Knowledge Infused Decoding
ICLR 2022
분야 및 배경지식
- NLG (Natural Language Generation)
- 모델이 자연어 문장 혹은 텍스트를 생성
- decoder와 연관
- Decoding strategies (link)
- 일반적으로 모델은 문장을 생성할 때 한 번에 하나의 토큰을 생성하는데, 이렇듯 토큰을 생성할 때 선택할 수 있는 여러 전략이 존재
- Greedy Search
- 각 timestep마다 가장 확률이 높은 토큰을 선택
- 가장 확률이 높은 토큰은 가장 일반적이고 무난한 토큰일 확률이 높아 최적이 아닌 결과를 도출하기도 함
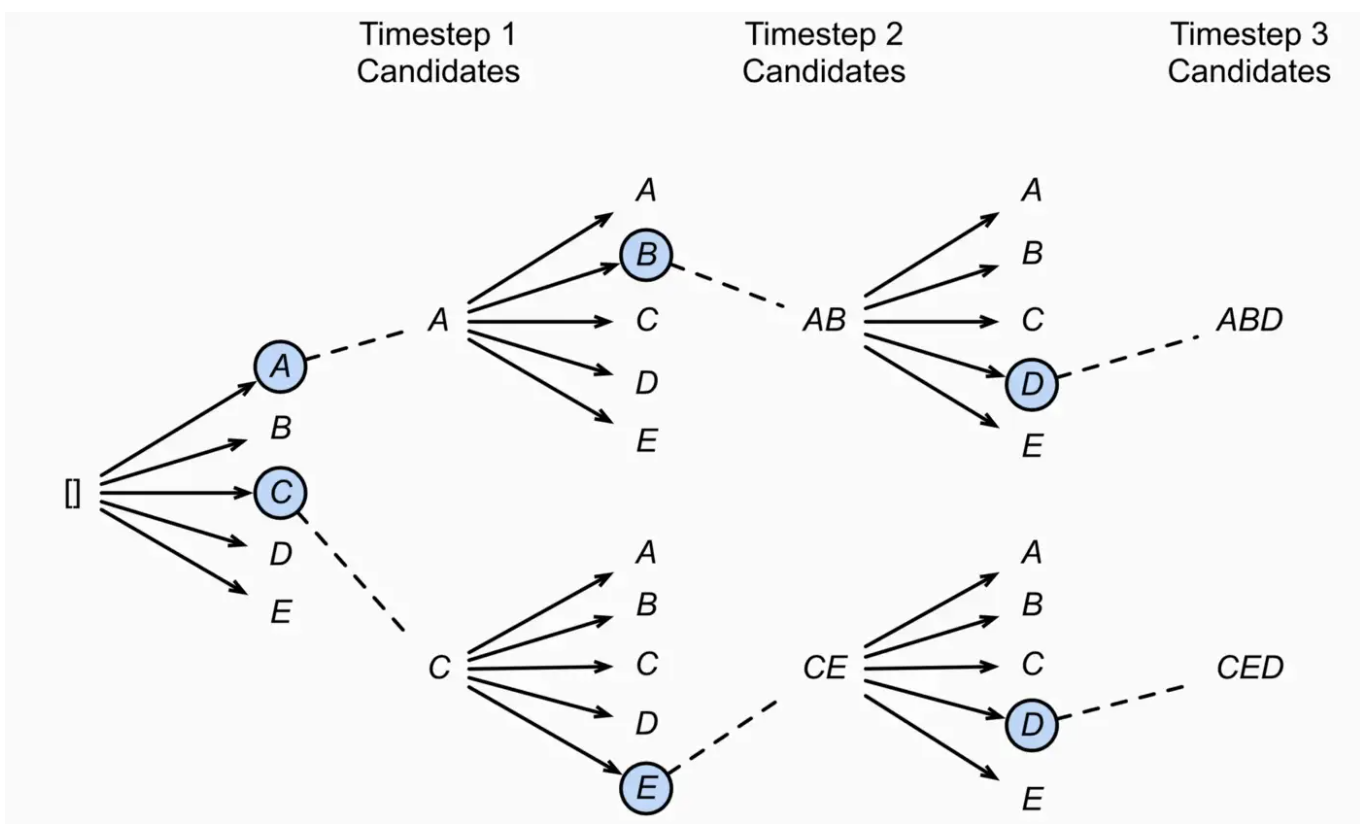
- Beam Search
- 각 timestep마다 vocab list에서 가능한 모든 토큰을 만들고 만들어진 시퀀스 중 가장 확률이 높은 N 개의 후보만 선택, 해당 후보들은 다음 timestep으로 넘어가며 해당 프로세스가 반복
- 모든 경우를 다 고려하는 것보다 계산효율적임과 동시에 괜찮은 문장을 생성할 수 있음
- Top-K Sampling
- 확률이 낮은 단어는 생성 시 고려대상에서 완전히 제외되도록 함
- 오직 상위 K개의 가능성 있는 토큰들만 생성 시 고려됨
문제점
- 사전학습 모델은 상당한 양의 지식을 기억하고 있으나, 사실적 지식을 올바르게 재현하는 데에 있어 한계를 가짐
- 기존 연구들의 한계
- 방법 1. 목적함수(objective) 혹은 아키텍처 변경
- 학습에 있어 비용이 더욱 많이 듦
- 수정 혹은 확장이 어려움 (as implicitly parameterized)
- 잘못된 생성을 진단하기 어려움 (lack of interpretation)
- 방법 2. Retrieval-based model
- 새로운 토큰이 생성됨에 따라 역동적으로 변모할 수 있는 문맥(context)의 본질을 제대로 지원하지 못함
- 방법 1. 목적함수(objective) 혹은 아키텍처 변경
해결책
Knowledge Infused Decoding (KID)
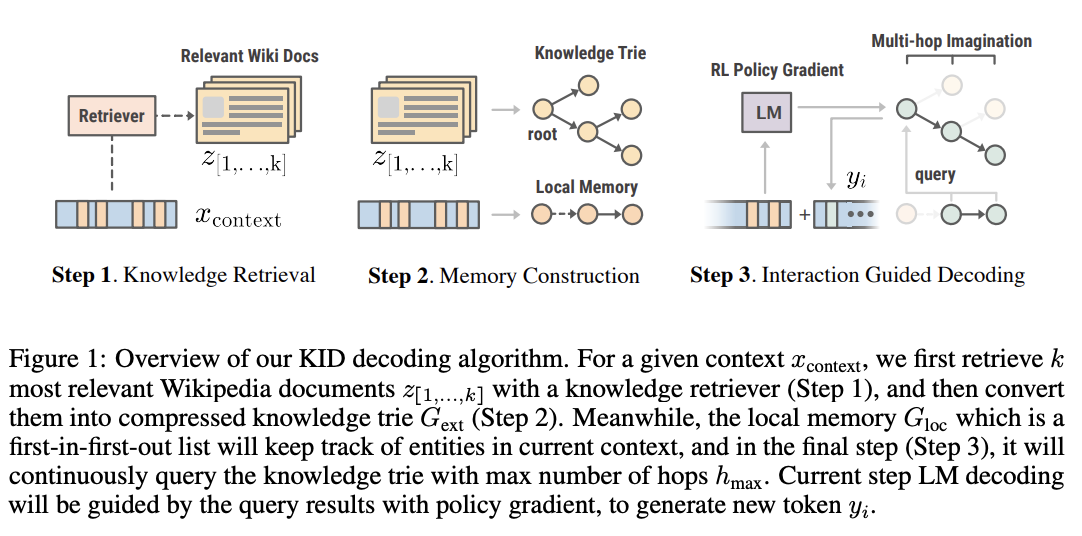
- 언어모델이 디코딩을 하는(=토큰을 생성하는) 각 스텝마다 외부의 지식을 역동적으로 주입시키는 새로운 decoding algorithm
- 현존하는 사전학습 언어모델의 목적함수는 일반적으로 token-level로 정의되어 있으며, 명시적으로 지식에 대해 모델링하지 않았음에 아이디어를 얻음
- Knowledge Retrieval
- DPR을 활용해 연관성이 있는 상위 3개의 문서들을 검색(Retrieval)
- DPR이란 context와 관련있는 문서(document)들을 bi-encoder 네트워크를 사용해 768 차원의 shared embedding에 투사하는 방식
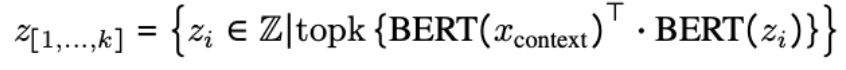
- DPR이란 context와 관련있는 문서(document)들을 bi-encoder 네트워크를 사용해 768 차원의 shared embedding에 투사하는 방식
- RAG가 공개한 문서 사용
- 위키피디아 문단을 100개의 단어 기준으로 잘라 총 21M개의 문서를 knowledge source로 활용
- Memory Construction
- 외부 메모리 (External Memory) (Green)
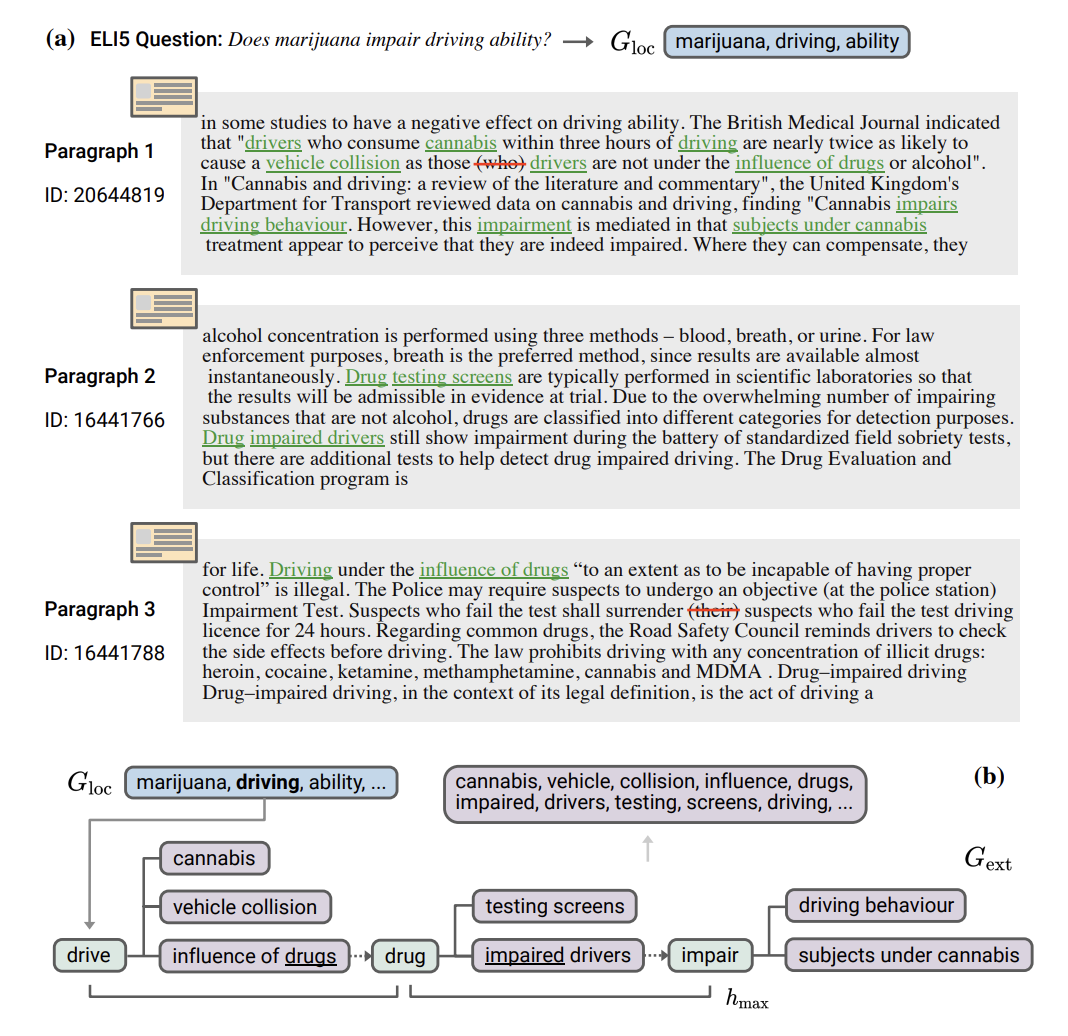
- OpenIE를 활용해 선택된 triplet의 end node(주어, 목적어)를 annotate
- OpenIE는 평범한 문장을 triplet 형태로 변경
- e.g. Iceland is a Nordic island country in the North Atlantic Ocean and it is the most sparsely populated country in Europe. -> ⟨subj:Iceland, rel:is,obj:Nordic island country⟩, ⟨subj:Iceland, rel:is, obj:most sparsely populated country in Europe⟩
- 해당 triplet을 활용해 Knowledge Trie (=prefix tree)를 생성
- 주어는 key, 관계는 edge, 목적어는 value
- offline으로 생성
- OpenIE를 활용해 선택된 triplet의 end node(주어, 목적어)를 annotate
- 로컬 메모리 (Local Memory) (Blue)
- input context에 있는 개체(entity)로 초기화
- online으로 update
- Interaction Guided Decoding
- 로컬 메모리에 있는 각각의 개체(entity)를 Key로 사용해 외부 메모리에 쿼리를 날려 Knowledge demonstration (Purple) 수집
- Value가 Key를 가진다면, 다시 쿼리를 날림 (최대 hop까지)
- 새로운 개체(entity)가 생성된다면 로컬 메모리 업데이트
- policy gradient를 통해 updated policy를 얻고 이를 활용해 새로운 토큰을 생성
평가
- Tasks
- Abstractive Question Answering: ELI5, MSMARCO
- Logic-centric Writing: ROC, alphaNLG
- Dialogue Generation: WoW, MuTual
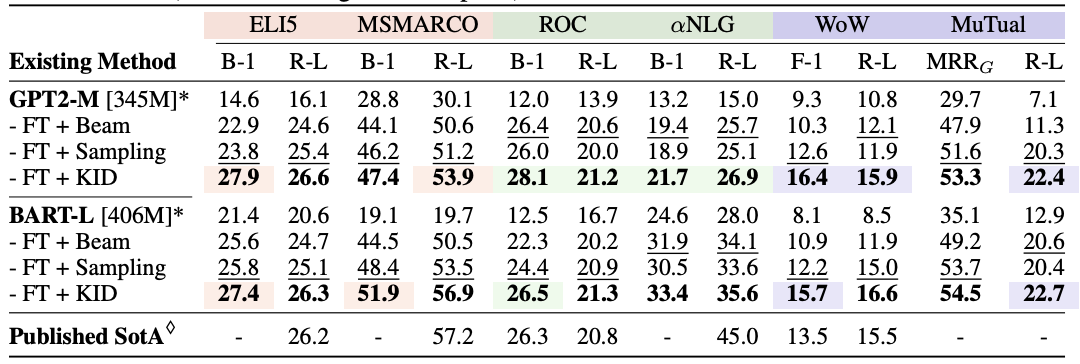
- 다른 decoding 방식들과 비교했을 때 ELI5, ROC, WoW에서 SOTA 성능
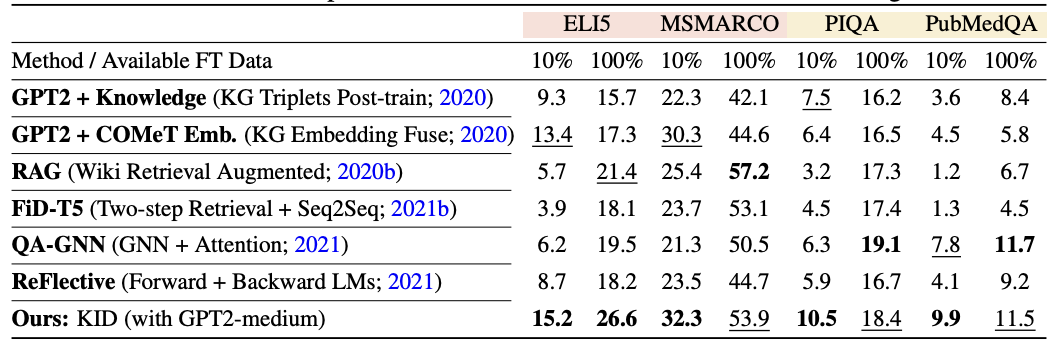
- 다른 Knowledge-infusion 방식과 비교했을 때 few-shot에서 좋은 성능
- 이밖에도
- 사람의 평가에도 좋은 성능
- 파인튜닝되지 않은 언어모델에서 더 좋은 성능
- exposure bias를 완화하는 효과 (문장 길이와 관계없이 안정적인 품질을 보여줌)
한계
- Reviewer said...
- 논문 이해의 어려움
- baseline 선택의 이유가 명확하지 않음
- 이러한 의견을 참고해 저자들은 더 자세한 설명과 baseline을 추가
- Decoding 시간이 굉장히 오래 걸림
- web demo를 이용했을 때 약 11분이 걸림 (Nvidia T4 GPU)
- 직접 실험했을 때 약 6분이 걸림 (Titan XP GPU)
- 또한 논문에서 태스크나 데이터셋에 따라 추론 시간이 달라질 수 있음을 언급함. practicality가 다소 떨어짐
의의
- Reviewer said...
- 어떤 모델 혹은 태스크에도 활용될 수 있는(model and task agnoastic) 재학습이나 파인튜닝이 필요없는 방법
- 고정적인(static) knowledge retrieval 대비 역동적으로 외부 지식을 주입한다는 점에서 장점을 가짐
- baseline 대비 성능 개선

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab