논문 링크: HyperCLOVA X 8B Omni
요약
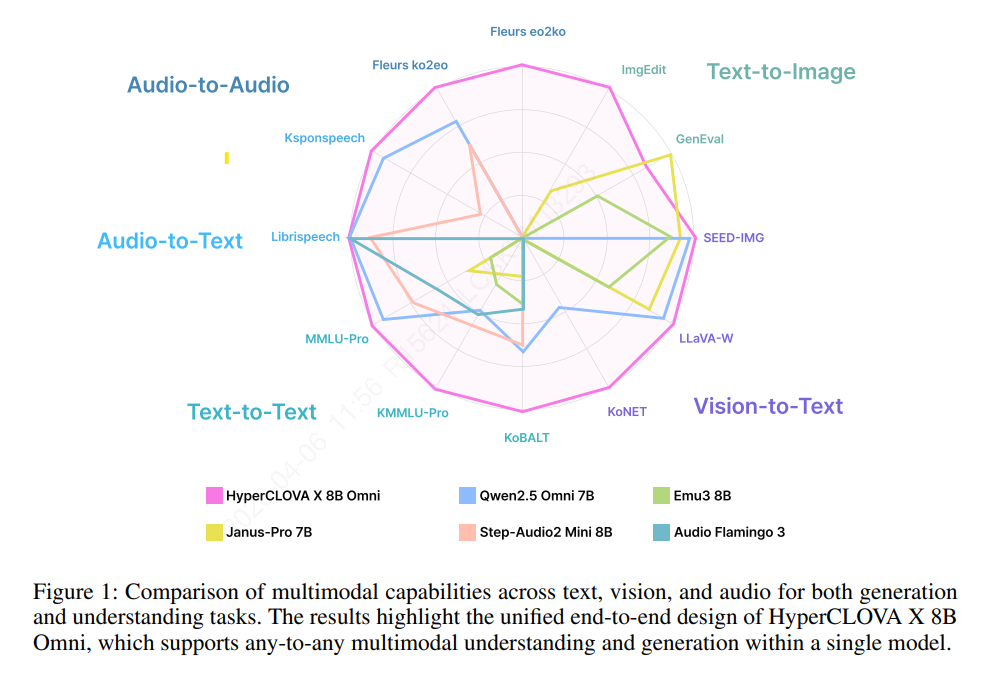
- 텍스트, 오디오, 이미지를 인풋과 아웃풋으로 사용할 수 있는 Omni 모델
- 결합된 멀티모달 시퀀스가 다음 토큰 예측 인터페이스를 공유하는 방식으로 모달리티 통합
- 비전 인코더와 오디오 인코더가 연속적인 임베딩을 주입
- 기존 LLM에 인코더와 디코더를 연속적으로(sequential) 통합하는 방식과 다르게, 멀티모달 토큰과 임베딩을 결합하여 함께(joint) 학습
- 연속적 통합의 경우 비용 및 시간 효율적으로 LLM을 멀티모달로 전환 가능하나, 학습한 지식의 catastrophic forgetting을 야기할 수 있음
모델
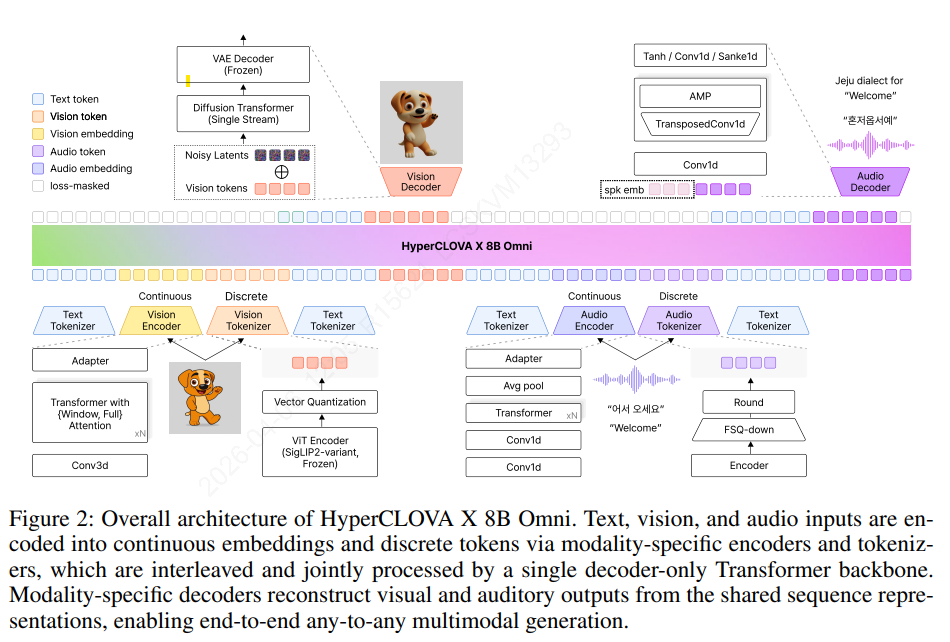
모델 설계 및 방향 탐색
- 모달리티 특화 토큰과 임베딩이 공통의 다음 토큰 예측 인터페이스를 공유
- 이를 통해 모달리티 간 의미론적 구성(semantic composition)이 가능하도록 함
- 텍스트 토큰, 비전 토큰과 비전 임베딩, 오디오 토큰과 오디오 임베딩이 결합되어 함께(jointly) 처리됨
- THINK와 유사하게 텍스트 토큰화 적용 (해당 논문 정리 참고)
- 형태 유지를 위한 pretokenizer와 subword tokenizer 적용
- 토큰 효율성을 유지하면서도 토큰 경계 편향을 완화하기 위한 StoChasTok 적용
- 영어 중심 토크나이저를 3단계에 거쳐 단어사전 수정, 한국어 토큰 효율성 향상
- 각 모달리티 토크나이저의 토큰을 기존 LLM 기반 단어사전에 추가되는 항목으로 취급, 공유된 멀티모달 토큰 공간으로 확장
- 기존 임베딩 공간에 프로젝션되는 연속적인 임베딩을 만들어내는 모달리티 인코더 추가 적용
비전 모달리티
- 3가지 컴포넌트로 구성
- 연속적 비전 인코더 (지각적 이해)
- 개별적(discrete) 의미론적(semantic) 토크나이저 (생성 표현; representation)
- 디퓨전 기반 디코더 (픽셀 합성)
- 연속적 비전 인코더가 LLM에 바로 얼라인될 수 있도록 dense feature를 추출
- 시각적 생성을 지원하기 위해 visual feature를 개별적인 토큰으로 양자화(quantize)하는 비전 토크나이저 통합
- 텍스트 임베딩과 모달 간 시너지를 극대화하기 위해 의미(semantic) 단위로 토큰을 쪼갬
- 디퓨전 기반 디코더를 통해 토큰들을 픽셀로 디코딩해 비전 생성
인코더
- Qwen2.5-VL의 Vision Transformer 구조 적용
- 통합된 이미지 및 비디오 모델링 가능
- 연산 효율성을 높이기 위해 비주얼 토큰 할당 최적화, 이미지 및 비디오 압축 등 진행
- 한국어 특화 시각적 문맥, 문화 랜드마크, 고밀도 OCR 등 한국어 중심 멀티모달 역량을 내재화하기 위해 학습됨 (unfrozen)
토크나이저
- 사전학습된 텍스트-얼라인 토크나이저 TA-Tok 재사용
- 학습 시 frozen되어 사용됨 (추가 학습 X)
- 인풋 해상도가 384X384로 고정된다는 한계 있으나, 큰 성능 저하로 이어지지는 않음을 확인
- 정사각형 이미지가 아닐 경우 사이즈가 재조정되어 기하학적 왜곡 발생
디코더
- TA-Tok 모델과 함께 나온 디코더와 유사하나, 크게 두 가지 차이가 존재
- 어텐션 기반보다 빠른 수렴이 가능한 channel-concatenation-based 아키텍처 활용
- 원본 비율에 가깝게 처리
- 디퓨전 트랜스포머 구조 적용 (MMDiT의 단일 스트림 블록으로 구성)
- 텍스트에 의존하지 않고 비주얼 토큰만을 사용
오디오 모달리티
- 연속적 오디오 인코더, 개별적(discrete) 오디오 토크나이저, 뉴럴 오디오 디코더로 구성
- 연속적인 음성 임베딩과 개별적인 오디오 토큰은 별도의 인풋 스트림으로 언어모델에 제공됨
인코더
- Whisper-large-v3 모델로 초기화된 사전학습된 오디오 인코더 사용
- 25Hz라는 효과적인 프레임 비율로 연속적인 오디오 임베딩 생성
- 해당 오디오 임베딩은 언어 모델의 임베딩 차원으로 매핑됨
- 비디오 시퀀스에서 효율적으로 음성을 처리하기 위해, 단일 레이어 MambaMia 모듈 통합
- 추가적인 토큰 압축 메커니즘 적용으로 25Hz에서 1Hz까지 오디오 표현(representation) 다운샘플 가능
토크나이저
- 사전학습된 오디오 토크나이저 사용
- 연속적인 오디오 임베딩을 통해 세밀한 음성 정보 및 풍부한 운율(prosodic) 정보를 유지하고, 개별적인 오디오 토큰을 통해 압축적이고 생성 친화적인 표현(representation) 제공 가능
- 생성 친화적이란, autoregressive 모델링 및 파형 합성에 잘 맞는다는 의미임
디코더
- 개별 오디오 토큰으로부터 시간 도메인 파형을 재구축하기 위해, Unit-BigVGAN이라는 오디오 디코더 제안
- BigVGAN-v2의 아키텍처를 차용했으나, LLM이 생성한 개별 토큰을 사용할 수 있도록 개선됨
- ECAPA-TDNN을 활용해 고정된 차원의 발화자 임베딩을 추출
- 해당 임베딩은 토큰과 함께 사용되어 생성기(generator)에 인풋으로 들어감
- BigVGAN 형식의 업샘플링과 잔차 처리(residual processing) 활용
- 시간적 해상도를 높이고 최종 파형을 생성
학습
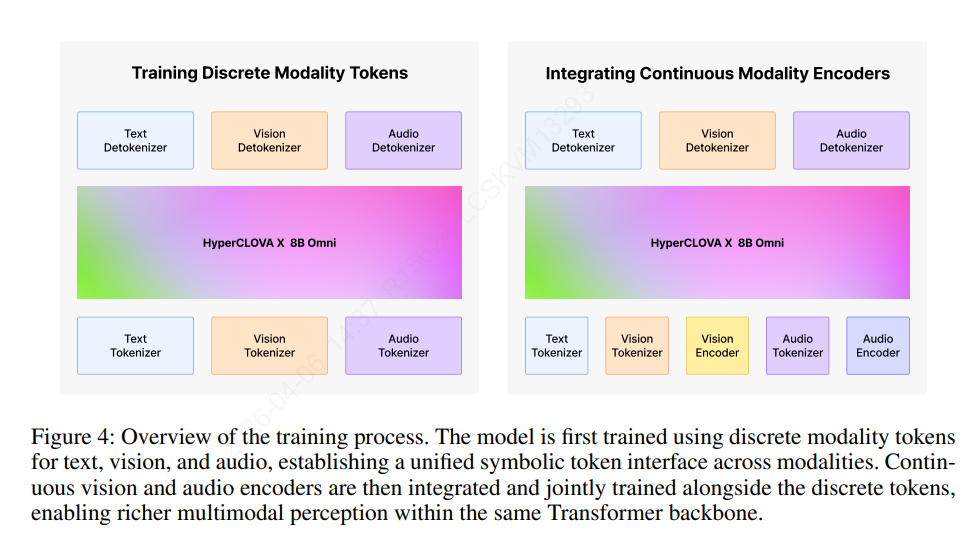
사전학습 (Pre-Training)
- 텍스트 중심의 기반 지식 학습과 멀티모달 역량의 점진적 주입이라는 두 단계로 진행
- 1) 텍스트, 비전, 오디오를 위한 개별적인 모달리티 토큰을 학습해 통합된 토큰 인터페이스 학습
- 2) 비전과 음성을 위한 연속적인 모달리티 인코더 통합되어 기존의 discrete representation과 함께(jointly) 최적화됨
텍스트 사전학습
- 데이터 준비 과정과 다단계 커리큘럼 학습 방식은 THINK와 유사(해당 논문 정리 참고)
- 추가적으로, 멀티 토큰 예측을 적용해 학습 효율성 개선
개별적(Discrete) 모달리티 토큰 학습
- 1단계: 멀티모달 단어사전 확장
- 모달리티 특화 토크나이저(비전, 오디오)에 의해 토큰 확장
- 텍스트 토큰에 해당하는 토큰 임베딩 부분은 학습에 미포함
- 새롭게 추가된 모달리티에 해당하는 임베딩만 학습 진행
- 2단계: 전체 파라미터 멀티모달 사전학습
- 모달리티 간 융합과 멀티모달 추론을 위해 전체 파라미터 대상 학습 진행
- 텍스트 성능의 저하를 막기 위해 모달리티의 비율과 loss masking이 신중하게 통제됨
- 3단계: 멀티모달을 위한 긴 문맥 적용
- 32K 컨텍스트 길이와 축소된 글로벌 배치 사이즈를 활용해 긴 시퀀스에 대한 안정성 개선
연속적 모달리티 인코더 통합
- 비전 인코더와 오디오 인코더 통합, 비전 인코더에 한해 최적화 진행
- 1단계: 비전 인코더 얼라인
- 비주얼 피처를 언어모델의 임베딩 공간에 얼라인
- 가벼운 선형 어댑터만 학습 (언어모델, 비전 인코더는 frozen)
- 이미지 캡션 쌍, 기본 OCR 태스크, VQA 예시 등을 학습 데이터로 사용
- 2단계: 비전 중심 전체 파라미터 사전학습
- 텍스트, 이미지 이해, 이미지 생성, 음성 등의 데이터 활용
- 이미지 이해의 경우 일반적인 시각 지식과 텍스트가 풍부한 OCR 데이터 함께 사용
- 이미지 생성의 경우 텍스트-이미지 데이터와 이미지 수정 데이터 함께 사용
- 3단계: 오디오 인코더 얼라인
- ASR 태스크를 활용해 가벼운 어댑터만 학습해 인코더와 모델 연결
사후학습 (Post-Training)
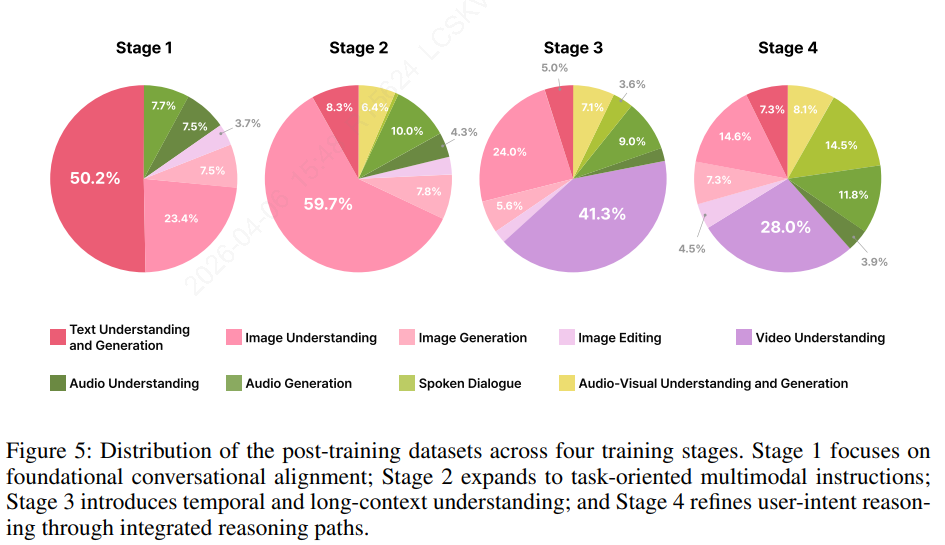
- 단계별 커리큘럼 학습 진행
- 기본적인 대화 유형 학습부터 복잡한 의도 인식 추론(reasoning)까지 학습
- SFT의 유효성을 중점적으로 탐구
데이터 구성 및 전략
- 고품질의 사람이 어노테이션한 대화와 합성 추론(reasoning) 트레이스를 활용
- 텍스트로부터 학습한 지식의 catastrophic forgetting을 방지하고자 함
- 비전과 오디오 모달리티의 경우 점진적으로 학습에서 비중을 높임
학습 방법
- 1단계: 기반 Omni 지식 학습
- 지시사항을 준수하는 역량을 학습
- 텍스트 기반의 SFT를 우선순위로 삼음 (전체 학습 분량의 50.2% 차지)
- 이미지 캡셔닝, ASR, TTS, 이미지 생성, 이미지 편집 등의 옴니모달 태스크 함께 학습
- 2단계: 태스크향 Omni 특화 학습
- 멀티모달 지시사항 학습
- 텍스트 데이터의 비중을 줄이고, 복잡한 이미지 이해를 위한 데이터 비중 증가
- 3단계: 긴 문맥 및 영상 SFT
- 긴 멀티모달 시퀀스에 대해 의미적 일관성을 유지하고, 시간에 따른 사건에 대해 추론(reasoning)을 수행하기 위함
- 4단계: 의도 인식 다단계 추론(reasoning)
- 고수준의 의도 파싱과 다단계 논리적 추론 역량을 학습하기 위한 단계
- 태스크 카테고리를 식별하고 필요한 모달리티 특화 모듈을 사용하기 위한 역량 주입
평가
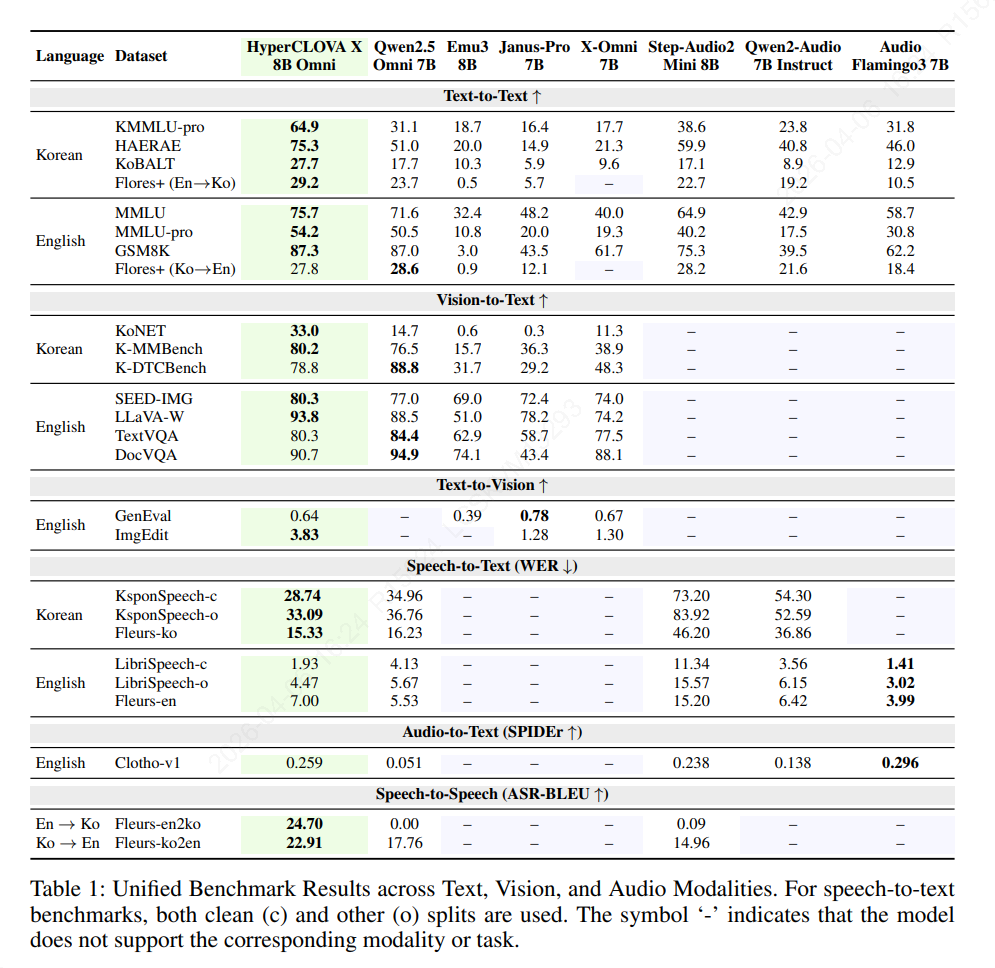
텍스트-텍스트 평가
- 한국어 벤치마크
- KMMLU-Pro, HAERAE-1.0, KoBALT에 대해 평가
- 평가 벤치마크에 대한 설명은 해당 논문 정리 참고
- 영어 벤치마크
- MMLU, MMLU-Pro, GSM8K에 대해 평가
- GSM8K는 수학 추론 벤치마크 (비교적 쉬운 난이도)
- 번역 벤치마크
- Flores+에 대해 평가 (1-shot, BLEU로 평가)
- MMLU, FLORES+에 대한 설명은 해당 논문 정리 참고
비전 및 텍스트 평가
비전-텍스트 벤치마크
- 한국어의 경우 KoNET, K-MMBench, K-DTCBench에 대해 평가
- 영어의 경우 SEED-IMG, LLaVA-W, TextVQA, DocVQA에 대해 평가
- 평가 벤치마크에 대한 설명은 해당 논문 정리 참고
텍스트-비전 벤치마크
- GenEval
- 일반적인 텍스트-이미지 생성 품질을 측정하는 평가 벤치마크 (총 553개 데이터)
- 생성된 이미지 내의 객체(object)를 감지하여 객체 동시발생, 위치, 수, 색 등의 구성 요소들을 평가
- Mask2Former 모델로 객체 인식 후 CLIP ViT-L/14로 색 분류, 이를 바탕으로 정확성(correctness)을 이진으로 평가
- ImgEdit
- 텍스트 제약조건 하에서 이미지를 수정하는 역량 평가
- 총 세 가지의 평가 범주 존재
- 지시사항 준수, 수정 품질, 세부사항 유지를 포함한 기본 수정 능력 평가
- 어려운 지시사항(e.g. 공간적 추론, 여러 객체 대상) 및 복잡한 풍경을 통해 복잡성을 높인 이해 기반 수정 평가
- 내용 이해/기억 및 버전 백트래킹을 평가하는 멀티턴 수정 평가
- ImgEdit-Judge(평가모델)로 평가 가능, 총 백만 건의 데이터
정성 평가
- 프롬프트의 언어를 바꿔도 유사한 이미지가 생성됨 (언어간 강건성, 일관성)
- 한국의 문화적 특성을 반영한 이미지 생성 가능
- 스타일 변경, 사물 제거, 배경 대체 등 이미지 수정 역량 뛰어남
비디오 벤치마크

- Video-MME
- 다양한 영상 유형, 시간 길이, 멀티모달 인풋(비디오 프레임, 자막, 오디오 등), 전문가 어노테이션을 특징으로 하는 벤치마크
- 900개 영상(254 시간)을 바탕으로 2,700건의 다지선다 평가 데이터 제작
- Naver TV Comprehension
- 네이버가 자체 구축한 비디오 벤치마크
오디오 및 텍스트 평가
스피치/오디오-텍스트 벤치마크
- KsponSpeech
- 60명의 한국어 발화자가 대화한 3000건의 대화 평가 (spontaneous)
- 일상, 쇼핑, 방송, 정치/경제, 날씨, 취미 등에 대한 대화 내용
- perplexity가 낮은 claen 버전과 perplexity가 높은 other 버전 존재
- LibriSpeech
- LibriVox의 오디오북 활용
- 발화자의 WER(word error rate)이 낮으면 clean, 높으면 other로 분류
- (clean) 40명의 대화자, 5.4시간
- (other) 33명의 대화자, 5.1시간
- Clotho-v1
- 15-30초 길이의 오디오 샘플에 대한 캡셔닝 평가 (총 4891건)
- Freesound 플랫폼 내 오디오 사용, Amazon Mechanical Turk 활용해 캡션 크라우드소싱
- Fleurs
- 번역 데이터를 기반으로 만든 다국어 스피치 벤치마크 (102개 언어)
- 위키피디아 기반 읽기, 총 1.4K 시간
- 한국어, 영어 대상 평가
스피치-스피치 벤치마크
- 위에서 설명한 Fleurs 대상 번역 평가 (한->영, 영->한)
텍스트-스피치 사람 평가
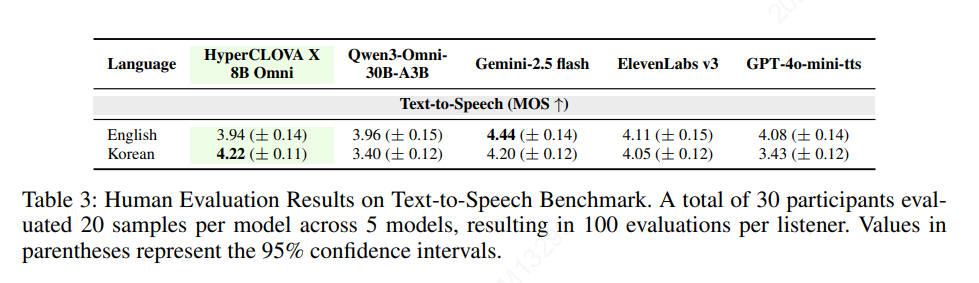
- 합성 스피치의 자연스러움을 중점으로 하여 Mean Opinion Score (MOS) 평가
- 30명의 사람 평가자가 참여
- 10개의 영어 문장과 10개의 한국어 문장 총 20개의 발화에 대해 평가

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab