FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
language-model
목록 보기
13/20
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (link)
배경지식
- GPU의 특징
- 병렬성 (Parallelism)
- GPU는 캐시, 컨트롤러 등을 없애고 더 많은 공간을 연산에 할당
- CPU 대비 더 많은 단순한 코어들을 이용해 병렬 연산 가능
- 높은 메모리 밴드위스(bandwidth)
- 이 말은 데이터를 더욱 빠르게 처리할 수 있다는 의미이며, 대량의 데이터를 처리할 때 중요
- 병렬성 (Parallelism)
- Thread(스레드)와 Warp(와프)
- thread란 GPU에서 데이터 처리를 수행하는 가장 작은 단위
- 독립적인 fetch-decode-execution loop
- CUDA에서의 thread = OpenCL에서의 work-item
- warp란 그룹으로 ALU에서 실행되는 thread들의 집합
- GPU 스케줄링의 기본 단위
- NVIDIA의 경우 32개의 하드웨어 thread를 의미
- thread란 GPU에서 데이터 처리를 수행하는 가장 작은 단위
- Occupancy (점유율)
- SM(Streaming Multiprocessor)의 활성 워프의 수와 SM이 지원하는 최대 활성 워프 수의 비율
- 낮은 점유율은 종속적인 명령어(instruction) 사이 지연 시간(latency)를 숨기기에 충분한 워프가 없기 때문에 명령어 실행 효율이 떨어짐
문제점
- Attention 레이어는 더 긴 시퀀스를 처리할 때 장애물이 됨
- 런타임과 메모리가 시퀀스 길이가 증가함에 따라 quadratic하게 증가
Flash Attention
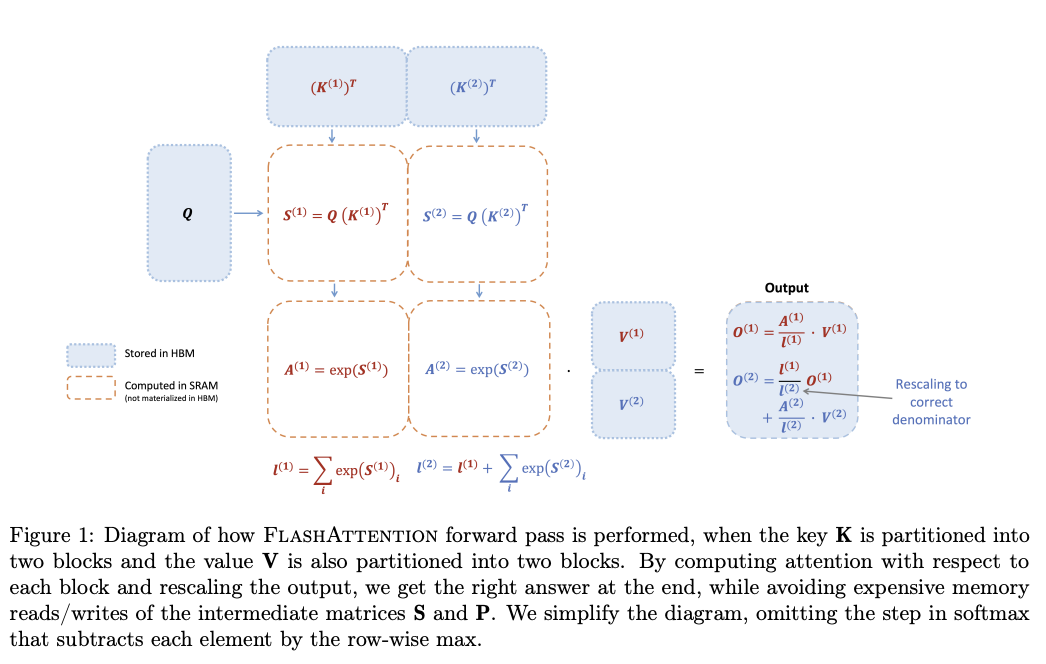
- 비대칭적인 GPU 메모리 계층구조를 이용하여 메모리 사용을 줄였으며 (quadratic to linear) 런타임을 개선
- 1) HBM에서 SRAM으로 인풋 블록을 로드하고, 2) 해당 블록에 대해 attention을 계산한 뒤, 3) 연산 과정에서 등장하는 거대한 중간(intermediate) 행렬을 HBM에 저장하지 않고 결과값을 업데이트
- online softmax를 활용해 attention 연산을 블록 단위로 나눔
- 하지만, 이론적으로 최대 FLOPs/s의 25-40% 정도의 성능을 보임
- 이러한 비효율성은 GPU의 다른 thread block과 warp 사이에 작업 분배(work partitioning) 최적화가 이루어지지 않기 때문
- 낮은 점유율 (low-occupancy)
- 불필요한 공유 메모리의 읽기/쓰기 작업
해결책
FLASH ATTENTION - 2
알고리즘 일부 변형
- non-matmul FLOPs의 수를 감소
- non-matmul FLOPs는 전체 FLOPs의 일부만을 차지
- GPU의 경우 행렬 곱셈(matrix multiplication)에 최적화되어 있기 때문에 non-matmul 연산이 더욱 오래 걸림 (약 16배 차이)
여러 thread block에서의 병렬화
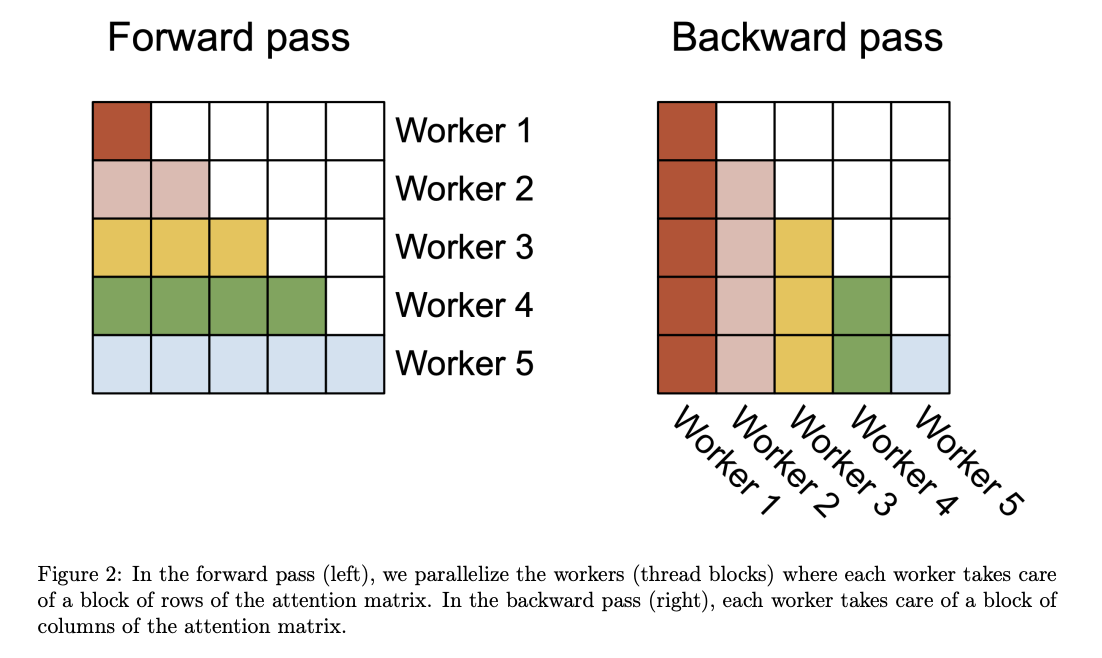
- Flash attention의 경우, 배치 사이즈와 헤드 수에 대한 병렬화 진행
- 배치 사이즈와 헤드 수가 많을 경우 유용
- 시퀀스 길이가 긴 경우 일반적으로 배치 사이즈와 헤드 수가 작기 때문에, 비효율 발생
- Flash attention 2에서는 이에 추가적으로 시퀀스 길이 차원에서 병렬화 적용
단일 thread block의 warp에서 작업 분배
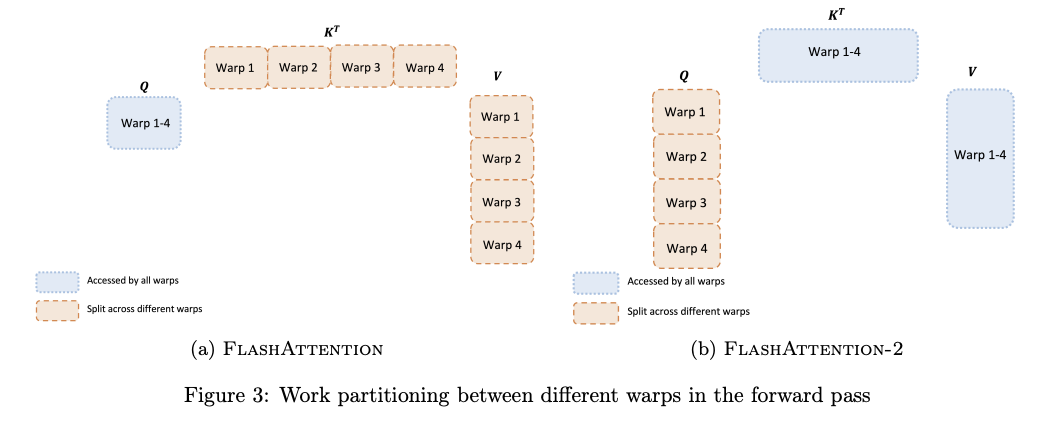
- 단일 thread block 내의 여러 와프들 사이 작업 분배 방식을 변경
- Q가 아니라 K, V에 대해 모든 와프들이 접근 가능하도록 함으로써 이전에 발생했던 불필요한 공유 메모리 읽기/쓰기 작업 삭제
- 즉, "split-K"를 피하는 방식
평가
- Flash attention 대비 2배의 속도 향상
- 이론적인 최대 FLOPs/s의 50-73% 달성
참고 링크
- NVIDIA occupancy 설명 (link)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab