Continual Pre-training of Language Models ICLR 2023
분야 및 배경지식
- 연속학습 (continual learning)
- 동일한 언어모델을 연속적으로 다른 도메인/태스크 등에 대해 학습하는 연구 분야
- 이전에 학습한 지식을 까먹는 문제(=catastrophic forgetting)와 태스크 간 지식전이(=knowledge transfer)가 주요한 성능 지표
- 이전에 학습한 데이터를 다시 사용하거나(=memory replay), 학습 태스크마다 모델의 독립적인 다른 부분을 학습하거나(=parameter isolation), regularizer를 사용하는 등 다양한 방법론이 제시됨
- continual domain-adaptive pre-training (DAP-training)
- 언어모델을 레이블이 없는 도메인 코퍼스(언어뭉치)에 대해서 연속적으로 사전학습하여 최종 태스크의 성능을 높이고자 하는 연구 분야
문제점
- continual domain-adaptive pre-training (DAP-training)에 대한 연구 미비
해결책
DAS (Continual DA-pre-training of LMs with Soft-masking)
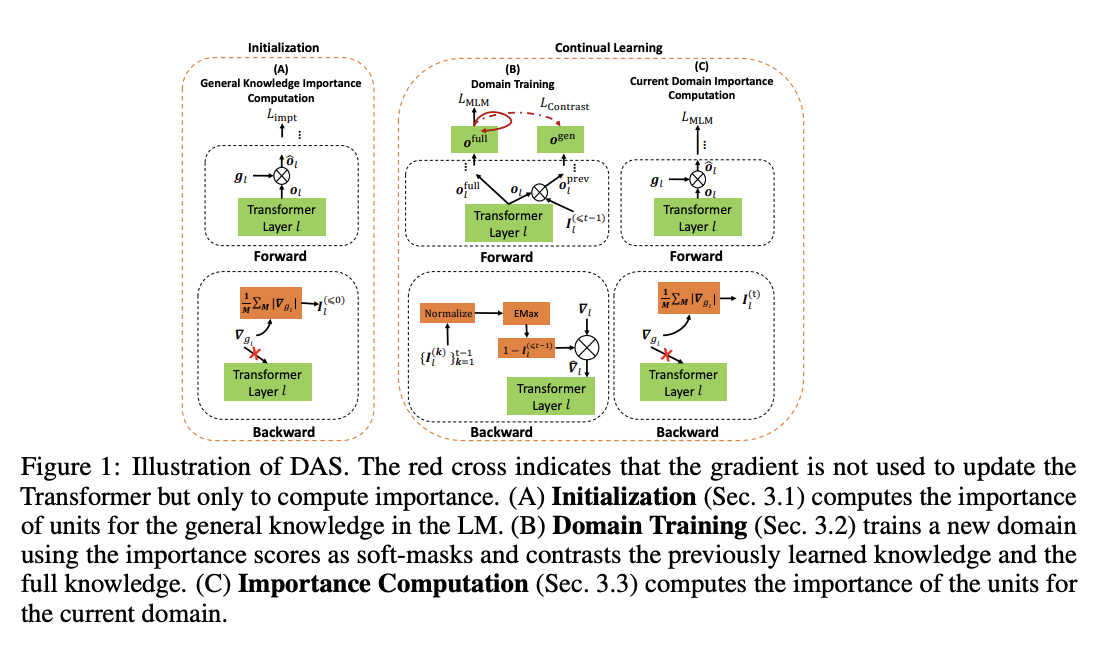
- 일반적인 지식 혹은 도메인 지식과 연관된 유닛의 중요도를 계산하여 이를 기반으로 약한 마스킹을 적용하는 방식
- 이를 통해 backward gradient flow를 통제함
- 별도의 독립적인 부분만을 학습하는 방식은 아님
- parameter isolation 방식과 구분됨
novel proxy for initialization
- 언어모델이 이미 학습한 일반적인 지식의 중요도를 측정
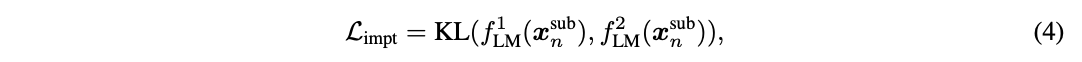
- 중요도 계산의 경우 데이터셋이 필요하나 언어모델이 이미 학습한 사전학습 데이터가 없기 때문에, 도메인 데이터셋 일부(x^sub_n)와 KL-divergence loss를 활용
- 언어모델(f^1_LM, f^2_LM)에 각기 다른 dropout mask를 사용하여 강건성을 높임
soft-masking
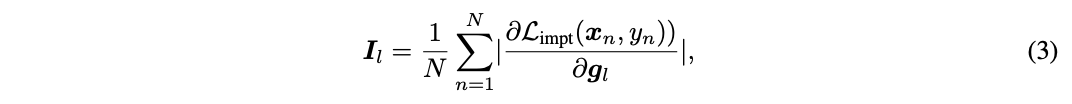
- 각 도메인에 대해 중요도를 계산하고 이를 통해 약한 마스킹을 진행 (⬆️)
- 중요도 계산의 경우 가상의 파라미터를 활용한 gradient 기반의 방법 차용
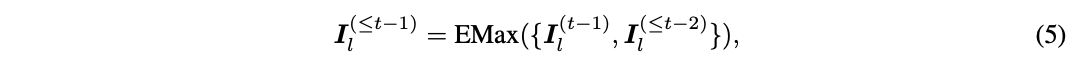
- EMax (element-wise max)를 통해 중요도를 누적 (⬆️)
- 모든 태스크의 중요도를 저장하는 것이 아니라 누적 중요도 값만을 저장
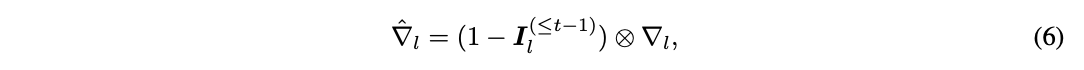
- 계산된 중요도값(I)을 연관된 파라미터에 적용 (⬆️)
- 중요도 값은 0, 1의 binary 값이 아니라 0과 1 사이의 값이기 때문에, 약한 마스킹(soft masking)
- 이를 통해 catastrophic forgetting을 감소시키고 도메인 사이의 knowledge transfer를 촉진시킴
constrastive learning
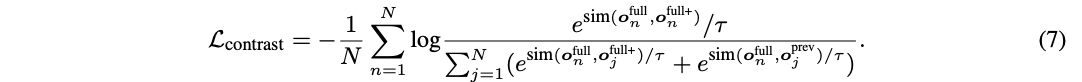
- 이전에 학습한 지식과 전체 지식 사이의 대조학습을 통해 지식 통합(knowledge integration)을 촉진
- o^full이 기준값, o^full+가 다른 dropout을 적용한 긍정 샘플, o^prev가 부정 샘플
- 최종적인 loss function은 MLM loss와 contrast loss를 결합한 값
평가
- 데이터셋
- 사전학습: Yelp Restaurant, Amazon Phone, Amazone Camera, ACL papers, AI Papers, PubMed Papers
- 파인튜닝: Restaurant, Phone, Camera, ACL, AI, PubMed
- 모델
- RoBERTa
- CL, non-CL baseline과 다양하게 비교, 더 좋은 성능을 보임
- forgetting rate이 낮음
- 최종 태스크에 대한 평가 성능이 전반적으로 높음
한계
- RoBERTa 모델에 대해서만 연구 진행
- MLM loss를 사용하여 다른 autoregressive model에는 확장하기 어려운 방법
- 비용 효율적이지 않아 보임
- 논문을 통해 확인한 loss만 해도 MLM loss, contrastive loss, 중요도 계산을 위한 KL-divergence loss, Importance loss 등
의의
- 연속적인 DAP-training이라는 새로운 분야에 대한 연구
- 비교하는 baseline이 다양하며 충분한 실험을 진행
- 파인튜닝을 통한 최종 태스크의 성능을 측정 시 이전에 학습한 도메인의 ID 없이도 예측(inference) 가능

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab