Reinforcement Learning from Human Feedback (RLHF)
등장 배경
- loss의 한계
- 단순하게 다음 토큰을 예측하는 방식(예: cross entropy)으로 학습한 언어모델은 사람의 선호(예: 창의성, 진실성, 코드의 실행가능성)을 제대로 반영하지 못함
- metric의 한계
- loss의 한계를 보완하기 위해 등장한 BLEU, ROUGE 등의 평가기준 또한 사람의 선호를 제대로 반영하기에는 역부족
정의
- 언어모델을 사람의 피드백을 활용해 직접적으로 최적화하기 위해 강화학습 방식을 이용
- 일반적인 텍스트 코퍼스 데이터를 복잡한 사람의 가치(선호)와 align시킬 수 있음
학습 단계
1. 언어모델 사전학습
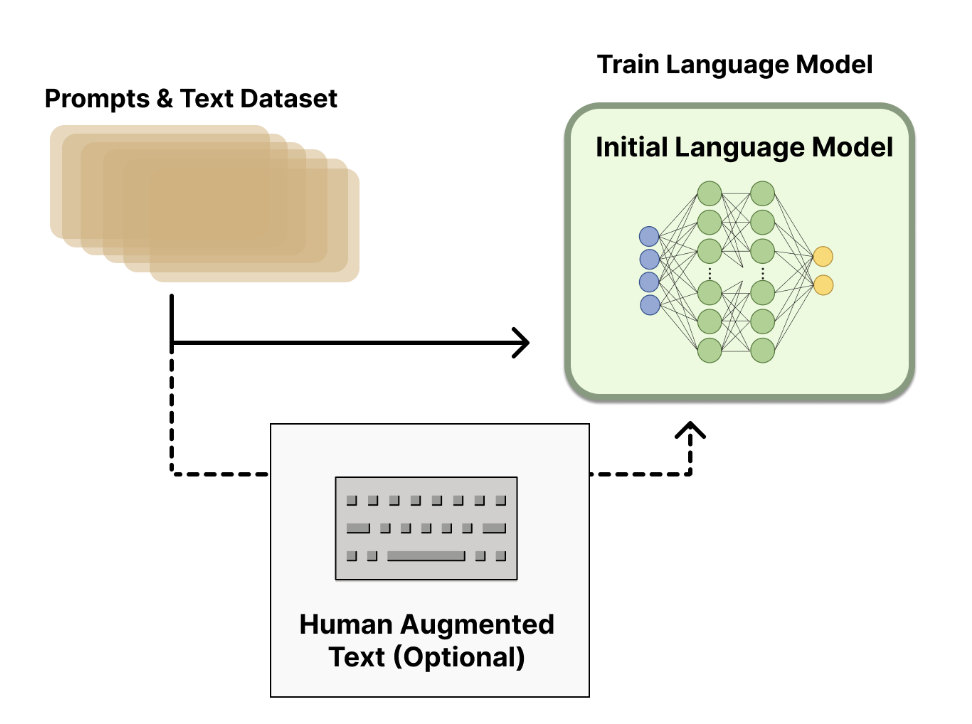
- 일반적으로 사전학습된 언어모델을 사용
- e.g. OpenAI는 InstructGPT를 학습할 때 GPT-3(사전학습 모델)의 작은 버전을 사용
- 여기서는 RM; reward model과의 구별을 위해 LM으로 지칭
- 사전학습된 모델(LM)은 추가적인 텍스트나 조건에 맞춰 파인튜닝될 수 있으나, 필수는 아님
- e.g. OpenAI는 사람이 생성한 데이터를 활용해 파인튜닝 진행
- e.g. Anthropic은 본래의 언어모델을 "helpful, honest, and harmless" 기준에 맞춰 distillation 수행
- 어떤 모델이 RLHF를 위한 최고의 시작점인지에 대한 확실한 정답은 없음
2. 데이터 수집 및 보상모델
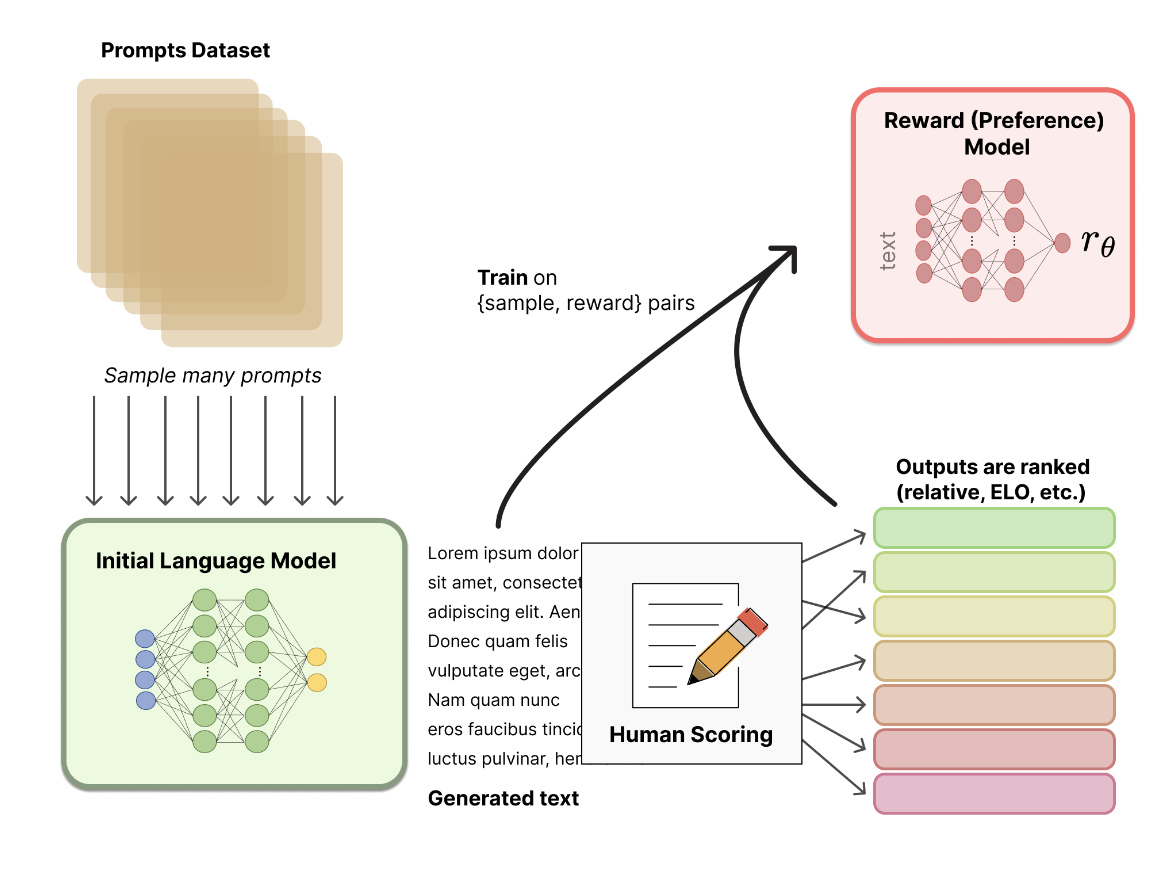
- 사람의 선호에 기반한 보상 모델(reward model, preference model; RM)을 생성하는 연구는 비교적 새로운 연구 분야
- 텍스트 시퀀스를 인풋으로 받아 사람의 선호를 나타낼 수 있는 scalar reward를 아웃풋으로 내는 모델을 만들고자 함
- 새로이 파인튜닝된 언어모델 혹은 처음부터 새로 학습한 언어모델 이용
- RM 학습을 위한 프롬프트-생성(prompt-generation) pair로 구성된 데이터셋
- 기존에 존재하는 데이터셋에서 프롬프트를 샘플링해 초기의 언어모델(LM)로 하여금 새로운 텍스트를 생성하도록
- LM이 생성한 텍스트는 사람(human annotator)이 직접 순위를 매김
- scalar score로 ranking을 매기면 사람마다 기준이 다르기 때문에 noise 발생 가능
3. 강화학습을 활용해 언어모델 파인튜닝
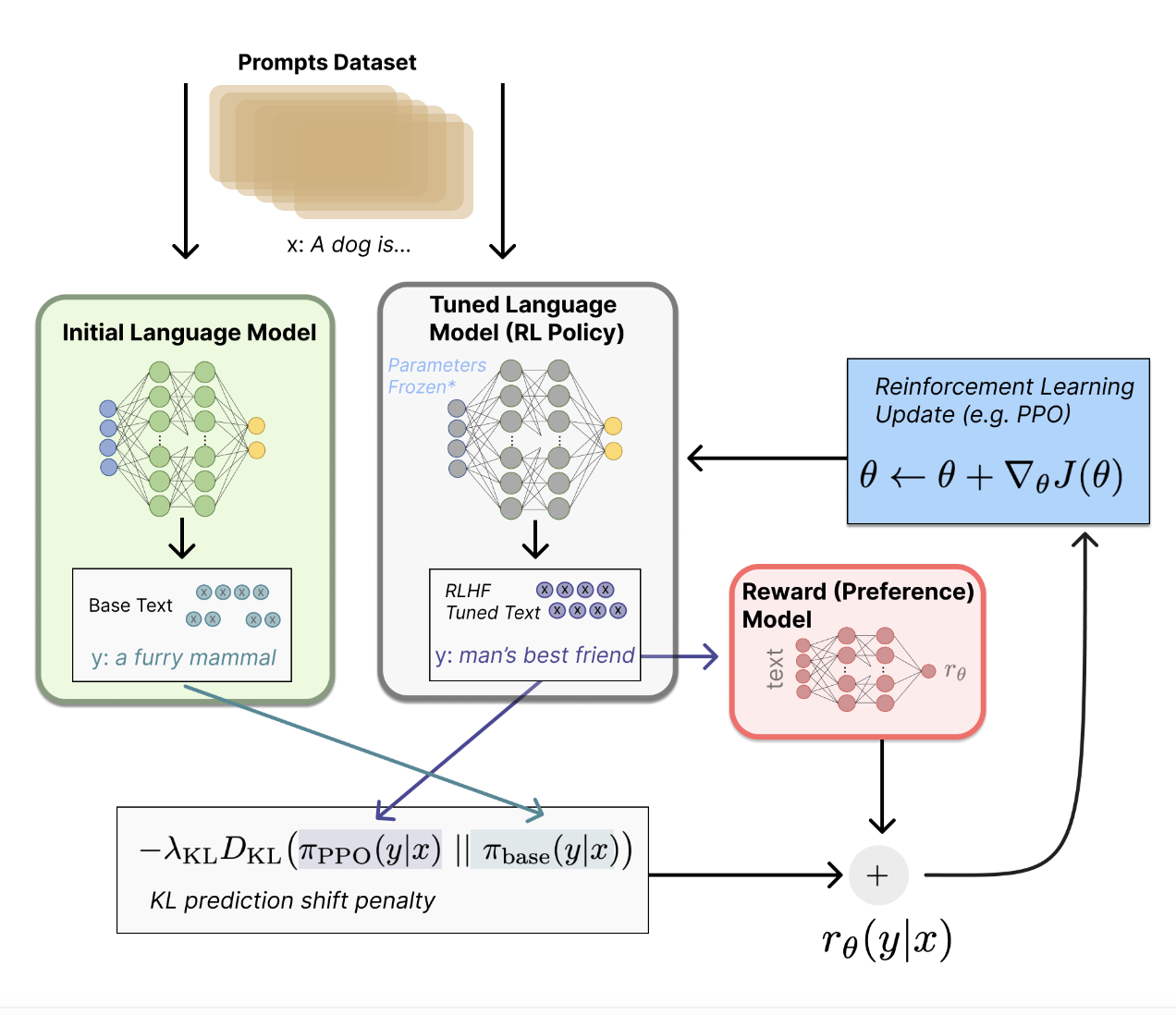
- 초기 언어모델(LM)의 복제본의 전체 혹은 일부 파라미터를 Poximal Policy Optimization (PPO)라는 policy-gradient RL 알고리즘을 활용해 파인튜닝
- 파인튜닝 태스크를 강화학습 문제로 formulate
- policy = 언어모델 (input = prompt, ouptut = sequence of text)
- 초기의 언어모델(LM)이 파인튜닝되는데, 이러한 fine-tuned LM = policy로 이해 가능
- action space = 언어모델의 단어사전에 해당하는 모든 토큰 (보통 50K)
- observation space = 가능한 input token sequence (vocab size^# input tokens)
- reward function = preference model + policy shift에 대한 제약
- policy = 언어모델 (input = prompt, ouptut = sequence of text)
- 세부설명 (상단 그림 참고)
- 프롬프트 x가 주어졌을 때 텍스트 y1, y2 생성 (하나는 LM에서, 다른 하나는 현재 단계의 fine-tuned policy에서)
- fine-tuned policy에서 생성된 텍스트는 preference model의 input으로 사용되어 preferability를 나타내는 r을 리턴
- y1, y2 사이의 차이를 계산하고 penalty를 부여
- 대부분 Kullback-Leibler (KL) Divergence를 사용해 RL policy가 기존의 사전학습 언어모델의 분포와 너무 달라지는 것을 방지
- 현재 배치의 데이터에서 reward metric을 최대화하는 PPO 알고리즘을 활용해 파라미터 업데이트
- PPO는 on-policy인데, 이는 현재 배치의 prompt-generation 쌍에 대해서만 파라미터를 업데이트함을 의미)
- PPO는 gradient에 대한 제약을 활용하는 trust region optimization (PPO에 대해서는 별도 글에서 정리할 예정)
- 참고로, OpenAI의 경우 reward function에 사전학습 gradient를 추가하여 더 좋은 성능을 보임
- reward function은 진화할 가능성 높음
참고 링크
- This article is mainly based on Illustrating Reinforcement Learning from Human Feedback (RLHF) from HuggingFace.
- If you are more interested, you might enjoy reading Learning from Human Preferences from OpenAI

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab