참고 링크: https://huggingface.co/learn/deep-rl-course/unit3/introduction?fw=pt
Introduction
- 2강에서 소개한 Q-Learning은 state space가 분리되어 있고 작음
- 하지만 state space가 큰 경우 Q-table은 비효율적
- state space가 큰 경우 유용한 방법이 Deep Q-Learning
Q-Learning
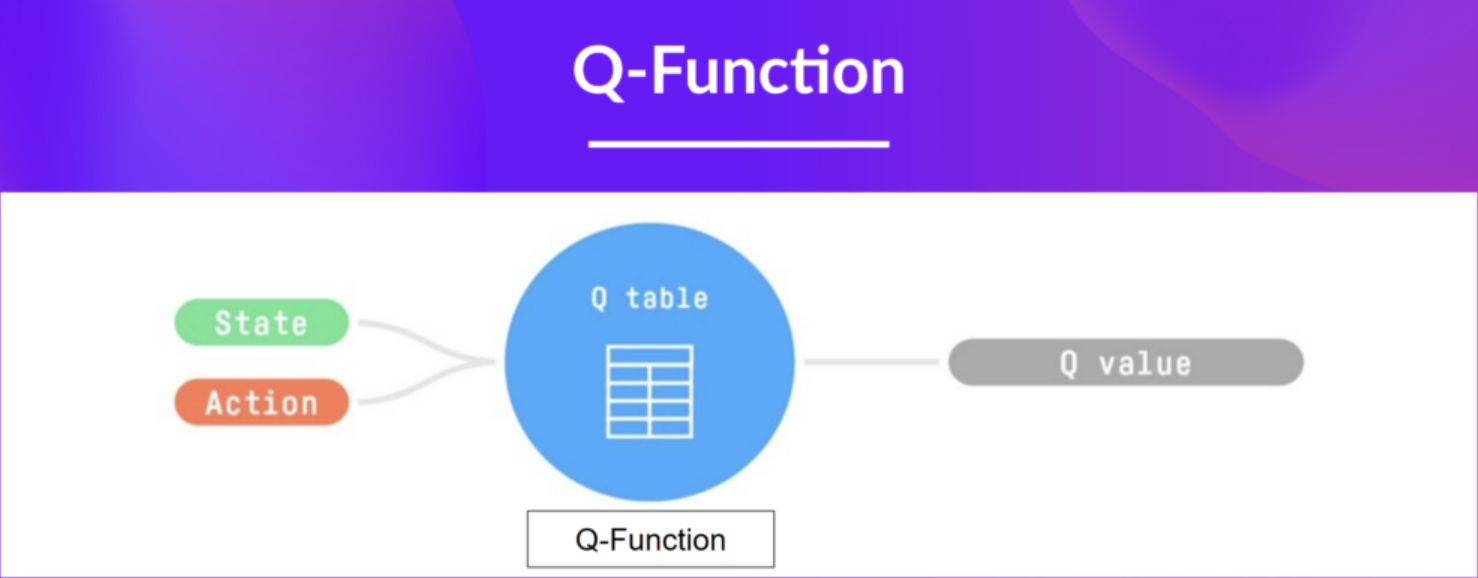
- Q-Function
- 특정 상태(state)에서 특정 행동(action)을 취했을 때의 value를 결정하는 action-value 함수
- Q-Learning은 Q-Function을 학습하기 위해 사용하는 알고리즘
- 내부적으로 Q-Function은 Q-table로 인코딩됨
- Q-table
- 각 셀이 state-action pair에 해당하는 표(table)
- Q-function의 메모리 혹은 치트시트
- 확장이 어려움
- 예를 들어 Atari의 경우, 256^100800 observation이 필요
Deep Q-Network

- Deep Q-Learning은 Q-table 대신 인공신경망을 사용
- 아타리 게임의 경우, 인풋으로 4개 프레임 층을 state로 넘겨주며, 각 state에서 가능한 action에 대한 Q-value의 벡터를 아웃풋으로 돌려줌
- Q-Learning과 마찬가지로 어떠한 action을 취할지를 결정할 때 epsilon-greedy policy 사용
input preprocessing
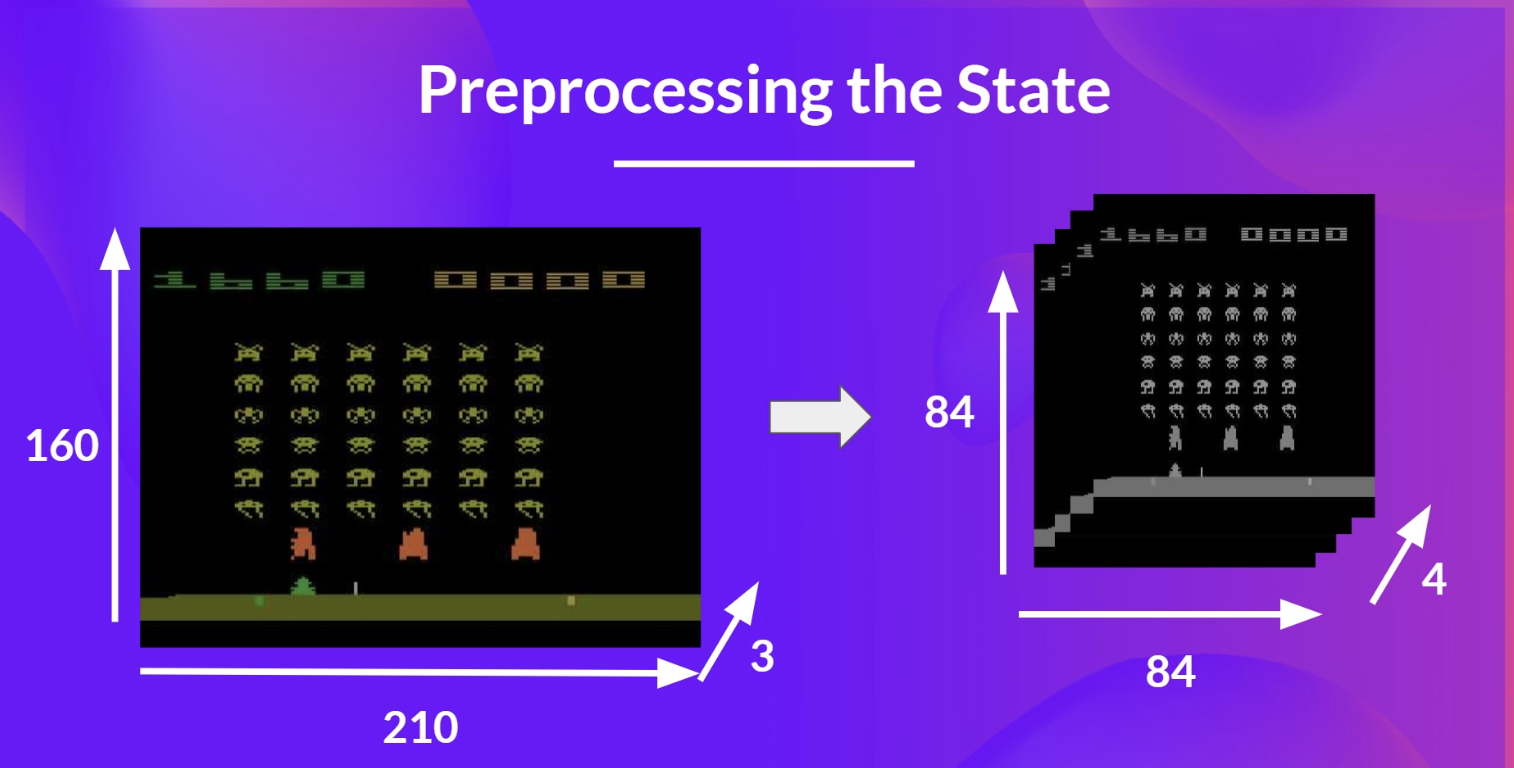
- state의 복잡성을 줄이고 학습시 연산량을 줄이기 위해 input을 전처리
- state space의 크기를 줄이고 색을 없앰
- RGB로 구성될 경우 일반적으로 3개의 channel이 존재하나, 흑백처리를 함으로써 channel이 1개로 줆
- 210 X 210 X 3차원의 input이 84 X 84 X 4차원으로 변화 가능
- 마지막에 4차원(= 4개의 프레임 스택)이 필요한 이유는 시간적 제약(=temporal limitation)을 극복하기 위함임
- temporal limitation
- 방향성, 움직임을 표현하기에 1개의 프레임은 부족하기 때문에 여러 개의 프레임을 중첩(stack)해 시간의 흐름을 표현
Deep Q-Learning Algorithm
- 각 state에서 가능한 action에 대해 각기 다른 Q-value를 인공신경망을 활용하여 근사
- Q-Learning
- state-action pair의 Q-value를 직접 업데이트
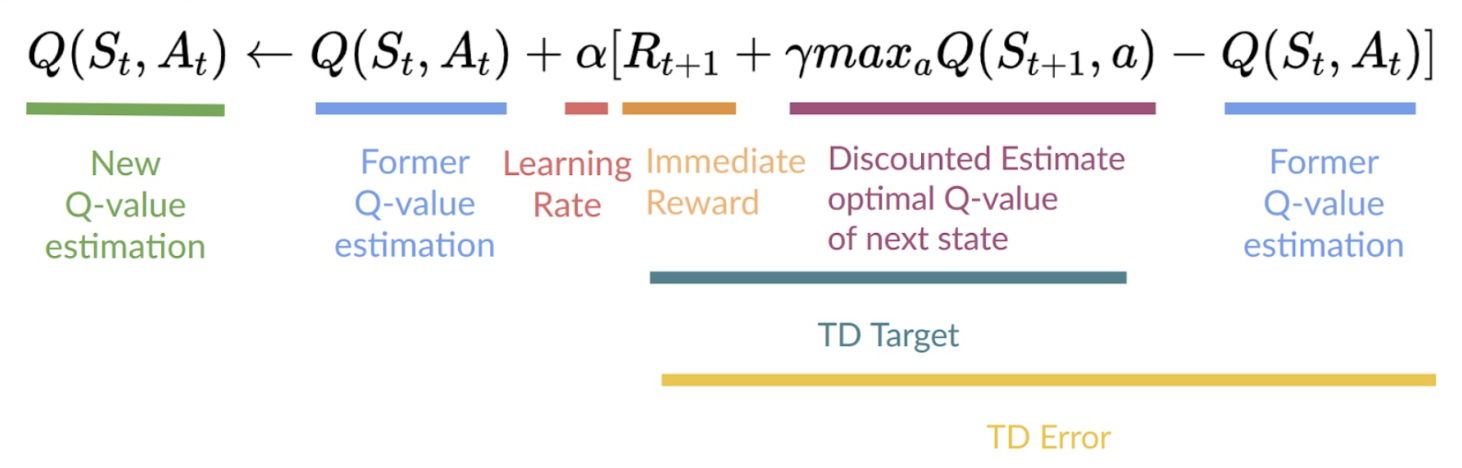
- state-action pair의 Q-value를 직접 업데이트
- Deep Q-Learning
- Q-value 예측값과 Q-target을 비교할 수 있는 loss function 생성
- Q-value를 더 잘 근사화할 수 있는 Deep Q-Network의 weight을 업데이트
- Gradient descent 활용

- Gradient descent 활용
training algorithm (2단계)

- 샘플링
- action을 수행하고 replay memory에 저장된 관측된 경험값(튜플)을 저장
- 학습
- 랜덤하게 작은 크기의 배치(튜플)를 선택하고 gradient descent를 통해 학습
학습 안정화 (stabilization)를 위한 방안들 (3가지)

experience replay
- 학습 시 경험(experience)을 효율적으로 사용할 수 있음
- replay buffer를 활용하여 학습동안 experience sample을 재사용할 수 있도록 함
- 동일한 experience으로부터 여러 번 학습 가능
- 이전 경험을 잊지 않도록 함
- 새로운 경험을 학습함에 따라 이전 경험을 잊을 수 있는데, experience replay를 통해 바로 직전뿐만이 아니라 더 예전에 이루어진 경험들로부터 학습이 가능케 함
- 경험들 사이의 상관관계를 줄임
- 랜덤하게 샘플링함으로써, observation sequence 사이의 상관관계를 줄이고 action value가 oscillate하거나 diverge할 가능성을 줄임
fixed q-target
- TD error (= loss)를 줄이고자 할 때, Q-target(= TD target)과 현재 Q-value 사이의 차를 구해야 함
- 정확한 TD target을 알지 못하기 때문에 근사값을 구하는데, TD target과 Q-value가 동일한 파라미터(가중치)를 활용
- 학습이 진행됨에 따라 Q-value와 target value가 함께 움직임
- 이러한 문제를 해결하고자 TD target을 예측할 때 고정된 파라미터를 가진 별도의 네트워크(target network)를 활용
- 특정 스텝마다 deep q-network의 파라미터를 복사해 target network 업데이트
double deep q-learning
- Q-value의 과대평가(overestimation) 문제 해결
- 다음 state를 위한 최적의 action == 가장 높은 q-value를 가진 action?
- 이는 장담할 수가 없음 (false positive일 수도 있음)
- Q-target을 계산할 때 action selection과 target q-value 생성을 분리(decouple)할 수 있도록 2개의 네트워크 사용
- DQN 네트워크로 가장 높은 Q-value를 가진 action을 선택
- Target 네트워크로 target q-value 계산

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab