Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions
prompt-engineering
목록 보기
17/18
Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions
arXiv 2023
분야 및 배경지식
- LLM (Large Language Model)
- 거대한 코퍼스로 학습한 언어모델
- GPT-4, InstructGPT 등이 대표적이며 최근 많은 기업에서 거대한 생성형 언어모델을 만들고 있음
- 일반적으로 사람의 지시, 설명(instruction)을 잘 따를 수 있도록 학습된 경우가 많음
문제점
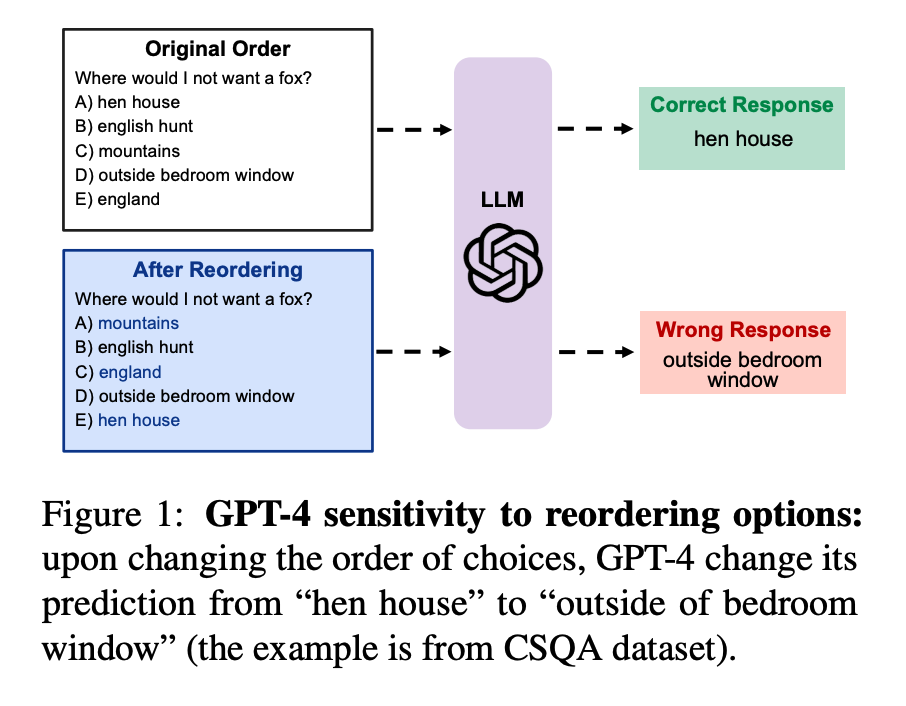
- 거대한 언어모델은 프롬프트의 단어, 예시(demonstration)의 순서 등에 민감하나, 이에 대한 깊이있는 탐구가 많이 이루어지지 않았음
해결책 (분석)
순서에 대한 민감성 (sensitivity gap)
- GPT-4가 InstructGPT 대비 순서에 대한 민감성이 낮음
- 하지만 높은 정확도를 가진 태스크에 대해서도 순서에 따른 성능 차이가 13.1% 존재
- 언어모델이 잘 예측하지 못하는 태스크라고 해서 무조건 순서에 따른 민감성이 높은 건 아님
- 다만 sensitivity gap은 오류율(error rate)과 긴밀한 상관관계를 가지는 경향성 존재
- 여러 예시(demonstration)를 추가한 few-shot에서는 민감성이 조금 감소하나, 민감성을 완전히 해소해주지는 못함
- 예시의 개수를 더 늘린다고 해서 민감성이 떨어지는 것은 아님
위치에 대한 민감성 (positional bias)
- 편향을 높이기 위해서는 정답 확률이 높은 2개의 선택지를 처음과 마지막에 위치
- adversarial attack 적용 및 모델의 성능 향상에 대한 통찰을 제공
- 편향을 낮추기 위해서는 정답 확률이 높은 2개의 선택지를 인접하게 위치
Calibration
- 다수결 (majority vote)
- 선택지의 순서를 랜덤하게 바꿔 모델에게 질의하고 그 중 다수결로 정답을 선택
- 민감성은 제거할 수 있으나 연산 비효율적
- MEC (Multiple Evidence Calibration)
- 모델이 예측을 생성하기 전에 설명을 생성하도록 프롬프팅
- 모델로 하여금 추론 과정을 설명하라고 하는 것은 불확실성을 가중시키는 효과를 주어 성능이 일관되지 않음
평가
- 태스크
- multiple-choice question (다지선다)
- CSQA (5개 선택지)
- Abstract Algebra, High School Chemistry, Professional Law (4개 선택지)
- Logical deduction (3개 선택지)
- 데이터를 선택함에 있어 도메인, 선택지의 개수, 언어모델의 성능 정도 등을 종합적으로 고려하여 다양성을 추구
- multiple-choice question (다지선다)
- 모델
- GPT-4
- InstructGPT
한계
- 한정된 태스크와 모델에 대한 연구
- 마땅한 해결책을 제시하지 못함 (only calibration)
의의
- LLM의 시대에서 모델의 성능과 강건성을 높이기 위한 중요한 주제

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab