참고 링크: https://huggingface.co/learn/deep-rl-course/unit5/introduction?fw=pt
Introduction
- 강화학습의 어려움 중 하나는 환경을 만드는 것
- 게임엔진을 이용해 강화학습을 위한 환경을 생성할 수 있음
- Unity, Godot, Unreal Engine
ML-Agent
Unity ML-Agent
- 게임 엔진 Unity를 위한 툴킷
- Unity를 사용한 환경을 만들거나 이미 만들어진 환경을 사용할 수 있음
- 6개의 구성요소를 가짐
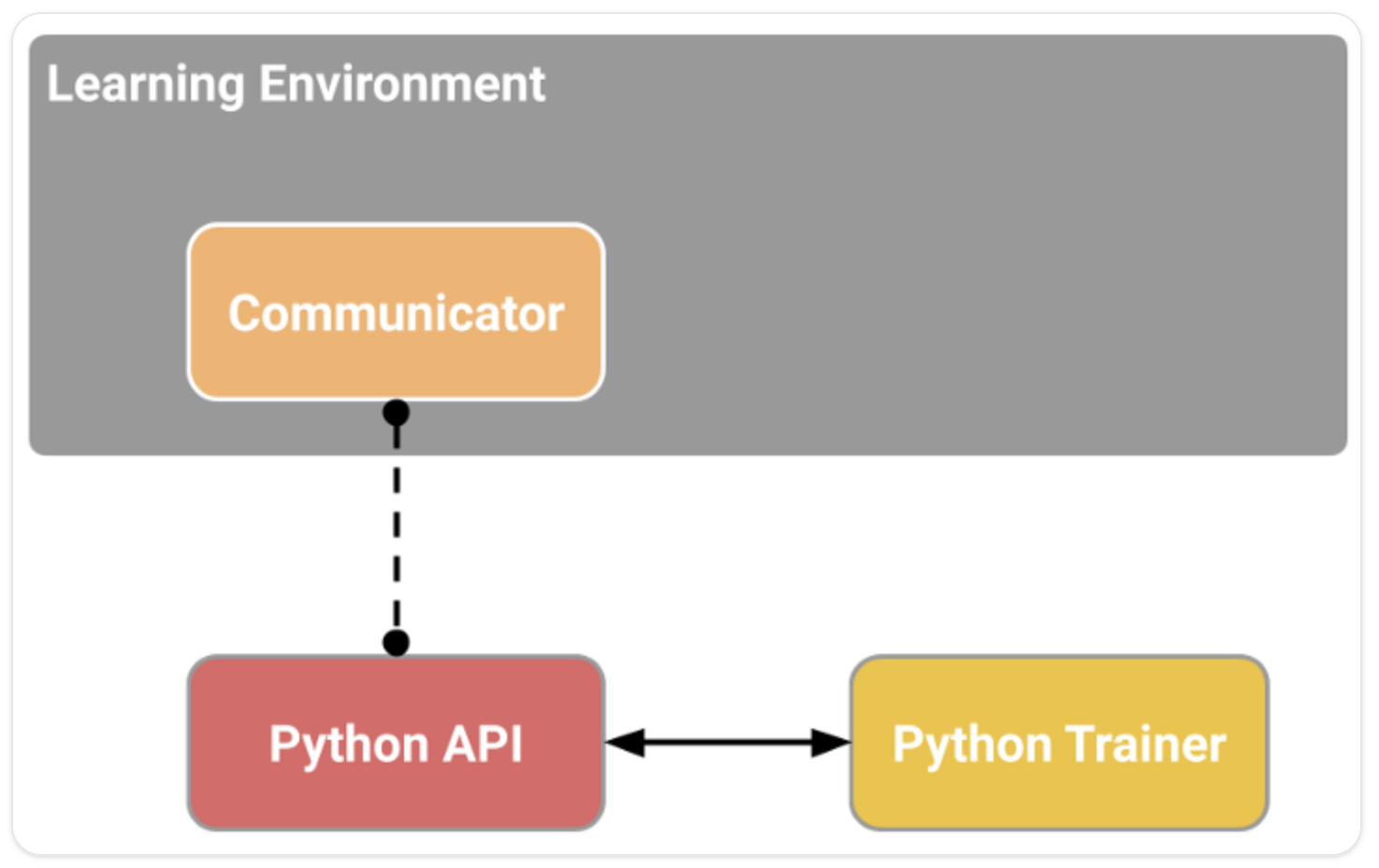
- 학습환경 (Learning Environment)
- Unity scene(환경)과 환경요소(게임 캐릭터)를 포함
- 파이썬 low-level API
- 환경과 상호작용하고 환경을 이용하기 위한 low-level 파이썬 인터페이스
- 학습을 시작하기 위해 사용하는 API
- 외부 통신자 (External Communicator)
- 학습환경과 Python API를 연결
- 파이썬 학습자 (Python trainer)
- 파이토치로 만들어진 Reinforcement(강화) 알고리즘 (PPO, SAC, ...)
- Gym wrapper
- 강화학습 환경을 gym wrapper로 캡슐화
- PettingZoo wrapper
- gym wrapper의 multi-agent 버전
- 학습환경 (Learning Environment)
학습 요소 (Learning Compoenent)
- agent component
- 환경의 행위 주체
- 각 상태(state)에서 어떤 행동(action)을 취할 지 알려주는 policy를 최적화함으로써 agent를 학습
- policy = Brain
- Academy
- agent와 의사결정 과정을 조직하는 요소
- 파이썬 API 요청을 처리하는 선생님같은 역할
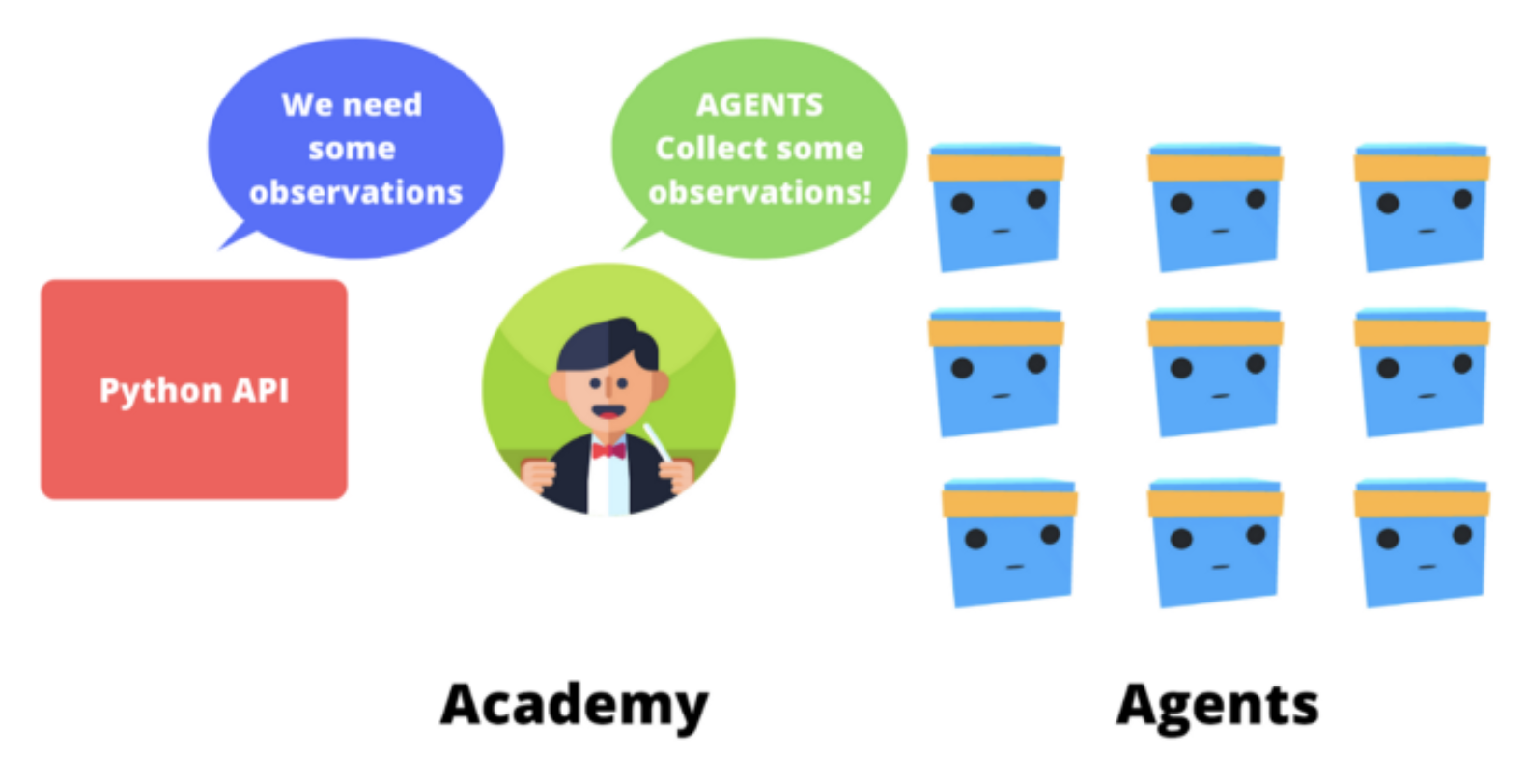
- 강화학습 루프는 일련의 state, action, reward, next state를 결과로 리턴
- agent의 목표는 누적 리워드의 기댓값을 최대화하는 것
- Academy는 agent에 순서를 보내고 agent들이 동기화되도록 보장
- 관찰(observation)을 수집
- policy를 활용해 action 선택
- action 선택
- 최대 스텝에 도달하거나 완료되었을 때 reset
예시 1. SnowballTarget Environment
- 제한된 시간 내에 눈으로 정해진 타겟을 최대한 많이 맞춰야 함
- reward
- 타겟을 눈으로 맞출 때마다 +1.0
- reward engineering problem
- 너무 복잡한 리워드 함수는 오히려 독이 될 수 있음
- 단순한 리워드 함수를 이용할 때 agent가 흥미로운 전략을 선택할 수도 있음
- observation space
- raycast를 활용
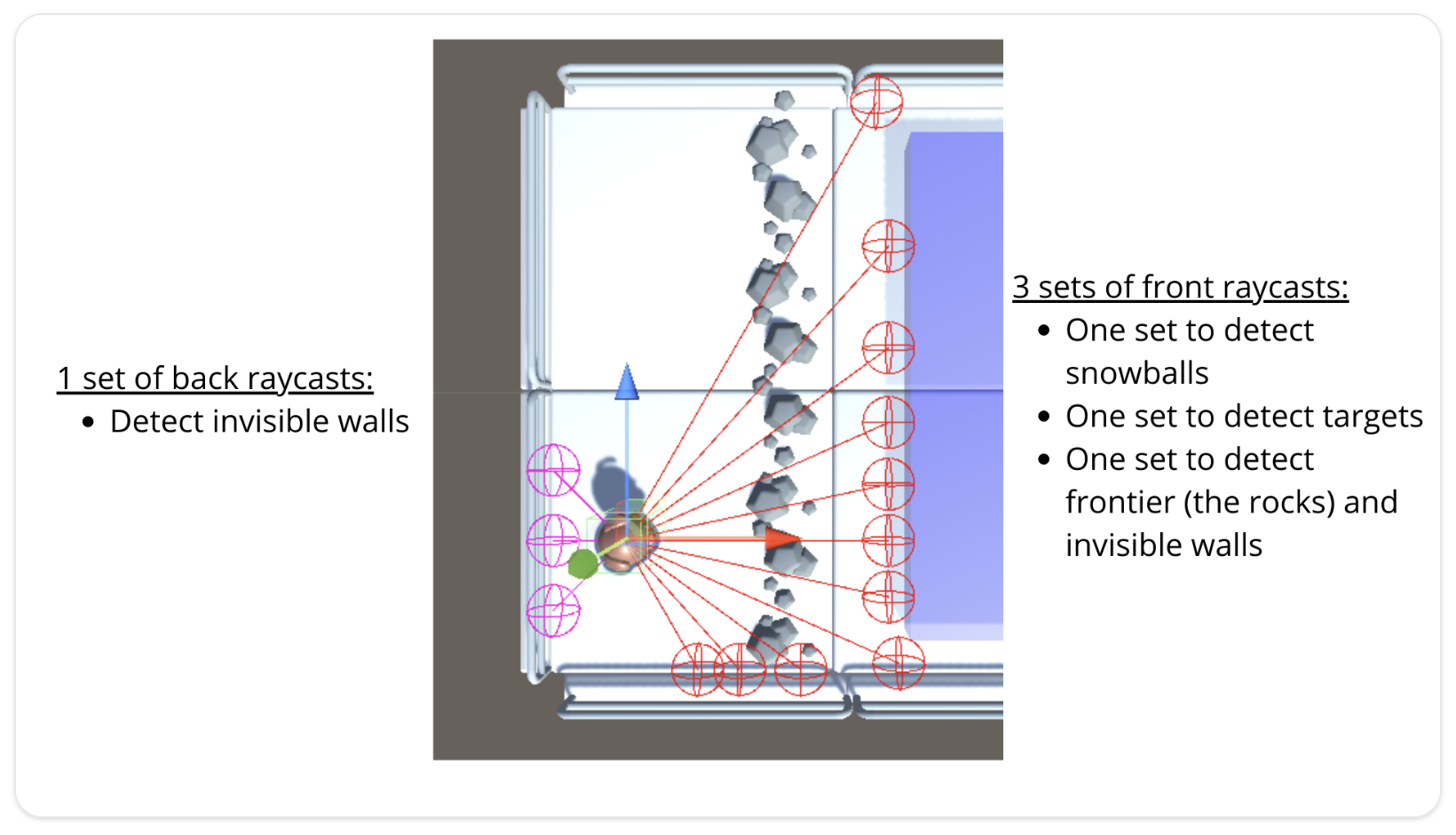
- 물체를 통과할 수 있는지 여부를 감지할 수 있는 일종의 레이저
- 눈을 던질 수 있을지 여부(boolean) 또한 observation으로 사용
- raycast를 활용
- action space (discrete)
- 앞으로 이동 (앞뒤)
- 옆으로 이동 (좌우)
- 눈을 던짐
예시 2. Pyramid Environment
- 피라미드를 만들기 위해 버튼을 누르고, 피라미드를 찾아가고, 이를 넘어뜨리고, 맨 위에 있던 금색 벽돌로 이동하는 문제
- reward
- extrinsic (외적 보상)
- 매 스텝마다 -0.001 (agent가 더 빠르게 움직이도록)
- 금색 벽돌로 이동하면 +2
- intrinsic (내적 보상)
- = curiosity
- 환경을 더 잘 탐색할 수 있도록 해주는 보상
- extrinsic (외적 보상)
- observation space
- 148개의 raycast 사용
- 버튼, 벽, 벽돌, 금색 벽돌 등을 감지 가능
- 버튼의 상태(버튼이 눌렸는지 아닌지; boolean)와 agent의 속도(vector) 또한 observation으로 제공
- 148개의 raycast 사용
- action space (discrete)
- 앞으로 이동 (앞뒤)
- 회전 (왼쪽, 오른쪽)
Curiosity
강화학습의 문제
- sparse reward problem
- 대부분의 보상이 정보를 담고있지 않아 0으로 세팅됨
- 보상은 강화학습 에이전트에게 일종의 피드백으로 작용하는데, 아무런 피드백도 받지 못한다면 어떠한 행동을 취하는 것이 좋은지에 대한 지식을 학습할 수 없음
- handmade extrinsic reward function
- 외적 보상함수를 사람이 환경에 따라 직접 만들어줘야 함
- 크고 복잡한 환경에서 적용하기 어려움
curiosity
- intrinsic reward mechanism (내적인 보상 메커니즘)
- 에이전트가 스스로 생성한 보상함수
- 에이전트는 피드백을 주는 주체임과 동시에 이를 배우는 학생처럼 행동 (self-learner)
- 새로운 것들을 발견하고 환경을 탐색하려는 사람의 내적인 욕구를 모방
- 현재 상태와 취해질 행동이 주어지면, 다음 상태를 예측할 때 생기는 오류를 이용해 curiosity를 계산 (고전적인 방식 중 하나)

- 행동의 결과를 예측하는 agent의 능력의 불확실성을 줄이는 방향으로 학습하고자 (=결과 예측의 불확실성을 줄이는 행동을 수행하도록 만들고자) 함
- agent가 많은 시간을 쓰지 않았거나, 복잡한 환경일수록 불확실성이 높음
- 다음 상태를 잘 예측한다면 low curiosity
- 탐구하지 않은 새로운 상태일수록 다음 상태 예측이 어려움 = high curiosity
- curiosity를 활용하면 결과적으로 환경을 더욱 잘 탐색할 수 있음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab