Improving Language Understanding by Generative Pre-Training
분야 및 배경지식
- supervised learning (지도학습)
- 정답, 즉 레이블이 있는 데이터로 학습하는 방식
- unsupervised learning (비지도학습)
- 레이블이 없는 데이터로 학습하는 방식
- 정답 데이터가 없더라도 좋은 표현(=representation)을 배워 성능 향상을 이끌 수 있음
문제점
- 레이블(=정답)이 없는 데이터는 많지만 특정 태스크를 학습하기 위해 레이블이 존재하는 데이터는 드물음
- 레이블을 만드는 과정은 시간과 비용이 많이 들음
- 레이블이 없는 데이터를 활용해 좋은 표현(=representation)을 학습하고 이를 전이(=transfer)하고자 할 때의 어려움
- 어떠한 종류의 최적화 목적함수(optimization objective)를 사용해야 하는지 불확실
- 어떠한 방식으로 전이해야 가장 효과적인지 합의된 바가 없음
해결책
unsupervised pre-training + supervised fine-tuning = semi-supervised approach
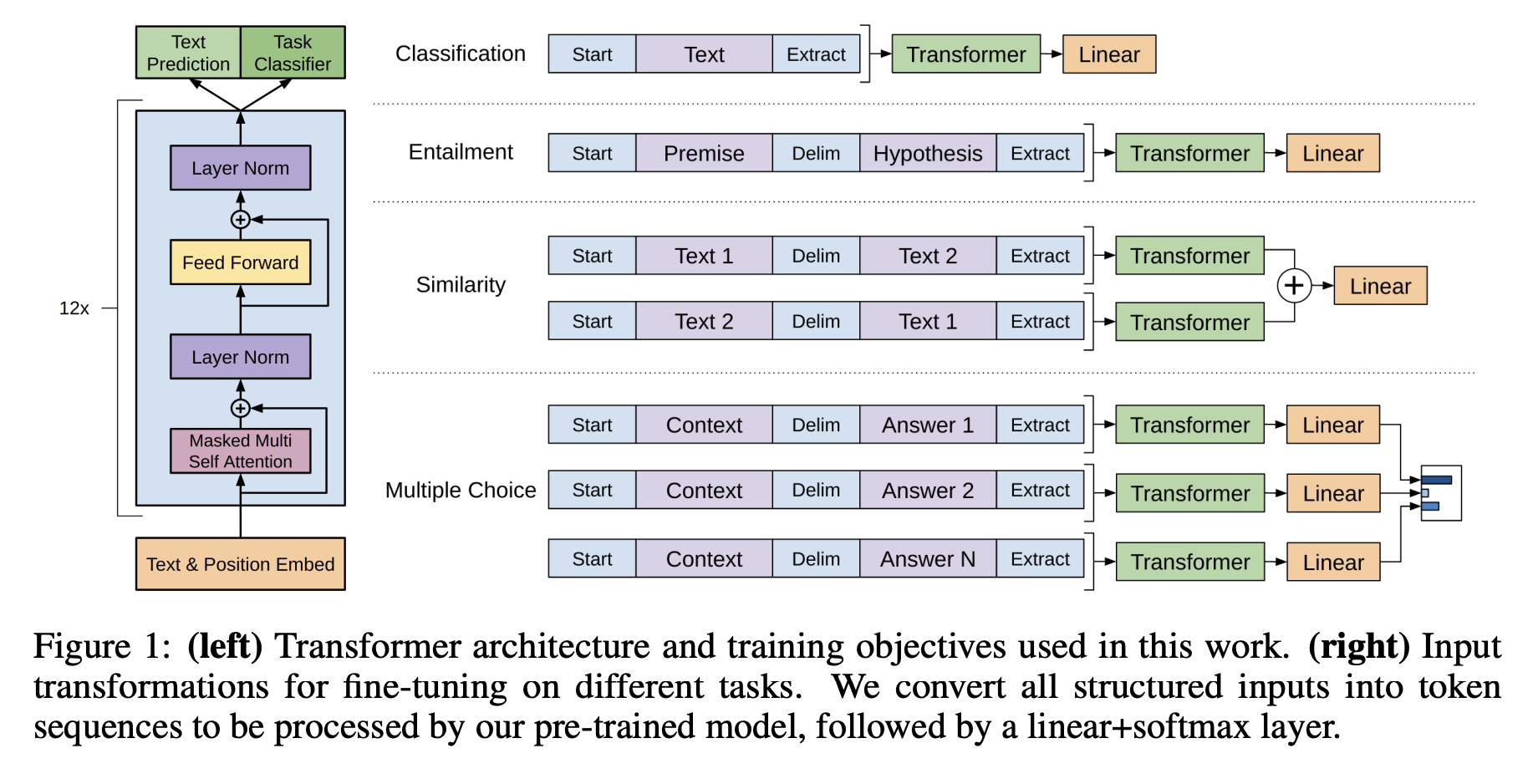
- Transformer decoder 구조 활용
- multi-headed self-attention, position-wise feedforward layers
- 더욱 긴 범위의 언어적 구조를 학습할 수 있도록 도와줌
generative pre-trianing
- 비지도학습 방식(=unsupervised) 사용
- 약간의 adaptation만으로도 다양한 태스크를 수행할 수 있는 보편적인 표현(=representation)을 배우는 것이 목표
- 중요한 세상에 대한 지식을 학습 (factual knowledge)
- 긴 범위의 dependency를 처리할 수 있는 능력을 습득 (linguistic knowledge)
- 일반적인 language modeling objective와 마찬가지로 앞의 문맥이 주어졌을 때 다음 토큰을 예측하는 방식을 사용해 학습
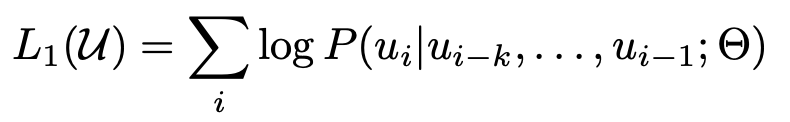
discriminative fine-tuning
- 지도학습 방식(=supervised) 사용
- 사전학습 모델에 input을 넣고 마지막 transformer 블록의 activation h를 얻은 후, 이를 파라미터 W와 함께 추가된 linear layer에 통과시켜 정답을 예측
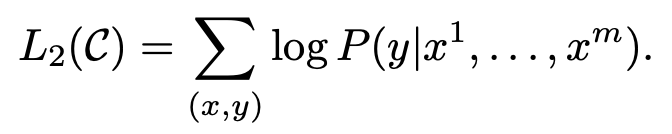
- language modeling을 보조적인 목적함수로 추가
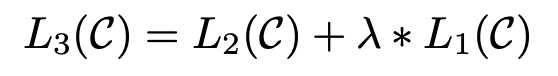
- 지도학습 모델의 일반화 성능을 향상
- 수렴(convergence)을 가속화
- 사전학습 시 일련의 연속적인 텍스트를 활용해 학습했기 때문에, input transformation을 사용
- input을 순서가 있는 시퀀스로 변형 (traversal-style approach)
평가
- 사전학습
- BookCorpus로 학습
- 파인튜닝
- Natural language inference
- 두 개의 문장 사이의 관계를 파악하는 태스크 (포함, 모순, 중립)
- 데이터셋: SNLI, MNLI, QNLI, SciTail, RTE
- Question answering
- 데이터셋: RACE, Story Cloze Test
- Semantic similarity
- 두 개의 문장이 의미적으로 동일한지 아닌지 판단하는 태스크
- 데이터셋: MRPC, QQP, STS-B
- Text classification
- 데이터셋: CoLA, SST-2
- Natural language inference
- 12개의 데이터셋 중 9개에서 최고(state-of-the-art) 성능을 달성
한계
- 자연어 생성(NLG)보다는 자연어 이해(NLU)에 중점을 둔 모델
의의
- 이전 연구들과는 다르게 파인튜닝 시 모델 아키텍처에 최소한의 변화(transformation)만을 필요로 함
- fine-tuning 시 linear layer에 사용되는 파라미터 W와 delimiter token을 위한 임베딩만이 추가됨

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab