MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries (link)
배경지식
- RAG (Retrieval Augmented Generation)
- 언어모델이 응답을 생성할 때 관련된 지식을 검색해 input으로 제공하는 방식
- 환각 현상(=언어모델이 그럴듯한 거짓말을 하는 현상)을 완화하고 응답을 품질을 높임
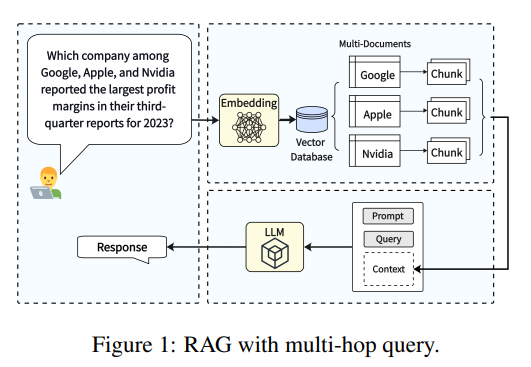
- Multi-hop RAG
- 여러 개의 문서를 검색하고, 이를 기반으로 추론을 통해 사용자의 질문을 답하는 RAG
문제점
- 기존의 RAG 벤치마크들은 multi-hop 질문에 대한 고려가 없었음
- 대부분 하나의 증거 문서만 잘 검색하면 답할 수 있는 단순한 케이스들
해결책
Multi-hop RAG 데이터셋
- multi-hop 질문, 정답, 관련된 뒷받침 문서들까지 포함된 벤치마크 데이터셋
쿼리 종류
- 추론 쿼리 (Inference Query)
- 검색 문서들에 기반해 추론을 통해 답변을 생성
- 개체(entity)로 답변
- e.g. 애플 공급망 위기에 대해 논한 리포트는 2019 연간 리포트인가요 혹은 2020 연간 리포트인가요?
- 비교 쿼리 (Comparison Query)
- 검색 문서들에 포함된 증거들을 비교 (공통점, 차이점)
- 일반적으로 답변은 예/아니오
- e.g. 2023년에 더 높은 수익을 낸 회사는 넷플릭스인가요 구글인가요?
- 시간 쿼리 (Temporal Query)
- 검색 문서들에서 시간에 관련된 정보를 분석
- 답변은 예/아니오 혹은 이전/이후
- e.g. 애플이 AirTag 트래킹을 소개한 건 아이패드 프로 5세대 출시 전인가요 후인가요?
- 빈 값 쿼리 (Null Query)
- 검색된 문서들로부터 답변을 생성할 수 없는 경우
- 환각 현상 감지를 위함
- 불충분한 정보 혹은 이와 유사하게 답변해야 함
- e.g. (ABCD가 없는 회사일 경우) ABCD 회사가 2022년, 2023년 올린 매출은 얼마인가요?
데이터셋 구축
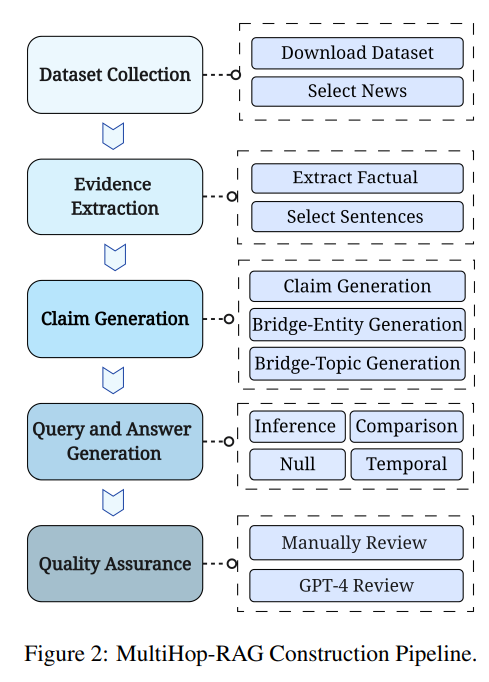
- 1. 데이터셋 수집
- mediastack API를 활용
- 연예, 사업, 스포츠, 기술, 건강, 과학 등의 뉴스 카테고리
- 언어 모델이 학습하지 않은 2023년 9월 26일 - 2023년 12월 26일 데이터 활용
- 1024 토큰 이상의 길이만을 활용
- 2. 증거 추출
- 언어 모델을 활용해 사실 혹은 의견 문장들을 추출 (=증거)
- 다른 뉴스 기사들과 겹치는 키워드가 있는 기사들만 활용
- Claim, Bridge-Entity, Bridge-Topic 생성
- GPT-4를 활용해, 원래의 증거와 그 문맥을 가지고 이를 paraphrase (=claim)
- 이러한 과정은 증거에 존재할 수 있는 대명사 등을 제거하기 위함
- UniEval을 통해 사실 확인 진행
- GPT-4를 활용해, 증거들 사이에 공유되고 있는 개체 혹은 토픽을 식별 (=bridge-entity, bridge-topic)
- 4. 쿼리 및 답변 생성
- bridge-entity와 bridge-topic을 활용해 multi-hop 질문을 생성
- 쿼리 생성 시 뉴스 기사 원본 또한 포함
- 5. 품질 검수
- 일부 샘플에 대해 사람의 정성 평가
- GPT-4를 활용한 품질 평가

평가
평가지표
- 검색 성능지표
- Mean Average Precision at K (MAP@K)
- Mean Reciprocal Rank at K (MRR@K)
- Hit Rate at K (Hit@K)
- 생성 성능지표
- 모델 응답과 정답 비교
모델
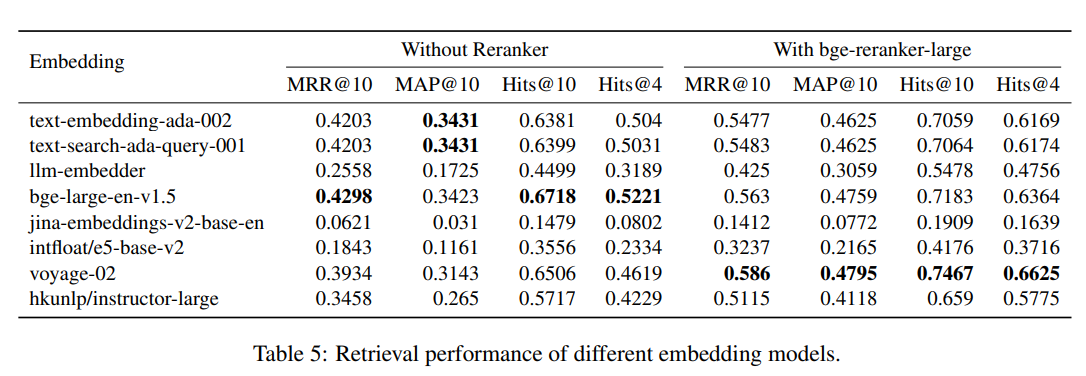
- 검색 성능 비교 (임베딩 모델)
- ada-embedding, voyage-02, llm-embedder, jina-embeddigs-v2-base-en, instructor-large, e5-base-v2
- 리랭커 모델도 활용 (bge-reranker-large)
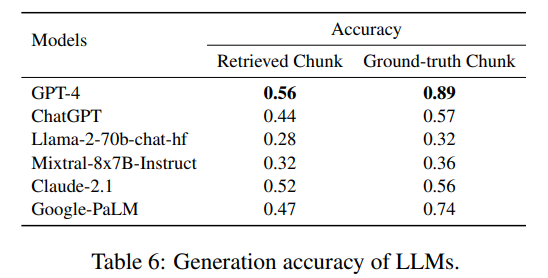
- 생성 성능 비교 (언어모델)
- GPT-4, GPT-3.5, PaLM, Claude-2, Llama2-70B, Mixtral-8x7B
한계
- 데이터셋의 정답 답변이 단순하게 구성 (예, 아니오 등)
- 문제점에서는 multi-hop 데이터셋의 부재를 꼽았으나, 데이터셋을 단순한 RAG 시나리오에서 검토
- 기존의 데이터보다 더 어려운 multi-hop 데이터셋을 구축하였으나 평가에서 그 장점이 잘 드러나지 않음
- 논문에서 잠깐 언급한 query decomposition등의 Advanced RAG 방법론들을 비교하거나
- 동일한 임베딩 모델, 언어 모델들을 비교실험 했을 때 single-hop 데이터셋과 multi-hop 데이터셋이 얼마나 다른 성능 점수를 보이는지 알려줬다면 좋았을 것으로 보임

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab