BBTv2: Towards a Gradient-Free Future with Large Language Models
EMNLP 2022
분야 및 배경지식
- BBT (논문리뷰)
문제
- PET(parameter-efficient tuning)
- 기존 모델보다 더 적은 수의 파라미터를 사용하나, 여전히 backprop이 필요
- gradient를 사용할 수 없는 환경에서 적용 불가
- prompt, demonstration
- 어떠한 프롬프트/데모를 선택하느냐에 따라 성능 차이가 심함
- 이전에 제안된 gradient-free 방식(BBT)의 한계 존재
- 프롬프트의 좋은 초기값을 찾기 위해 gradient descent 필요 (완전한 gradient-free가 아님)
- convergence가 느림
- 태스크, 언어모델에 대해 다양하게 적용 가능하지 않음 (RoBERTa 위주 연구)
해결책
BBT v2 (Deep Black-box Tuning)
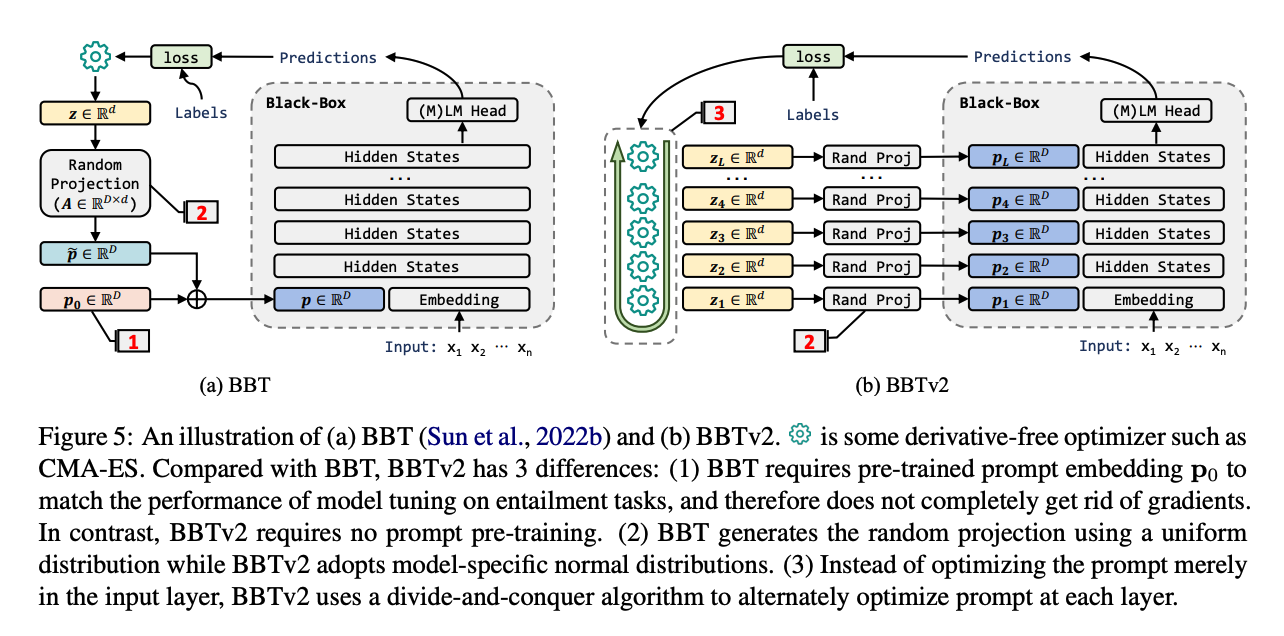
- 사전학습 모델의 모든 레이어의 hidden states에 프롬프트를 붙임
- 고차원의 DFO(derivitave-free optimization) 문제를 풀어야 한다는 단점 존재
- residual connection 덕분에 덧셈 형식(additive form)으로 바꾸어 여러 개의 저차원 하위문제로 치환 가능
- divide-and-conquer 알고리즘 사용
- 각 레이어의 프롬프트를 순서대로(아래부터) 최적화
- random projection 생성 시 사전학습 모델과 관련된 표준편차를 활용한 정규분포 사용 (versatility 높임)
평가
- 데이터셋
- 감성 분석: SST-2, Yelp
- 주제 분류: AG's News, DBPedia
- 자연어 추론: SNLI, RTE
- 의역 (paraphrase): MRPC
- 모델
- RoBERTa-large
- BERT-large
- GPT2-large
- BART-large
- T5-large
- BBT v2가 평균적으로 가장 좋은 성능을 보임 (gradient-free, gradient-based)
의의
- 사전학습 모델의 낮은 intrinsic dimensionality를 활용함으로써 더욱 큰 모델에서 더 뛰어난 성능을 보임
- 이전 BBT보다 convergence 속도, 태스크 및 모델 다양성 등의 측면에서 더욱 좋은 성능
한계
- 전체 모델을 파인튜닝하는 것만큼 좋은 성능을 내는 첫 번째 black-box method라고 주장하나, 이는 black-box를 naive하게 정의할 때만 타당한 주장
- black-box를 naive하게 gradient-free하다고 정의한다면 타당
- 하지만 만약 모델에 대한 아무런 정보도 알 수 없는 일반적인 black-box setting을 가정한다면, 모델에 맞는 정규분포를 사용하고 레이어마다 프롬프트를 붙인다는 점에서 모델에 대한 정보를 확보해야 함
- 다양한 모델에 대해서 적용 가능하다고 주장하나, 다른 baseline과의 비교는 RoBERTa에 대해서만 이루어짐
- GPT, BART, T5 등과 같은 모델은 오로지 BBT, BBT v2만 비교
- 레이어마다 prompt를 붙이고 이를 최적화해야 하기 때문에, 최적화를 위한 하이퍼파라미터가 다수 필요함

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab