KERPLE: Kernelized Relative Positional Embedding for Length Extrapolation (NeurIPS 2022, link)
배경지식
- Absolute positional embeddings (APE)
- 절대적 위치 임베딩
- 각 위치에 위치 벡터를 할당하고 이를 임베딩 벡터에 더하는 방식
- 초기에는 미리 정의된 sinusoidal function을 활용, 이후에는 학습 가능한 APE를 활용
- Relative positional embeddings (RPE)
- 상대적 위치 임베딩
- 토큰들 사이의 상대적인 거리를 모델링
- extrapolation을 가능케 함
- 즉, 학습하지 않은 시퀀스의 길이에 대해서도 (e.g. 더 긴 시퀀스의 길이) 추론 시 잘 동작하도록 함
- Kernel
- 커널 트릭은 머신러닝에서 데이터를 고차원 공간으로 변환하여 더욱 쉽게 분류할 수 있도록 하는 기법
- 모든 데이터를 명시적으로 고차원으로 변환하는 것은 비용이 많이 들기 때문에, 커널 함수를 사용하여 암시적으로 변환 수행
- 커널 함수는 두 데이터 포인트 간 유사성을 계산하는 함수로, 고차원 공간에서의 내적을 계산
- Transformer 분야에서 커널을 self-attention에 적용하여 성능을 개선하려는 연구가 진행됨
- 커널 트릭은 머신러닝에서 데이터를 고차원 공간으로 변환하여 더욱 쉽게 분류할 수 있도록 하는 기법
문제점
- 상대적 위치 임베딩(RPE)의 필요성
- 절대적 위치 임베딩(absolute positional embedding)을 가진 Transformer 모델은 학습하지 않은 시퀀스 길이에 대해서는 추론 시 잘 동작하지 않음
- 절대적 위치 임베딩에 대한 extrapolation 연구도 존재하나, 일반적으로 RPE가 다양한 인풋 길이 변화에 강건하게 작동한다고 알려짐
해결책
KERPLE
- KErnelize Relative Positional Embedding for Length Extrapolation의 줄임말
Conditionally Positive Definite (CPD) kernels

- shift-invariance를 가정함으로써, 상대성을 모델링
- shift-invariance란 입력의 절대적인 위치가 아니라 그 차이에만 의존한다는 의미
- a bivariate function k over two positions (m, n) such that k(m, n) = f(m − n) for some univariate f
- CPD kernel은 거리 측정을 고차원 공간으로 일반화할 수 있도록 해줌
- 하지만 Self Attention을 수행하려면 내적(inner product)이 수행되어야 하는데, CPD kernel은 내적을 인코딩하고 있지 않음
PD kernel
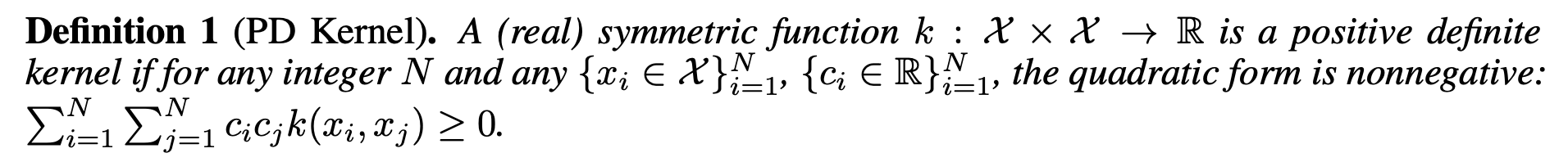
- CPD kernel에 충분히 큰 상수를 더해 PD kernel 구축 가능
- PD kernel을 활용해 self-attention 구현 가능
- 해당 상수는 self-attention 시 Softmax normalization을 거치면서 내재적으로 흡수됨
- 다시 말해, Softmax normalization 덕분에 정확한 상수 값을 결정해야 할 필요가 없음 (아래 식 참고)
Kernelized Relative Positional Embedding
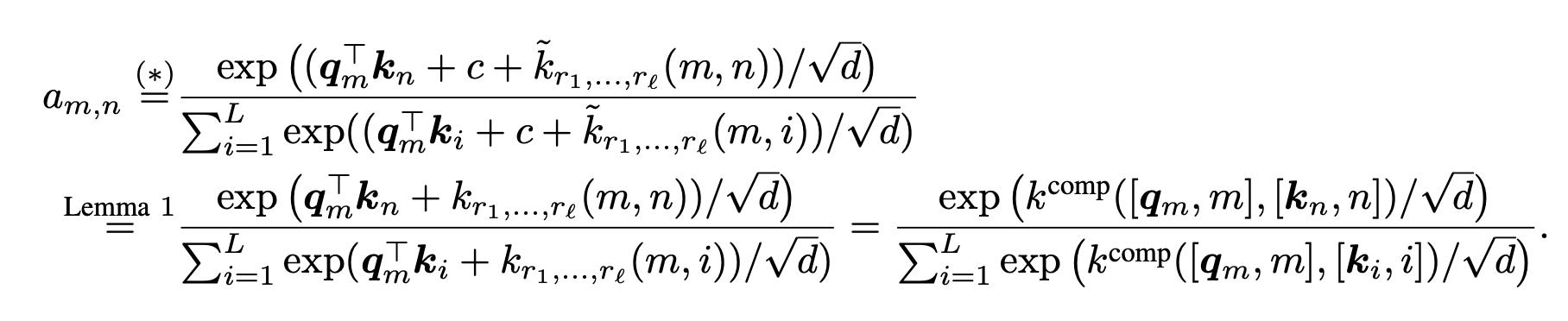
- q_m은 인풋 쿼리, k_n은 인풋 키, (r_1, ...r_l)은 학습 가능한 파라미터
- k^~은 l 파라미터를 가진 shift-invariant CPD kernel
- *은 Softmax normalization의 변화에 무관한 특성 때문에 발생
- 설명하자면, self-attention에 composite kernel(합 커널)을 적용한 것이라고 해석할 수 있음
- composite kernel이 곱셈(multiplicative), 덧셈(additive) 위치 임베딩을 통해 기존의 self-attention의 구조를 풍성하게 하는 방식으로 q_m (쿼리), k_n (키), (m,n) (위치) 정보를 결합한 것
- 여러 composite kernel 종류 중, composite kernel의 두 가지 변형에 대해 실험
- power variant
- logarithmic variant
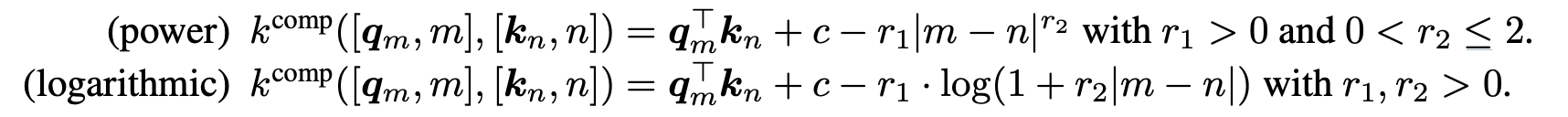
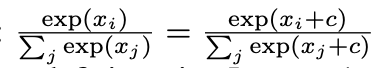
평가
- 데이터셋
- OpenWebText2
- GitHub
- ArXiv
- 모델
- GPT-NeoX
- 평가지표
- Perplexity
- logarithmic variant가 가장 우수한 extrapolation 성능을 보임

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab