강의 링크: https://huggingface.co/learn/deep-rl-course/unit7/introduction?fw=pt
Multi-Agents Reinforcement Learning (MARL)
- Agent
- 환경을 관찰하고 관찰을 기반으로 어떻게 행동할지를 결정할 수 있는 자율적인 개체(entity)
- Single-Agent System
- 다른 에이전트들과 협력하거나 합동하지 않는 시스템
- 환경 내에 에이전트가 단독으로 존재
- Multi-Agent System
- 다른 사람 혹은 다른 에이전트들과 상호작용하는 시스템
- 공통의 환경을 공유
- e.g. 패키지를 적재, 하차하고 길을 찾는 창고의 화물로봇들, 도로 위의 자율주행차들
- Multi-Agent Environments
- Cooperative environments (협력적 환경)
- 공통의 이익을 극대화시키고자 함
- e.g. 창고 내의 로봇들은 효율적으로 패키지를 적재, 하차하도록 협력해야 함
- Competitive/Adversarial environments (경쟁적 환경)
- 상대의 이익을 최소화하고 자신의 이익을 최대화하고자 함
- e.g. 테니스 게임
- Mixed of both adversarial and cooperative (경쟁적 + 협력적 환경)
- e.g. 2 vs. 2 축구 게임
- Cooperative environments (협력적 환경)
Design Multi-Agent System
연관 동영상: https://youtu.be/qgb0gyrpiGk
- Multi-Agent System을 디자인하는 방법
- 사용자가 에이전트의 행동을 직접 인코딩(지정)
- e.g. 자율주행의 경우 빨간불에 멈추고, 최소한의 거리를 유지하고, 선 안에서 주행하도록 지정
- 에이전트가 행동을 배우도록 지시
- e.g. 자율주행의 경우 에이전트가 위와 같은 행동을 배우도록 함
- 이를 학습하기 위한 방법으로는 adaptive control, genetic algorithm, 강화학습 등이 존재
- 강화학습이란, 최적의 결과를 만드는 일련의 행동을 찾는 방법 (최적 = 가장 많은 리워드)
- 사용자가 에이전트의 행동을 직접 인코딩(지정)
Decentralized System
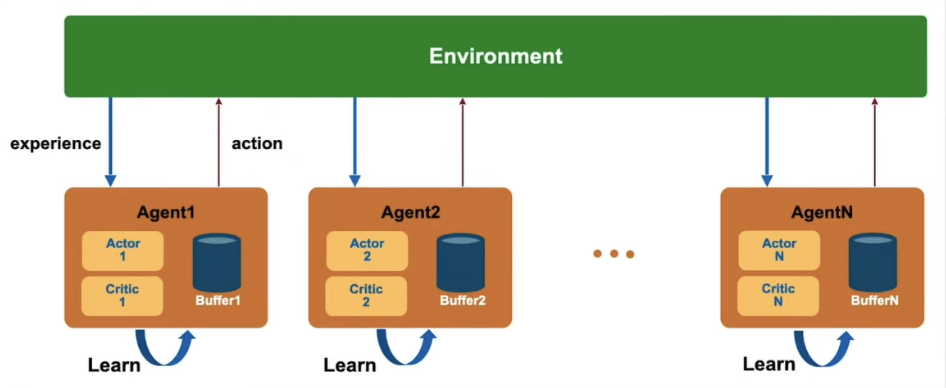
- 각 에이전트들이 서로와 독립적으로 학습 (정보가 공유되지 않음)
- 다른 에이전트들을 변화하는 환경의 일부라고 여기며 학습
- 장점
- 단일 에이전트를 학습하는 것처럼 학습이 가능 (시스템 디자인이 단순)
- 단점
- 다른 에이전트들의 상태를 알 수 없음
- non-stationary environment
- 다른 에이전트들 또한 환경과 상호작용하기 때문에 시간이 지남에 따라 Markov decision process가 변화
- 강화학습의 경우 non-stationary environment에서는 수렴하지 못하는 문제가 발생할 수 있음 (=global optimum을 찾기 어려움)
Centralized System

- 에이전트들의 경험을 수집하는 고차원의 절차가 존재 (공통의 experience buffer)
- 수집한 경험들을 활용하여 공통의 policy를 학습
- 장점
- 전체의 에이전트들이 거대한 하나의 개체처럼 취급되고 서로의 policy 변화를 알 수 있기 때문에 stationary environment를 유지할 수 있음
Self-Play
- 경쟁적, 협력적 환경이 모두 요구되는 2대2 축구게임과 같은 경우에 사용
- 에이전트와 비슷한 수준의 상대방을 설정하고, 에이전트가 업그레이드되면 상대방의 수준 또한 업그레이드하는 방식
- 상대방이 너무 약하거나 너무 강하면 에이전트가 제대로 학습할 수 없음
- 이를 위해 에이전트는 스스로(=policy)의 이전 복사본을 상대방으로 설정해 학습
- 에이전트의 복사본을 상대방으로 설정함으로써 학습 시작 (상대방은 유사한 수준을 갖게 됨)
- 학습 후 학습한 policy의 가장 최신 복사본으로 상대방을 업데이트
Self-Play in MLAgents
- 스킬 수준, 마지막 policy의 보편성(generality), 학습의 안정성 사이에 trade-off 존재
- 천천히 변화하는 다양성이 적은 적수(상대방)를 상정하고 학습하는 것은 안정적인 학습에 기여하나, 오버피팅의 가능성 존재
- 효과적인 Self-Play를 위해 통제해야 할 사항들
- swap_steps and team_change: 얼마나 자주 상대방을 변화시킬 것인가
- window: 저장할 상대방의 수 (더 많이 저장할수록 상대방 행동의 다양성이 증가)
- play_against_latest_model_ratio: 현재 상대방과 겨룰 확률
- save_steps: 새로운 상대방을 저장하기 전 학습 스텝 수 (상대방이 더 많은 학습을 진행하기 때문에 더 많은 스킬을 학습할 가능성이 높아짐)
ELO Score
- Adversarial game에서 학습 진행의 지표로 누적 리워드를 사용하는 것이 언제나 유리한 것은 아님
- 누적 리워드는 오직 상대방의 스킬에 의존적인 지표이기 때문
- ELO rating system
- 제로섬 게임에서 두 플레이어 사이의 상대적인 스킬 수준을 측정하는 시스템
- 제로섬 게임에서는 각기 다른 참가자의 utility의 gain 혹은 loss가 균형을 유지 (=utility의 총합이 0이 됨)
- ELO에서는 플레이어에 대한 점수를 계산할 때 상대방의 점수, 상대방에 대해 얻은 결과를 활용
- 다시 말해, 상대방의 퍼포먼스에 따라 상대적으로 결정됨
- 예를 들어, 플레이어가 이겼으나 이길 확률이 높았던 경우, 상대방으로부터 적은 포인트만을 가져올 수 있는데 이는 상대방보다 원래 강했기 때문임
- 반대로, 낮게 평가된(lower-rated) 플레이어가 이겼다면 높게 평가된 플레이어(higher-rated)로부터 많은 포인트를 가져오게 됨
- 무승부일 경우 낮게 평가된 플레이어가 높게 평가된 플레이어로부터 약간의 점수만을 가져옴
- 제로섬 게임에서 두 플레이어 사이의 상대적인 스킬 수준을 측정하는 시스템
ELO Score Calcuation
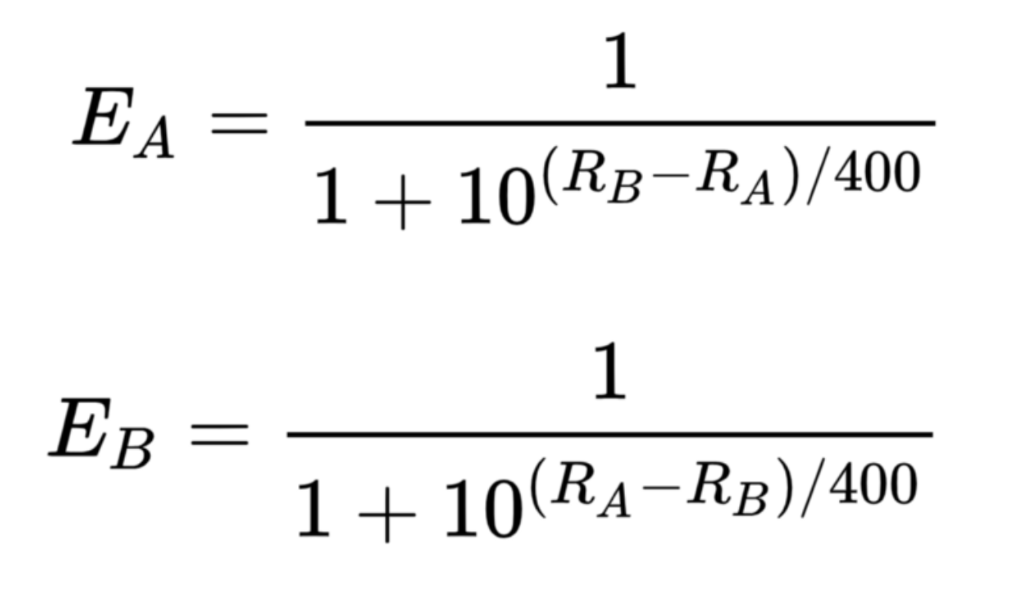
- A와 B가 점수 Ra, Rb를 가질 때 기대 점수 (Ea, Eb)
- 게임이 끝난 이후 플레이어가 예상보다 더 잘 수행했는지 혹은 아닌지 정도에 따라 비례적으로 실제 ELO 점수를 업데이트
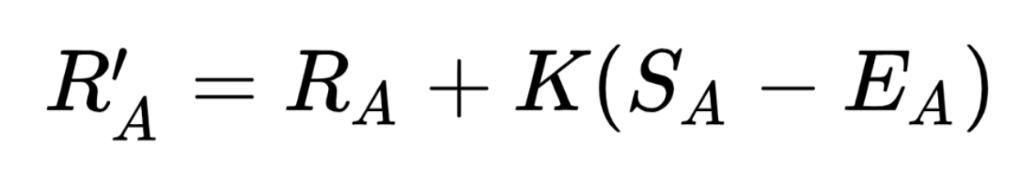
- 기대 점수가 Ea이고 실제 얻은 점수가 Sa일 때, 플레이어의 평가가 위의 공식을 활용하여 바뀜
- e.g. 만약 이긴다면 Sa = 1, 진다면 Sa = 0으로 계산 가능
- K-factor는 게임마다 최대 몇 번의 조정(adjustment)을 수행할 것인가를 의미
- master에 대해선 K=16
- 더 약한 플레이어에 대해서는 K=32
ELO 점수의 장단점
- 장점
- 점수가 언제나 균형을 이룸
- 예상하지 못한 결과가 나왔을 때 더 많은 점수가 교환되나, 전체 점수의 합은 언제나 동일
- self-corrected system
- 팀 게임에도 적용 가능한 방식
- 팀의 평균을 활용해 ELO 계산
- 점수가 언제나 균형을 이룸
- 단점
- 팀 내 개개인의 기여도에 대해서는 고려하지 않음
- 좋은 평가를 받는다면, 동일한 평가를 유지하기 위해서는 시간이 지남에 따라 스킬을 더 많이 필요로 함 (rating deflation)
- 과거의 평가를 비교할 수 없음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher at LG CNS AI Lab