Generative Prompt Tuning for Relation Classification
EMNLP 2022
분야 및 배경지식
- Masked Language Modeling (=MLM)
- BERT, RoBERTa 등의 사전학습 모델을 학습할 때 사용한 방식
- 문장에서 임의의 토큰을 MASK 토큰으로 치환, 모델이 해당 토큰을 유추하도록 학습
- Cloze-style template (prompt)
- 프롬프트 중에서는 MLM과 유사한 형식을 가진 빈칸 채우기(=cloze) 템플릿이 존재하는데, 이는 사전학습 태스크의 학습 방식을 모방하여 다운스트림 태스크의 성능을 높이기 위함임
- 일반적으로 템플릿 내의 MASK 토큰은 하나의 토큰을 verbalization으로 가지기 때문에, 임의의 길이를 가진 레이블(정답)을 맞추기 쉽지 않음
문제점
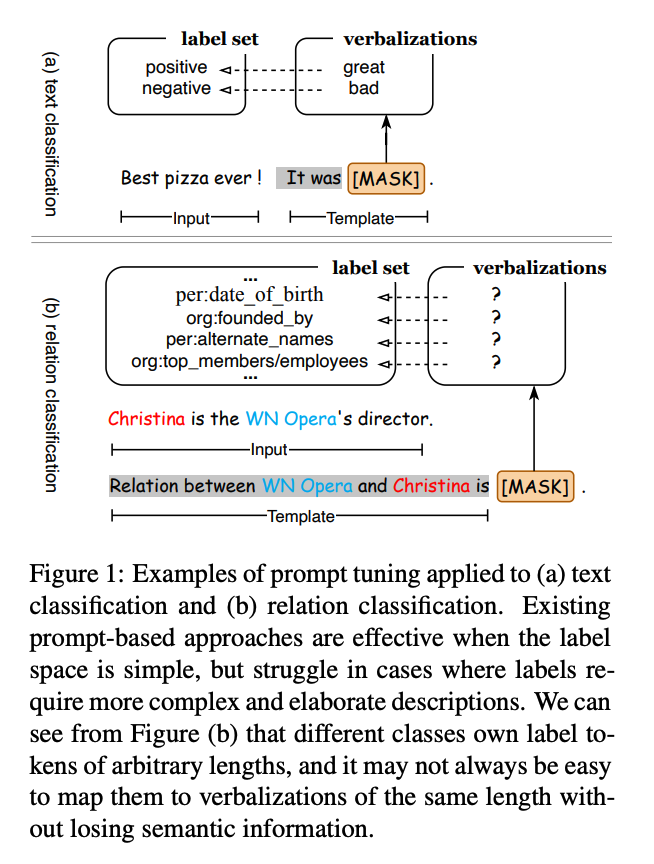
- 프롬프트를 단순히 Masked Language Modeling과 유사한 방식으로 표현한다면, 프롬프트 포맷의 제한 때문에 임의의 길이를 가진 정답을 제대로 예측할 수 없음
해결책
GenPT (Generative Prompt Tuning)
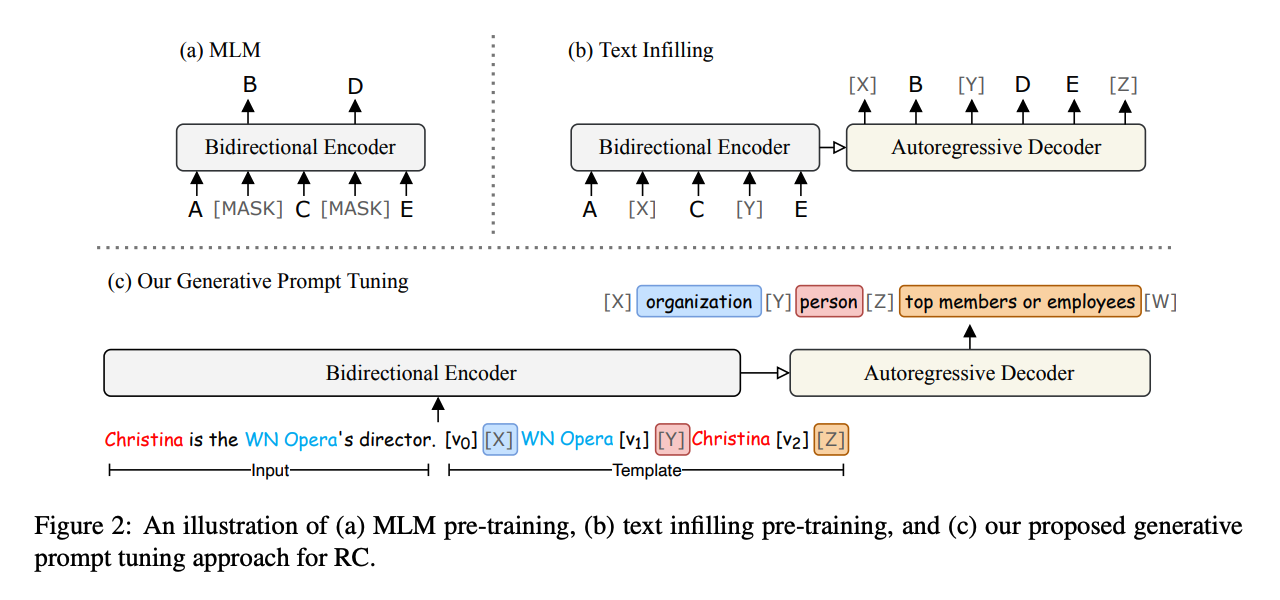
relation classification 태스크를 infilling으로 재구성
- 분류 문제를 텍스트 채우기 태스크로 재구성
- 인풋과 템플릿이 주어지면 관계를 예측할 수 있는 타겟 시퀀스를 생성하는 문제로 변경
entity-oriented prompt
- 자연어로 이루어진 discrete prompt가 아니라 continuous prompt를 활용
- T(x) = x.[v_0:n0-1][X]e_h[v_n0:n1-1][Y]e_t[v_n1:n2-1][Z]
- template with prompts and input
- v로 이루어진 부분: continuous prompt
- e_h, e_t: 개체 (entity)
- [X], [Y]: 개체의 타입 (e.g. 조직, 사람)
- [Z]: 관계 레이블 토큰을 의미
entity-guided decoding and scoring
- 가능한 후보 관계들의 선택에 내재적으로 영향을 주기 위해 개체의 타입 정보를 이용
- y = [X]t_h[Y]t_t[Z]r[W]
- target sequence
- t_h, t_t: 개체의 타입
- r: 레이블 verbalization
- [W] : 구분자 (delimiter)
- label verbalization의 토큰들의 예측된 확률을 더해 verbalization의 길이로 정규화된 값을 prediction score로 사용
평가
- 태스크
- Relation Classification (관계 구분)
- 데이터셋
- TACRED, TACREV, Re-TACRED, Wiki80
- 모델
- T5-large, BART-large, RoBERTa-large
의의
- 분류 문제를 생성 문제로 재구성하여 기존 템플릿의 한계를 극복
- full-shot, few-shot에서 좋은 성능을 보임
- 개체와 개체의 타입이라는 semantic을 효과적으로 활용
한계
- Relation classification에 국한
- discriminative method에 비해 generative method는 autoregressive nature 때문에 시간 효율성이 떨어짐

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab