BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
language-model
목록 보기
3/20
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, arXiv 2018
분야 및 배경지식
- 사전학습 언어 표현(=representation)을 downstream task에 적용하는 방식
- feature-based
- 태스크에 특화된 아키텍처를 사용
- fine-tuning
- 최소한의 태스크-특화 파라미터를 도입
- feature-based
문제점
- 일반적인 언어모델은 일방향(unidirectional) 문맥만을 참고한다는 한계가 존재
- 일방향이란, 문장의 새로운 토큰을 예측할 때 왼쪽의 문맥만 참고함을 의미
- 문장 단위의 태스크 혹은 토큰 단위의 태스크에서 sub-optimal
해결책
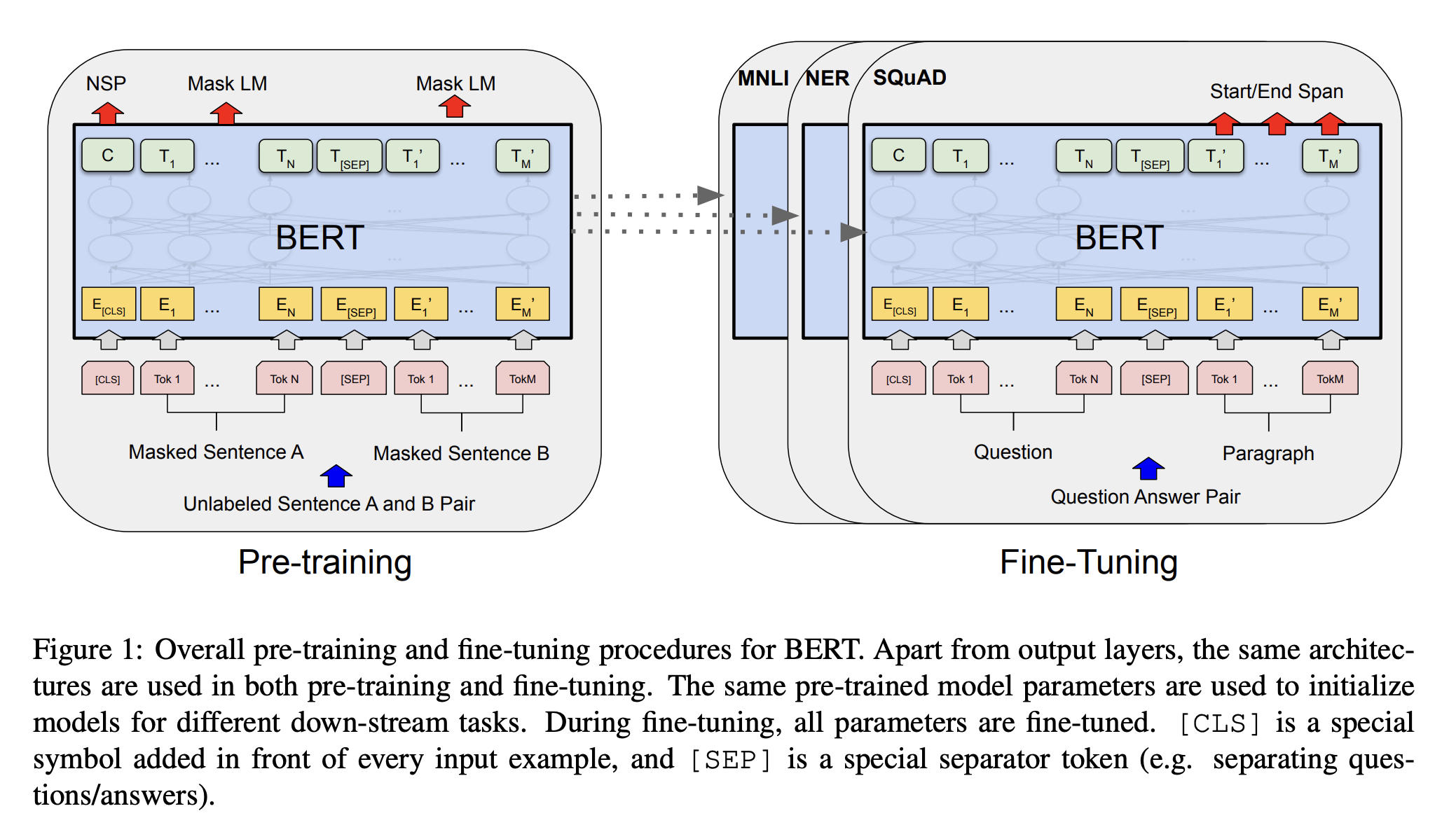
- Transformer의 Encoder 구조 활용
Masked Language Model
- Masked Language Model(=MLM)이라는 새로운 사전학습 목적함수를 도입
- input에서 토큰의 일부를 랜덤으로 마스킹(=가림)하고, 이를 예측하는 방식으로 학습
- Cloze task(빈칸 채우기)와 유사
- 양방향(bidirectional) 문맥을 모두 참고할 수 있음
- 파인튜닝 시에는 [MASK]를 예측하지 않기 때문에, 사전학습과 파인튜닝 사이의 차이(=mismatch)를 메우기 위해
- 랜덤으로 선택된 토큰의 80%는 [MASK]로 바꾸어 예측하게 하고
- 10%는 랜덤한 토큰으로 치환하고
- 10%는 바꾸지 않고 원래대로 사용함
- input에서 토큰의 일부를 랜덤으로 마스킹(=가림)하고, 이를 예측하는 방식으로 학습
- Next Sentence Prediction
- 문장쌍의 표현(=representation)을 학습하기 위해 추가적인 목적함수 사용
- 50%는 연속적인 문장, 50%는 랜덤으로 이어붙인 문장 (binary classification)
Pre-train and Fine-tune
- GPT와 유사하게, 레이블(=정답)이 없는 데이터로 사전학습 진행
- 사전학습 파라미터로 모델을 먼저 초기화한 후, downstream task에 맞게 레이블이 있는 데이터로 fine-tune
평가
- 사전학습
- 데이터로 BooksCorpus, English Wikipedia 사용
- 파인튜닝
- GLUE (General Language Understanding Ealuation) 벤치마크
- SQuAD v1.1, SQuAD v2.0, SWAG
- BERT-large가 baseline 대비 좋은 성능을 달성
- SQuAD v1.1의 경우 앙상블 모델보다 단일 BERT 모델이 F1 score에서 더욱 뛰어난 성능
의의
- 왼쪽과 오른쪽의 문맥을 양방향으로 모두 참고해 풍부한 문맥을 활용
- 다양한 태스크를 하나의 통합된 아키텍처를 사용해 수행할 수 있음
- 하나의 추가적인 output layer만 있으면 fine-tuning 가능
한계
- 자연어 이해에는 좋은 성능을 보이지만 자연어 생성 태스크의 경우 한계 존재

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab