참고 링크: https://huggingface.co/learn/deep-rl-course/unit6/introduction?fw=pt
Recap: Reinforce
- Policy-Based method
- value function 없이 policy를 직접적으로 최적화하는 방법
- Policy-Gradient method
- policy-based 방식 중 하나
- gradient ascent를 사용해 최적의 policy weight을 측정함으로써 policy를 최적화
Reinforce

- Reinforce는 리턴이 얼마나 높은가에 대해 비례적으로(proportionally) trajectory의 action의 확률을 증가
- return을 계산할 때 Monte-Carlo 샘플링을 사용 (R(tau))
- return이 높으면 (state, action) 조합의 확률을 높임
- policy gradient estimation은 return의 증가가 가장 가파른 방향으로 진행
- return이 낮으면 (state, action) 조합의 확률을 낮춤
- return이 높으면 (state, action) 조합의 확률을 높임
- trajectory를 수집해서 discounted return을 계산하고, 취해진 모든 행동의 확률을 높이거나 줄이는 데에 사용
- 만약 return이 좋으면, 모든 행동들이 "강화됨(reinforced)"
Unbiased
- return을 추정하는 것이 아니라 실제로 우리가 얻은 return을 사용하기 때문에 unbaised
Variance Problem
- 환경과 policy에 stochasticity(확률성) 존재
- trajectory가 다른 return을 만들 수 있기 때문에 높은 variance 존재
- 동일한 state에서 시작했다고 하더라도 에피소드마다 다른 return을 가질 수 있음
- 이를 완화하기 위해서는 많은 샘플(많은 trajectory)을 필요로 함
- 샘플 효율성을 저하시킬 수 있음
- 학습 시간이 오래 걸림
Actor-Critic
- value-based 방식과 policy-based 방식을 결합한 방법
- actor: 에이전트가 어떻게 행동하는가를 통제 (policy function)
- critic: 취해진 행동이 얼마나 좋은지를 측정 (value function)
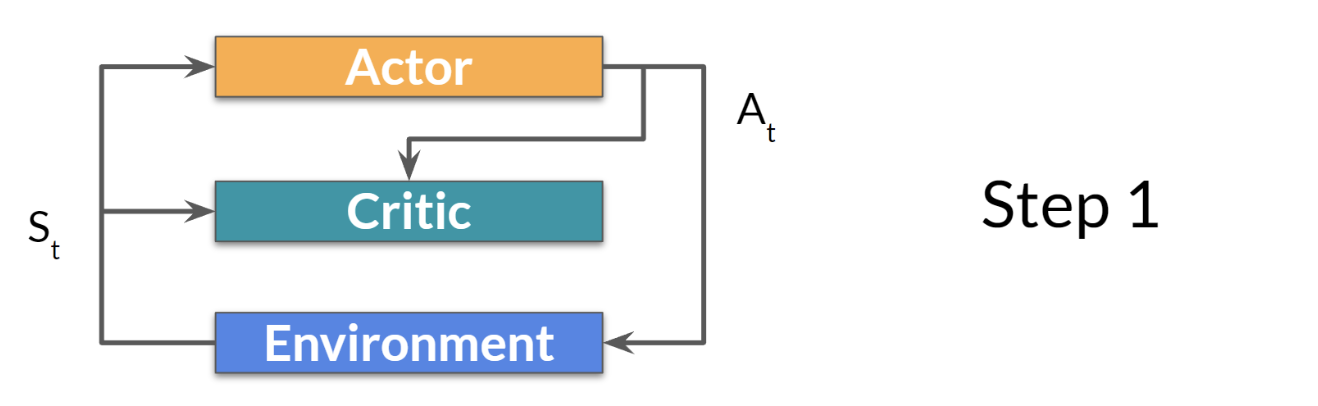
step 1. 현재 state를 actor와 critic에 전달, policy가 action을 결과로 냄
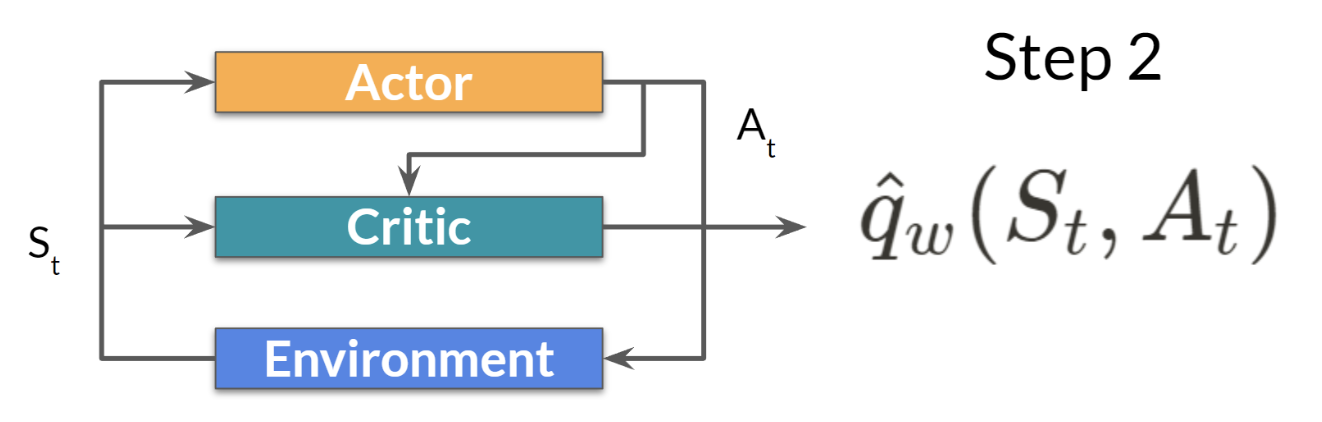
step 2. critic이 action을 input으로 받아 해당 state에서 특정 action을 취할 때의 값을 계산 (Q-value)
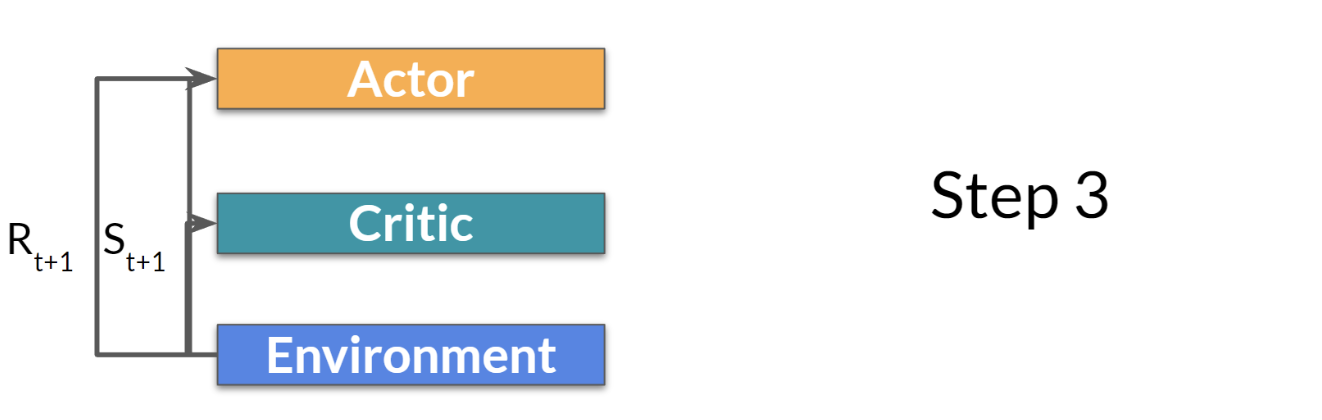
step 3. action을 통해 새로운 state와 reward 계산
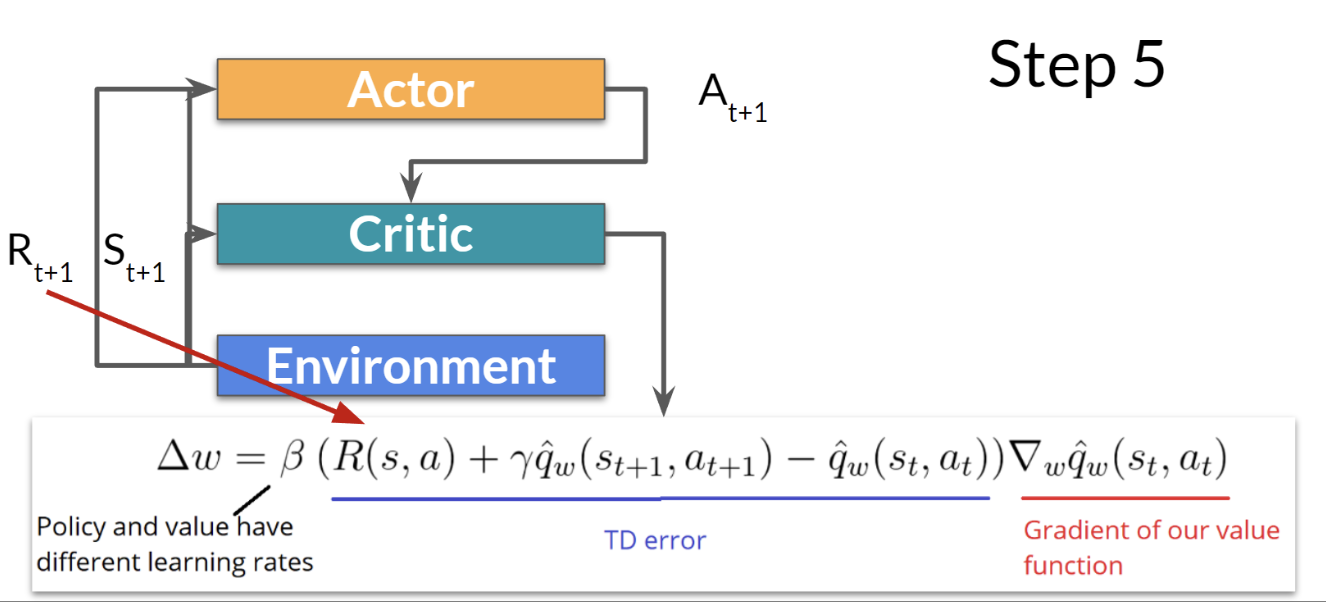
step 4. actor가 q-value를 활용하여 policy 파라미터를 업데이트

step 5. 업데이트된 파라미터를 가진 actor가 새로운 state가 주어졌을 때 다음 action을 생성, critic이 value 파라미터를 업데이트
Advantage Function
- action value function 대신 advantage function을 critic으로 사용함으로써 학습을 더욱 안정화할 수 있음
- Advantage Function

- 해당 state에서 특정 action을 취하는 것이 다른 평균값 대비 얼마나 더 좋은지 상대적인 장점을 계산
- 다시 말해, 해당 state에서 얻을 수 있는 평균 reward 대비 특정 action을 취했을 때 얻을 수 있는 추가적인 reward를 계산하는 함수
- A(s, a) > 0 이라면 gradient가 해당 방향으로 진행됨
- A(s, a) < 0 이라면 gradient가 반대 방향으로 진행됨
- Q(s, a) = r + lambda V(s')로 바꿔 쓸 수 있기 때문에, TD error의 형태로 표현 가능


Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab