Achieving Forgetting Prevention and Knowledge Transfer in Continual Learning
continual-learning
목록 보기
1/16
Achieving Forgetting Prevention and Knowledge Transfer in Continual Learning
NeurIPS 2021
분야 및 배경지식
- Continual Learning(연속학습)
- 일련의 연속적인 데이터를 통해 태스크, 도메인, 클래스 등을 학습하는 문제
- 빠르게 변하는 현실에서 어떻게 새로운 태스크들을 학습할 지 연구하는 실용적인 분야
- 새로운 태스크를 학습한 후 이전 태스크의 성능이 떨어지는 catastrophic forgetting(치명적인 까먹음)을 경감시키고 태스크들 사이의 지식전파(knowledge transfer)를 가능하게 하는 것이 목표
- Adapter-BERT
- BERT 모델에 adapter라는 모듈을 추가함으로써 파라미터 효율적인 transfer learning(전이학습)을 달성
- 모듈은 단순한 feedforward bottleneck 레이어로 이루어져 있으며, 태스크마다 각기 다른 어댑터를 가짐
- Capsnet (캡슐 네트워크)
- 스칼라 값으로 나오는 output feature detector를 벡터 형태의 output 캡슐로 바꿔 더 많은 정보를 담을 수 있게 함
- 비전(이미지) 태스크에서 많이 사용되는 max-pooling 대신 dynamic routing을 사용함으로써 개체의 정확한 위치정보를 유지
문제
- 지식전파(Knowledge Transfer)에 대한 연구 부족
- 기존 연구들은 Catastrophic Forgetting에 집중
- 기존의 Continual Learning 연구는 사전학습된 모델을 충분히 활용하지 못함
해결책
CTR (Capsules and Transfer Routing for continual learning)
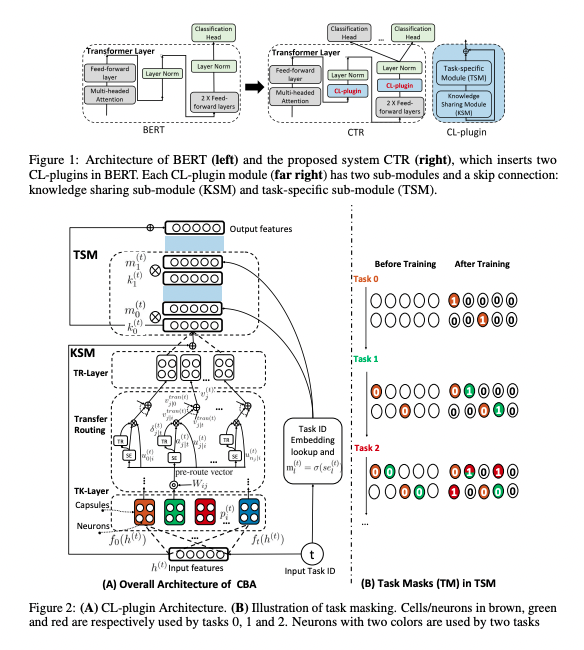
- CL-plugin
- 2개의 모듈(TSM, KSM)과 skip connection으로 이루어짐
- Adapter-BERT처럼 BERT의 각 transformer layer에 위치하며 CL-plugin과 분류 헤드만 학습됨
- 사전학습된 모델의 파라미터는 고정(frozen)
- KSM(Knowledge Sharing Module)
- 지식전파를 위한 모듈
- 캡슐 네트워크를 사용하여 더욱 많은 정보를 담고자 하였으며 새로운 transfer routing algorithm을 통해 유사한 태스크들 사이의 지식전파를 가능케 함
- 기존 Capsnet에서 사용된 dynamic routing은 몇 번을 반복할지 하이퍼파라미터로 지정해줘야 했으나, 여기서의 transfer routing algorithm은 그럴 필요가 없으며 더 나은 성능을 보장함
- TSM(Task-Specific Module)
- Catastrophic forgetting을 막기 위한 모듈
- task mask를 사용해서 이전 태스크에서 사용된 뉴런을 감지하고 이들의 gradient update를 제한
- 유사한 태스크의 경우 동일 뉴런의 파라미터를 공유할 수 있음
평가
- 데이터셋
- 문서 감정 분류(Document Sentiment Classification)
- 양상 감정 분류 (Aspect Sentiment Classification)
- 20 News data
- Baseline 비교
- B-CL: B-CL은 CTR과 유사한 아키텍처를 가졌으나 기존의 dynamic routing algorithm을 사용, CTR이 더 좋은 성능을 냄
- LAMOL: GPT-2 기반으로 pseudo-replay(이전 태스크에 해당하는 데이터를 만들어(pseudo) 연속학습 시 사용하는 방법)로 생성한 LAMOL보다 DSC에서 낮은 성능을 보였으나, 이는 BERT보다 GPT-2가 더욱 강력한 성능을 보이기 때문임. 또한 LAMOL은 forgetting이 심각
- MTL(multi-task learning): 모든 태스크들에 대해 한 번에 학습하는 방법, 일반적으로 CL의 upperbound로 여겨짐. CTR보다 약간 성능이 더 높음
의의
- 주어진 태스크에 대해 뛰어난 성능을 보임
- Adapter-BERT, 캡슐 네트워크 등을 사용하여 새로운 모델 아키텍처를 제시
- 사전학습된 트랜스포머 기반 모델을 잘 활용
- 일반적으로 CL에서 SOTA로 인식되는 replay(이전에 학습한 데이터셋 일부를 보관, 다음 학습에 사용) 방법을 사용하지 않고도 robust한 성능을 보임
한계
- 어떤 태스크가 어떤 태스크에 도움이 되는지, 지식 전파에 대한 구체적인 분석이 부족
- 캡슐 네트워크를 사용하며 태스크가 추가됨에 따라 캡슐 또한 추가되기 때문에, 효율성이 떨어짐
- 유사한 태스크들에 대한 분석(DSC, ASC)과 서로 다른 태스크들에 대한 분석(20 news data)이 별개로 이루어짐
- 유사한 태스크들과 유사하지 않은 태스크들을 함께 학습했을 때 지식 전파와 Catastrophic Forgetting 경감이 모두 이루어지는지에 대한 관측 없음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab