Automatic Prompt Optimization with “Gradient Descent” and Beam Search, arXiv 2023
분야 및 배경지식
- 프롬프트 (prompt)
- 자연어 프롬프트
- 사람이 이해할 수 있는 언어로 만들어진 프롬프트
- natural language prompt, discrete prompt, hard prompt 등으로 불림
- 텐서 프롬프트
- 학습 가능한 텐서로 이루어진 프롬프트
- continuous prompt, soft prompt 등으로 불림
- 자연어 프롬프트
문제점
- 자연어로 된 좋은 프롬프트를 작성하기 위해서는 시행착오, 사람의 노력 및 전문성 등이 필요
- 어떤 자연어 프롬프트를 사용하느냐에 따라 태스크의 성능이 크게 달라짐
해결책
Automatic Prompt Optimization (APO)

- 인공신경망 모델을 업데이트하는 gradient descent 방식에서 영감을 얻음
- 특정 태스크를 위한 방식이 아닌 일반적인 방식이며, 모델의 파라미터가 필요하지 않음 (nonparameteric)
- 언어모델의 API와 학습 데이터에 접근이 가능함을 전제
- 반복적으로 프롬프트를 정제함으로써 최적의 프롬프트에 대한 근사값을 생성하고자 함
gradient descent with prompts
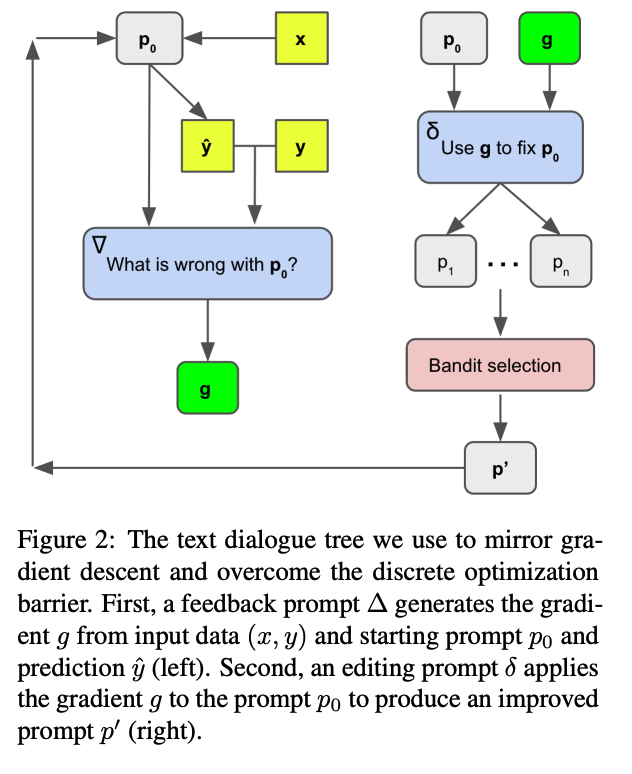
- 순서
- 데이터 일부에 대해 프롬프트를 평가
- 현재 프롬프트를 개선할 수 있는 정보를 담은 local loss signal 생성
- 의미적으로 gradient의 반대 방향으로 프롬프트를 수정
- gradient
- 현재 프롬프트의 결점에 대한 설명들을 gradient라고 지칭
- 해당 gradient의 반대 방향으로 현재 프롬프트를 수정
- 일종의 local loss signal 역할을 수행
- feedback prompt (∆)
- 인풋 데이터와 초기 프롬프트를 이용해 gradient를 생성하는 프롬프트
- editing prompt (δ)
- gradient를 초기 프롬프트에 적용해 개선된 프롬프트를 생성할 수 있게끔 하는 프롬프트
beam search over prompts
- expansion (확장)
- 현재 프롬프트로부터 여러 개의 새로운 후보 프롬프트를 생성하는 단계
- 앞서 설명한 gradient descent 방식(Socratic dialogues 방식과 유사) 진행 후 paraphrase과정을 거쳐 추가적인 후보군 생성
- selection (선택)
- 다음 반복 시에 어떠한 프롬프트만을 남겨둘 것인지 선택하는 단계
- bandit optimization의 best arm identification 문제와 유사
- UCB, UDB-E, Successive Rejects, Successive Halving 등 다양한 방식 실험
- UCB 계열이 좋은 성능을 보임
평가
- 4개의 NLP 분류 태스크
- Jailbreak: 사용자의 인풋이 모델로 하여금 자신의 메타 프롬프트를 드러내게 하거나 해로운 컨텐츠를 생성하도록 하는지 여부를 판단 (452 언어)
- Ethos: 혐오 발언 감지 (영어)
- Liar: 가짜 뉴스 감지 (영어)
- Sarcasm: 풍자/비꼼 감지 (아랍어)
- APO가 베이스라인 대비 좋은 성능을 보임
한계
- 학습 데이터를 알아야 한다는 단점 존재
의의
- 모델의 파라미터가 없어도 최적화가 가능한 nonparameteric 방법
- gradient descent라는 개념을 자연어 프롬프트 최적화에 적용해보고자 한 새로운 시도

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab