 생략하는 축약형 구문을 사용했다만, 실제 앱에서는 코드를 모호하지 않게 작성하는 것이 중요하다.
오퍼레이션타입 오퍼레이션네임
query HeroNameAndFriends {
hero {
name
friends {
name
}
}
}[코드] 이런 식으로 query keyword와 query name을 작성
앞의 query는 오퍼레이션 타입. 오퍼레이션 타입에는 query 뿐만 아니라 mutation, subscription, describes 등이 있다. 쿼리를 약식으로 작성하지 않는 한 이런 오퍼레이션 타입은 반드시 필함.
오퍼레이션 네임을 작성할 때는 오퍼레이션 타입에 맞는 이름으로 작성하는 것이 가독성이 좋다.
변수(Variables)
여태껏 고정된 인수를 받아 쿼리했지만, 실제 앱을 사용할 때는 고정된 인수를 받는 것보다는 동적으로 인수를 받아 쿼리하는 경우가 대다수임. 변수는 그런 인수들을 동적으로 받고 싶을 때 사용한다.
query HeroNameAndFriends($episode: Episode) {
hero(episode: $episode) {
name
friends {
name
}
}
}[코드] 변수를 써서 작성된 쿼리
오퍼레이션 네임 옆에 변수를 $변수 이름: 타입 형태 로 정의한다. 위의 예시처럼 $ep: Episode 일 때, 뒤에 !가 붙는다면 ep는 반드시 Episode여야 한다는 뜻이다. !는 옵셔널한 사항.
뮤테이션(mutation, 데이터 수정)
GraphQL은 대개 데이터를 가져오는 데에 중점을 두고 있지만 서버측 데이터를 수정하기도 한다.
REST API에서 GET 요청을 사용하여 데이터를 수정하지 않고, POST 혹은 PUT 요청을 사용하는 것처럼 GraphQL도 유사하다. GraphQL은 mutation이라는 키워드를 사용하여 서버 측 데이터를 수정한다.
mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) {
createReview(episode: $ep, review: $review) {
stars
commentary
}
}스키마/타입(Schema/Type)
GraphQL 스키마의 가장 기본적인 구성 요소는 서비스에서 가져올 수 있는 객체의 종류, 그리고 포함하는 필드를 나타내는 객체 유형
type Character {
name: String!
appearsIn: [Episode!]!
}Character는 GraphQL 객체 타입이며, 즉 필드가 있는 타입임을 의미함. 스키마에 있는 대부분의 타입은 객체 타입이다.name과appearIn은Character타입의 필드. 즉name과appearIn은 GraphQL 쿼리의Character타입 어디서든 사용할 수 있는 필드.String은 내장된 스칼라 타입 중 하나. 이는 단일 스칼라 객체로 확인되는 유형이며 쿼리에서 하위 선택을 가질 수 없다. 스칼라 타입에는 ID, Int도 있다.!가 붙는다면 이 필드는 nullable하지 않고 반드시 값이 들어온다는 의미. 이것을 붙여 쿼리한다면 반드시 값을 받을 수 있을 것이란 예상을 할 수 있다.
-[ ]는 배열을 의미. 배열에도!가 붙을 수 있다. 여기서는!이 뒤에 붙어 있어 null 값을 허용하지 않으므로 항상 0개 이상의 요소를 포함한 배열을 기대할 수 있게 된다.
리졸버(Resolver)
요청에 대한 응답을 결정해주는 함수로써 GraphQL의 여러 가지 타입 중 Query, Mutation, Subscription과 같은 타입의 실제 일하는 방식 즉 로직을 작성한다.
즉 , 위와 같이 스키마를 정의하면 그 스키마 필드에 사용되는 함수의 실제 행동을 Resolver에서 정의한다. 또한 이러한 함수들이 모여 있기 때문에 보통 Resolvers라 부른다.
const db = require("./../db")
const resolvers = {
Query: { // **Query :** 저장된 데이터 가져오기 (REST 에 GET 과 비슷합니다.)
getUser: async (_, { email, pw }) => {
db.findOne({
where: { email, pw }
}) ... // 실제 디비에서 데이터를 가져오는 로직을 작성합니다.
...
}
},
Mutation: { // **Mutation :** 저장된 데이터 수정하기 ( Create , Update , Delete )
createUser: async (_, { email, pw, name }) => {
...
}
}
Subscription: { // **Subscription :** 실시간 업데이트
newUser: async () => {
...
}
}
};GraphQL에서는 데이터를 가져오는 구체적인 과정을 직접 구현해야 하는데 이와 같은 작업(e.g. 데이터베이스 쿼리, 원격 API 요청)을 Resolver가 담당하게 됨.
https://graphql.org/learn/
