Adapting BERT for Continual Learning of a Sequence of Aspect Sentiment Classification Tasks
continual-learning
목록 보기
2/16
Adapting BERT for Continual Learning of a Sequence of Aspect Sentiment Classification Tasks
ACL 2021
분야 및 배경지식
Continual Learning, Adapter, Aspect Sentiment Classification
- Continual Learning (연속학습)
- 실용적인 쓰임 때문에 연구가 필요한 분야
- 예를 들어 학습에 사용된 개인정보 데이터가 학습 후 삭제되어야 하는 등의 상황에서(=즉 새로운 태스크 학습 시 이전 데이터 사용 불가) 연속적으로 새로운 데이터를 학습하고 모델을 업데이트해야 할 때 이전의 데이터에 대한 예측도 잘 하면서도 새로운 데이터에 대한 예측도 잘 하는 방식을 연구하는 것이 연속학습의 주요한 목표
- Lifelong Learning (평생학습)
- 현재는 CL과 동의어로 사용됨
- LL의 주요 목표는 새로운 태스크의 학습을 개선
- Adapter-BERT
- BERT의 각 트랜스포머 레이어에 2-layer fully connected network인 adapter를 추가
- end-task를 학습함에 있어서 전체 모델을 학습하는 것이 아니라 adapter와 normalization layer만 학습함으로써 파라미터 효율화를 꾀함
- Aspect Sentiment Classification
- 감정 분류의 한 분야
- 예를 들어 '이 제품은 사진 퀄리티는 좋으나 배터리는 금방 닳는다'라는 리뷰가 있다면, '사진'에 대해서는 '긍정', '배터리'에 대해서는 '부정'으로 판단할 수 있음
문제점
- 이전 태스크의 지식을 전이해 새로운 태스크의 학습에 도움을 주는 knowledge transfer 연구 필요성
- 동시에 이전 태스크의 성능을 유지하는 mitigating catastrophic forgetting 연구 필요성
해결책
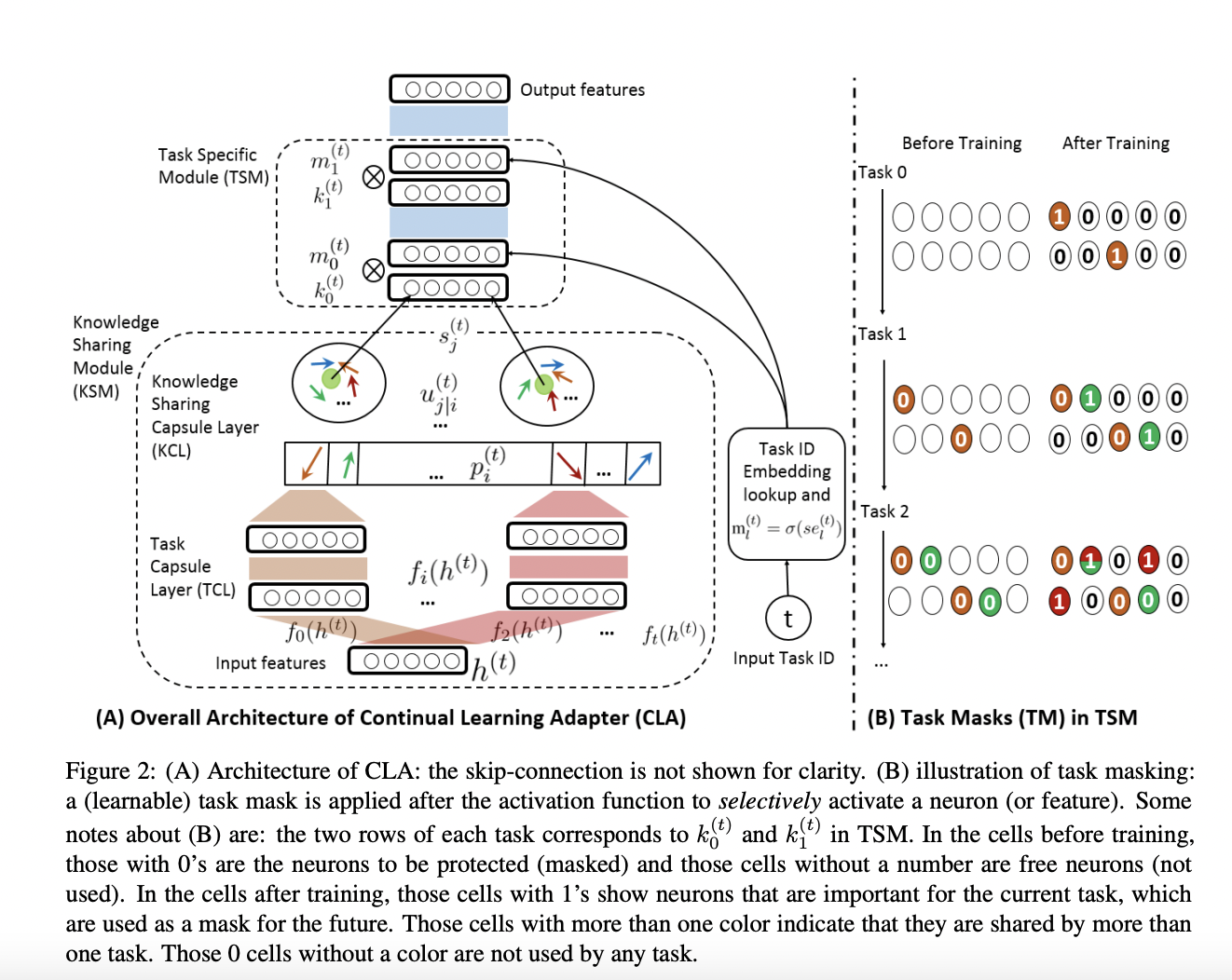
B-CL (Bert-based Continual Learning) for ASC
- CLA (Continual Learning Adapter)
- Adapter-BERT의 구조에서 영감을 받아 만든 블럭
- 캡슐 네트워크와 다이나믹 라우팅을 사용해 이전 태스크와 유사한 새로운 태스크를 판별(knowledge transfer)
- 태스크 마스크를 사용해 태스크 특화 지식을 보존(catastrophic forgetting)
- Capsule Network
- 스칼라로 구성된 feature detector를 vector capsule로 치환해 더 많은 정보를 보존
- 두 개의 레이어로 구성
- dynamic routing algorithm을 활용해 더 낮은 단계의 캡슐 레이어가 유사한 성격을 가진 더 높은 단계의 캡슐 레이어에 연결되도록 구성 (Hinton의 논문에서 영감을 얻음)
- Adapter-based block
- adapter와 유사한 위치에 CLA를 삽입
- 과 으로 구성
- knowledge sharing module (지식 공유 모듈; KSM)
- 두 개의 캡슐 레이어와 다이나믹 라우팅을 활용해 유사한 태스크(low-level capsule layers)들을 유사한 지식을 가진 캡슐(high-level capsule layers)로 연결
- 높은 coefficient를 가진 유사한 태스크들의 경우 더 큰 gradient로 backpropagation, 낮은 coefficient를 가진 다른 태스크들의 경우 low gradient로 학습
- coefficient는 i번째 태스크가 j번째 지식공유캡슐에 얼마나 많은 정보를 주는가를 나타냄, clustering의 역할 수행
- task specific module(태스크 특화 모듈; TSM)
- 태스크 마스크를 활용해 새로운 태스크를 학습할 때 사용된 뉴런의 gradient update, 학습을 막음
- 겹치는 마스크가 있는 경우 유사한 태스크로 판단 가능
평가
- 데이터셋
- HL5Domains, Liu3Domains, Ding9Domains, SemEval14에서 총 19개 사용
- 평가기준
- 정확성, Macro-F1
한계
- 캡슐 네트워크의 특성상 연산이 많아질 수밖에 없음 (비용 증가)
의의
- forward, backward knowledge transfer를 통해 새로운 태스크와 이전 태스크의 성능을 모두 높임
- forward transfer, 즉 이전 태스크들의 지식으로 새로운 태스크의 성능을 높이는 데에 높은 효과를 보임
- backward transfer, 즉 새로 학습하는 태스크들의 지식으로 이전에 학습한 태스크의 성능을 높이는 데에는 약간의 효과를 보임
- catastrophic forgetting의 완화에도 성능을 보임
- capsule network, dynamic routing의 개념을 연속학습에 새로이 접목시킴

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab