강화학습이란
- 에이전트(AI)가 시행착오(trial and error)를 거치면서 환경(environment)과 상호작용하고 어떤 행동(action)을 수행함에 있어서 피드백으로써 보상(reward; 긍정, 부정)을 받음으로써 학습하는 방법
- 결정 문제(decision problem; 통제 태스크라고 불리기도 함)를 해결하기 위한 프레임워크
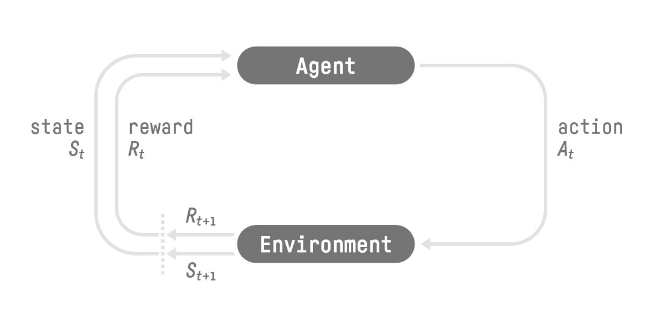
- 환경으로부터 상태(state_0)를 받아 에이전트가 행동(action_0)을 취함
- 환경은 새로운 상태(state_1)로 향하고 에이전트에게 보상(reward_1)을 줌
- 강화학습의 루프는 state_0, action_0, reward_1, state_1(next state)의 시퀀스로 이루어짐
- 기대 리턴(expected return)이라고 불리는 누적 보상을 최대화하는 것이 목표
Markov Property
- 강화학습 process는 Markov Decision Process(MDP)라고도 불림
- 에이전트는 오직 어떤 행동을 취할 지 결정함에 있어서 현재의 상태만이 필요하며 이전에 취했던 행동과 상태 정보는 필요하지 않음
Observation, State Space
- 관찰(Observation)과 상태(State)는 에이전트가 환경으로부터 얻는 정보
- 상태(state): 감춰진 정보 없이 환경의 모든 정보를 관측할 수 있는 상태 (e.g. 체스게임의 체스판)
- 관찰(observaion): 일부 정보만 관측할 수 있는 상태 (e.g. 슈퍼마리오 게임에서 스크린에 보이는 화면)
Action Space
- 환경에서 가능한 모든 행동
- discrete space (discrete; 별개의): 가능한 행동의 수가 한정적 (e.g. 슈퍼마리오처럼 앞, 뒤, 위, 아래만 움직일 수 있는 경우)
- continuous space (continuous; 연속적인): 가능한 행동의 수가 무제한 (e.g. 자율주행차)
Rewards, discounting
- 보상은 에이전트에게 있어 유일한 피드백이기 때문에 굉장히 중요
- 보상을 기반으로 에이전트는 어떠한 행동이 취해져야 할지 아닐지를 결정
- 누적 보상 = 시퀀스 내의 모든 보상의 합
- 하지만 초기의 보상일수록 예측이 쉽고 발생 가능성이 높기 때문에 단순히 누적합을 구하는 것은 옳지 않음
- e.g. 쥐가 고양이를 피해 치즈를 최대한 많이 먹는 방법을 학습한다고 할 때, 고양이 근처에 치즈가 더 많다고 할지라도 고양이에게 잡아먹힐 수도 있기 때문에 발생 가능성이 낮음
- 이 때문에 discount rate인 gamma를 활용
- 감마가 클수록 discount가 작음, 장기적인 보상을 중시
- 감마가 작을수록 discount가 큼, 단기적인 보상을 중시

Task types
- Episodic task
- 시작점과 종료점이 있는 경우
- 에피소드(= 상태, 행동, 보상, 새로운 상태의 리스트) 생성 (e.g. 슈퍼마리오 게임)
- Continuing task
- 종료점이 없이 영원히 지속되는 태스크
- 최고의 행동을 선택함과 동시에 환경과 상호작용하는 방법을 학습 (e.g. 자동주식거래)
Exploration & Exploitation trade-off
- Exploration(탐구): 환경에 대한 더 많은 정보를 찾기 위해 무작위 행동을 시도
- Exploitation(이용): 보상을 최대화하기 위해 알고 있는 정보를 이용
- 이용만 추구하다보면 당장 보상은 얻을 수 있지만 멀리 위치한 큰 보상을 놓칠 가능성이 있음
- 탐구를 추구하다보면 멀리 위치한 큰 보상을 얻을 수 있으나 실제로 보상이 존재하지 않을 수도 있기 때문에 위험부담을 지님
- 때문에 환경을 얼마나 탐구할지와 환경을 얼마나 이용할지 사이의 균형을 잘 잡아야 함 (trade-off)
강화학습을 위한 해결책
- policy(π)
- 에이전트의 뇌에 해당하는 것으로 주어진 상태(state)에서 어떤 행동을 취할 것인지 알려주는 함수
- 주어진 때에 에이전트의 행동을 규정
- 바로 이 Policy가 우리가 학습하고자 하는 함수이며, 기대 리턴을 최대화하도록 policy를 최적화
Policy-based, Value-based
-
Policy-based
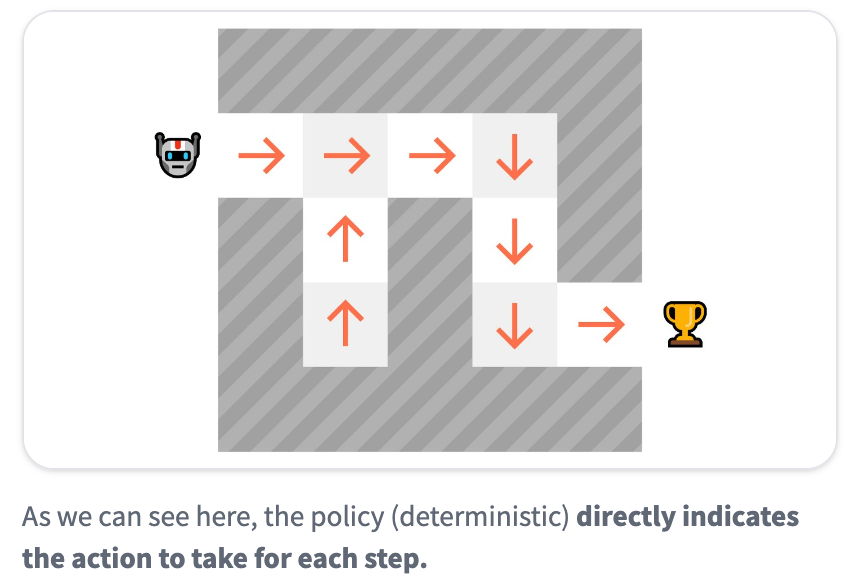
- 주어진 현재 상태에서 어떤 행동을 취할 것인지 학습 (직접적으로 policy function 학습)
- 각각의 상태와 상응하는 최고의 행동 사이의 mapping을 학습
- 해당 상태에서 가능한 행동들에 대한 확률분포를 학습
- deterministic policy: 주어진 상태에서 언제나 동일한 행동을 리턴하는 policy
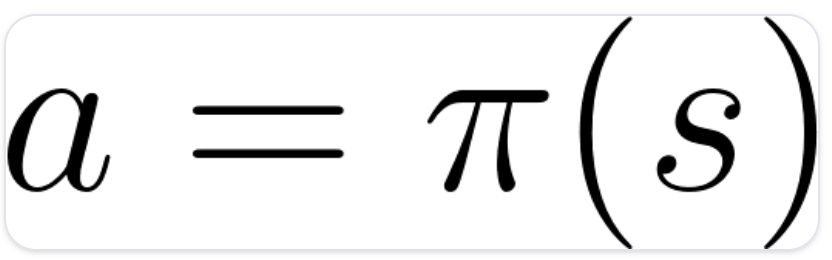
- stochastic policy: 행동들에 대한 확률분포를 결과로 리턴하는 policy

-
Value-based

- 에이전트로 하여금 어떤 상태가 더 가치있는지 학습하고 더 가치있는 상태로 이끄는 행동을 취하도록 학습 (value function을 학습함으로써 간접적으로 policy function 학습)
- 상태와 해당 상태가 됨으로써 기대되는 값(가치; value) 사이의 mapping을 학습
- 상태의 값은 해당 상태에서 시작해 policy에 따라 행동한다면 에이전트가 얻을 수 있는 expected discounted return
- policy에 따라 행동한다 = 가장 높은 값을 가진 상태로 향한다

Deep Reinforcement Learning
- 강화학습 문제를 해결하기 위해 딥 뉴럴 네트워크를 사용하는 학습 방법
- 예를 들어, 기존의 Q-Learning에서는 Q table을 활용하여 어떤 행동을 취할 것인지 선택했다면 DRL에서는 뉴럴 네트워크를 사용

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab