Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity (link, NAACL 2024)
배경지식
- Open-domain QA
- 쿼리와 관련된 문서를 기반으로 하여 쿼리에 정확하게 응답하는 태스크
- Multi-hop QA
- 전통적인 Open-domain QA를 확장한 태스크
- 더 복잡한 쿼리에 답하기 위해 여러 개의 문서를 기반으로 답변하는 태스크
- 여러 개의 문서에서 정보를 가져오기 위해, 종종 반복적으로(iteratively) 수행
- Adaptive Retrieval
- 쿼리의 복잡도를 기반으로 문서를 검색할지 여부를 결정하는 전략
- 쿼리의 복잡도는 개체(entity)의 빈도를 활용해 평가하거나, BERT 기반의 LM을 활용해 검색, 읽기, 리랭킹의 과정을 여러 번 반복하는 연구들이 존재했음
문제점
- 기존의 RAG 방법론들은 쿼리들의 각기 다른 복잡도를 고려하지 않음
- 복잡한 다단계(multi-step)를 요구하는 쿼리를 해결하지 못하거나
- 단순한 쿼리에 불필요한 연산 오버헤드를 추가하거나
- 하나의 접근방식이 모든 경우에 적용될 수 없음
해결책
Adaptive RAG
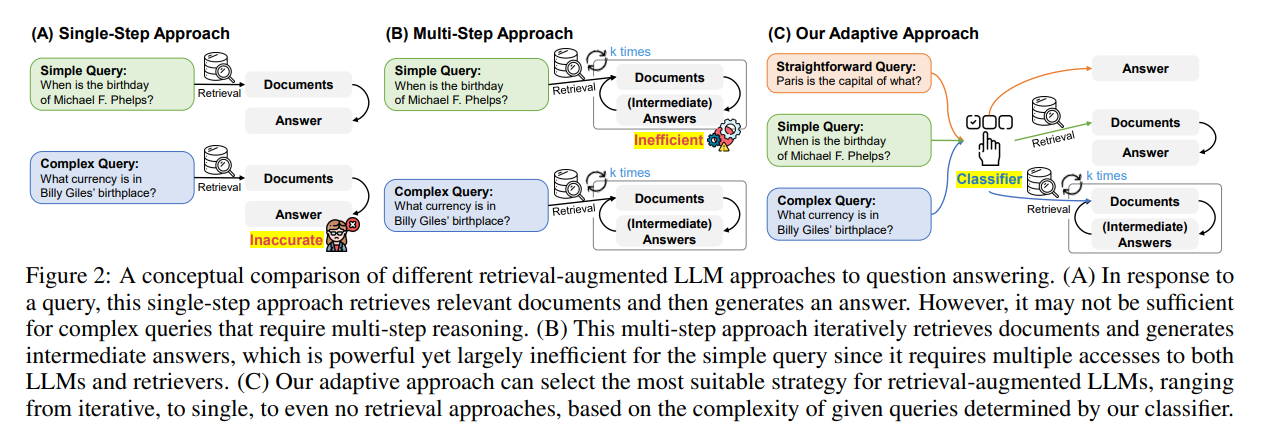
- 쿼리의 복잡도를 기반으로 적절한 RAG 전략을 역동적으로 선택하는 방법론
- 검색을 하지 않거나, 한 번 검색하거나, 여러 번 검색하는 세 가지 단계로 분류
- 쿼리의 복잡도를 평가하기 위해, 작은 모델을 분류기(classifier)로 훈련
Classifier 훈련 데이터셋 생성
- 사람의 개입 없이 자동으로 레이블링된 학습 데이터셋을 활용
- 클래스 (레이블) 총 3개로 구성
- 언어모델 자체로 답변 가능 (검색 필요 없음)
- 한 번의 검색으로 응답 가능 (single-step)
- 여러 번의 검색이 필요한 복잡한 쿼리(multi-step)
- 데이터셋 생성 방법
- 모델이 예측한 응답
- 세 개의 검색 전략을 기반으로, 모델이 적절히 응답할 수 있는지 여부에 따라 레이블링
- 만약 single-step, multi-step에서 모두 답변 가능한 경우, 더 단순한 방법론인 single-step으로 정답을 레이블링
- 기존 데이터셋의 타겟 시나리오 (single-step인지 multi-step인지)
- 모델이 세 개의 전략에서 모두 적절한 응답을 하지 못할 경우
- 기존 데이터셋이 single-step을 위한 건지, multi-step을 위한 건지에 따라 결정
- 모델이 예측한 응답
평가
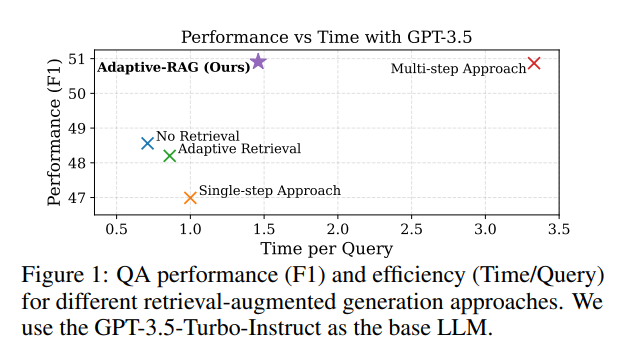
- 모델
- 검색 시 BM25 활용
- 응답 생성 시 FLAN-T5와 GPT-3.5 활용
- 쿼리 복잡도 분류의 경우 T5-large 활용
- 데이터셋
- Single-hop
- SQuAD v1.1
- Natural Questions
- Trivia QA
- Multi-hop
- MuSiQue
- HotpotQA
- 2WikiMultiHopQA
- Single-hop
- 평가지표
- 효과성 (effectiveness)
- F1 (정답과 모델 답변 사이 겹치는 단어의 수)
- EM (정답과 모델 답변이 동일한지)
- Acc (모델 답변에 정답이 포함되어 있는지)
- 효율성 (efficiency)
- 검색 및 생성(retrieval-and-generate) 단계의 수
- 각 쿼리에 응답하는 평균 시간
- 효과성 (effectiveness)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab