요약
- 한국의 언어적, 문화적 문맥을 반영한 추론(reasoning) 및 에이전트 역량에 특화된 비전-언어모델
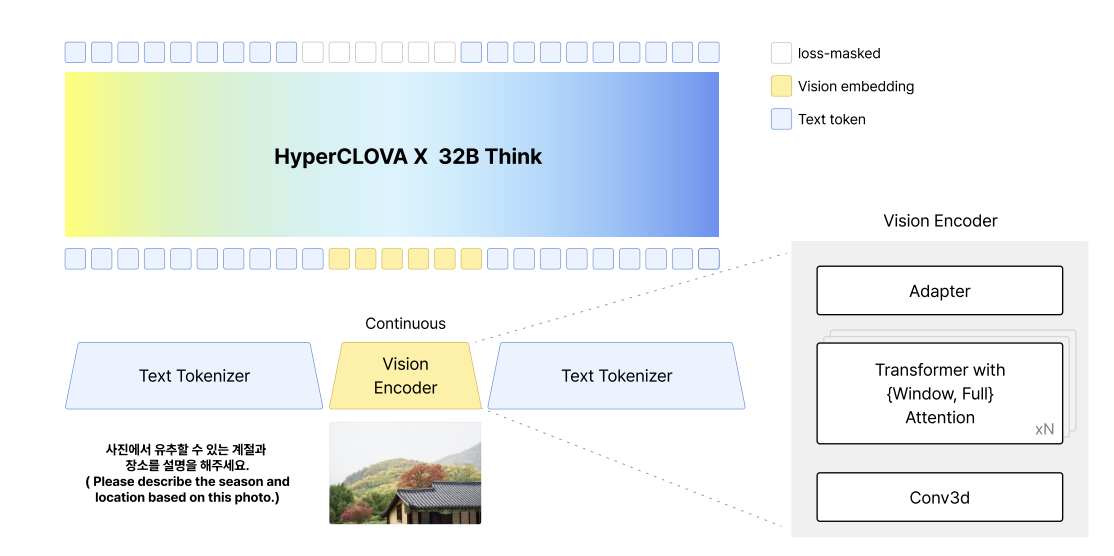
- 텍스트 토큰과 비전 패치가 동일한 연속적인 임베딩 공간으로 프로젝션되는 디코더 기반 트랜스포머
- 즉, 이미지와 텍스트가 같은 벡터로 번역된 뒤 하나의 통합된 어텐션 메커니즘을 통해 서로의 관계를 함께 학습하는 멀티모달 모델임
- 사전학습은 한국어 추론 역량을 중점으로 진행
- 사후학습은 SFT를 통해 멀티모달 역량을 학습한 뒤, RL을 통해 멀티모달 추론, 에이전트 역량, 사람 선호와의 얼라인을 학습
모델

구조
- 디코더 기반의 트랜스포머
- 학습 안정성과 추론 효율성을 위해 아래와 같은 컴포넌트들 선택
- pre-normalization: RMSNorm
- FFN의 활성화 함수: SwiGLU
- position encoding: RoPE (긴 문맥 학습)
- attention: grouped query attention (KV 캐시 효율성)
- 멀티모달 역량을 통합하기 위해, streamlined fusion strategy 사용
- 구조적 복잡성을 최소화하고 효율성을 개선시킬 수 있음
- visual representation을 트랜스포머 임베딩에 프로젝션 시키고, 텍스트 토큰 임베딩에 끼워넣어(interleave) 사용
텍스트 토큰화
pre-tokenizer 단계
- 다른 언어가 섞이는 것(merge)을 방지
- 토크나이저 압축 효율성과 다운스트림 태스크 성능에 영향을 미침
- 숫자에는 단일 숫자(single-digit) 토크나이제이션을 적용
- 코드와 수학 태스크에서의 성능 저하를 막을 수 있음
- 이로 인해 발생할 수 있는 토큰 경계 편향(token boundary bias)을 방지하고자 정규화(regularization) 기술인 StoChasTok 적용
subword tokenizer 단계
- tiktoken를 수정 적용하여 사용
- 제거(pruning) 단계
- 한국어 글자와 연관된 기존의 머지 규칙을 제거
- 사용성이 낮은 규칙들(e.g. 타겟이 아닌 언어들) 제거
- 대체(substitution) 단계
- 내부 코퍼스를 대상으로 학습된 subword tokenizer로부터 나온 새로운 머지 규칙을 삽입
비전 인코더
- Qwen2.5-VL의 비전 트랜스포머 아키텍처 적용
- local-window attention 메커니즘 적용
- 고화질 혹은 길이가 긴 인풋을 처리할 때 연산 효율성 유지 가능
- 비전 인코더 모듈 다음에 linear adapter를 활용하여, 비전 인코더 출력을 선형 변환하여 LLM에 넣음
- 비주얼 토큰의 효율성을 높이기 위해, 최대 해상도와 최대 프레임 수를 제한
- 한국 특화 멀티모달 역량을 학습 (parameter unfrozen)
학습
사전학습 (Pre-Training)
데이터 준비
- Datatrove와 NeMo-Curator를 통합한 파이프라인 설계
- 데이터 수집 및 정규화 (스키마 통일)
- 문서 기반 품질 점수 부여 및 PII 마스킹
- 단계별 특화 코퍼스 구축 (필터링)
- 샤딩된 파일로 문서 직렬화(serialization)
데이터 필터링
- 규칙 기반 필터링 1차 진행
- 모델 기반 품질 점수 2차 진행
- 한국어에 특화된 0-5점 기반의 품질 점수 모델 학습
- 고품질의 외부 코퍼스, 내부 확보 코퍼스, LLM 기반 어노테이션을 통해 수집된 저품질 문서 등 활용
- Qwen3-Embedding-0.6B 파인튜닝
- MinHash 기반 중복 문서 삭제
합성 데이터셋 생성
- 기존 문서 개선 및 품질을 높이기 위한 재작성
- 고품질 시드 데이터 기반 새로운 텍스트 생성
사전학습 커리큘럼
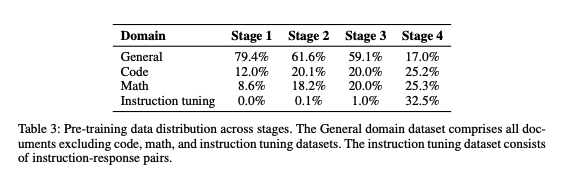
- 언어적, 사실적 지식 학습에서 시작해 긴 문맥과 추론(reasoning) 학습까지 진행
- 컨텍스트 윈도우와 고품질 데이터의 비중을 점진적으로 확대
- 추론(reasoning)을 위한 합성 데이터를 사전 학습 시 사용
- Fill in the Middle 적용 (약 10% 토큰)
- 빈 칸을 채우는 역량을 높이고 코드 생성과 긴 문맥 모델링 개선에 효과적
1단계: 기반 지식 구축
- 넓은 범위의 언어학적, 사실적 지식을 다국어로부터 학습 (주로 한국어, 영어)
- 6T 토큰 활용
2단계: 컨텍스트 확장 및 품질 업샘플링
- 컨텍스트 길이 4K에서 8K로 확장
- 고품질 SFT 데이터와 CoT 데이터가 사전학습 시 혼합되어 사용됨
- 지시사항 준수 역량을 구축하기 위함
3단계: 추론(reasoning) 및 긴 문맥 적용
- 컨텍스트 길이 32k로 확장
- 긴 문맥 모델링, 추론 역량 증강
- 일반적인 한국어, 영어 문서에 더 엄격한 필터링을 적용
- 추론향 합성 데이터의 비율을 늘림
4단계: 고품질 안정화(annealing)
- 고품질 추론 데이터셋을 기반으로 추론 역량 강화
사후 학습
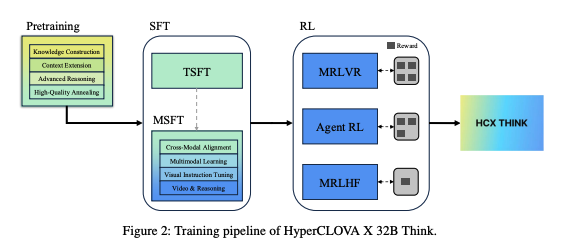
Supervised Fine-Tuning (SFT)
Text Supervised Fine-Tuning (TSFT)
- 3가지 종류의 학습 데이터 사용
- 일반적인 지시사항 준수를 위한 non-reasoning
- 다단계 추론을 위한 reasoning
- 일련의 의사결정과 도구 증강 상호작용을 위한 agent
- 각각의 학습 데이터는 각기 다른 필터링 파이프라인을 사용
- 고품질 데이터 확보를 위해 모든 테스트 케이스를 통과한 trajectory만을 활용
Multimodal Supervised Fine-Tuning (MSFT)
- cross-modal alignment
- 비주얼 피처를 텍스트 임베딩에 얼라인
- multimodal knowledge learning
- 비주얼 지식과 표현(representation) 역량 확대
- task-oriented instruction tuning
- 태스크향 멀티모달 상호작용 역량 향상
- advanced reasoning and video understanding
- 긴 문맥 멀티모달 추론과 시간적 역학 학습
- 텍스트 기반 추론 역량의 저하를 막기 위해, TSFT 데이터가 1단계를 제외하고 사용됨
Reinforcement Learning (RL)
Multimodal Reinforcement Learning with Verifiable Rewards (MRLVR)
- 다단계 학습 진행을 통해 각기 다른 역량 학습
- 일반적 추론 역량 향상 (integraded domain RLVR)
- 추론 길이 통제 (length-control RLVR)
- 목표 완수 확인 (multi-turn RLVR)
- 지시사항 준수 (instruction-following RLVR)
- 아웃풋 형식, 언어 일관성, 반복 등을 통제하기 위한 보조 보상(auxiliary reward) 활용
- 오프라인 데이터 필터링을 통해 너무 쉽거나 과하게 어려운 데이터 제외
- GRPO 활용 (+ dynamic sampling, adaptive clipping)
Reinforcement Learning for Agent (Agent-RL)
- 일반 에이전트와 SWE(Software Engineering) 에이전트를 별도 단계(phase)로 학습
- SWE 에이전트의 rollout이 일반적으로 더 길고 턴이 더 많음
- 보상은 다음 보상들의 가중합으로 계산됨
- 규칙 기반 verifiable reward와 LLM-as-a-judge 기반 자연어 reward
- 아웃풋 형식
- 인풋-아웃풋 언어 일관성
- GRPO 활용 (KL 페널티 제거, PPO clipping의 상한을 하한보다 높게 설정)
- 이밖에도 offline reward filtering, thinking mode fusion, adaptive rollout sampling parameter, self-correction via error feedback, service caching 등 적용
Multimodal Reinforcement Learning from Human Feedback (MRLHF)
- 사람 선호도와 얼라인하기 위한 학습 과정
- 보상 모델 학습
- PPO를 활용한 정책 모델 학습
- 아웃풋 형식과 언어를 통제하기 위한 보조 보상 사용
평가
- Omni-Evaluator를 활용해 평가
- 다양한 추론 엔진과 모달리티를 평가할 수 있는 통합된 평가 프레임워크
- 베이스라인 모델
- Qwen3-VL-32B-Thinking
- INternVL3_5 38B-Thinking
- EXAONE 4.0 32B
- GPT-5.1
- Qwen3 235B-A22B
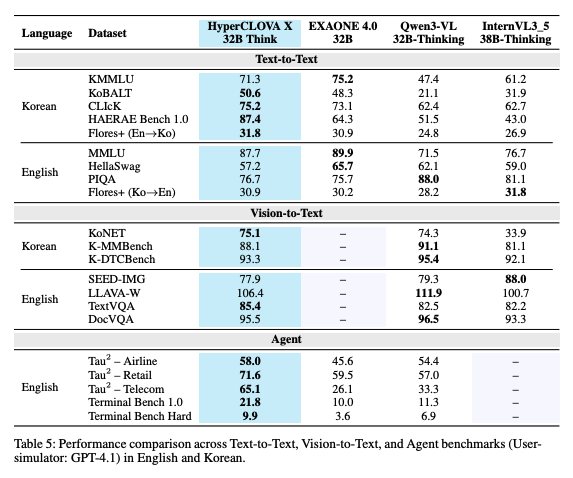
Text-to-Text 벤치마크
한국어 벤치마크
- 언어학 및 문법: KoBALT
- 문화 및 상식: CLIcK, HAE-RAE Bench
- 한국어 STEM 및 전문 지식: KMMLU
- 벤치마크에 대한 자세한 설명은 HyperCLOVA X THINK 논문 정리 참고
영어 벤치마크
- MMLU
- 인문학, 사회학, 과학 등 다양한 범주를 아우르는 지식을 측정
- 초등 수학, 미국 역사, 컴퓨터 공학, 법 등 57개 태스크
- 14,042개의 데이터로 이루어진 다지선다 문제
- HellaSwag
- 문맥을 기반으로 한 상식적 추론 능력 평가
- 문장을 제대로 완성할 수 있는지를 평가
- 10,003개의 데이터로 이루어진 다지선다 문제
- PIQA
- 물리적인 상식을 이해하고 있는지 여부 평가
- 2,000개(dev set) 혹은 3,000개(test set)로 이루어진 이지선다 문제
- 테스트 셋의 경우 label 없음
번역 벤치마크
- Flores+
- Wikinews, Wikijunior, Wikivoyage에서 샘플링한 영어 문장을 200개의 언어로 번역
- 언어별로 약 1,000개의 데이터 포함
- 1-shot 번역 성능 측정
- BLEU 평가지표 활용 (Ko-Mecab pre-tokenization 적용)
Vision-to-Text 벤치마크
한국어 벤치마크
- KoNET
- 한국의 국가 교육 표준에 기반한 시험들 포함
- 초등학교, 중학교, 고등학교, 대학 수능 등을 포괄
- K-MMBench
- 일반적인 이미지-언어 이해 능력을 평가
- 사물 인식, 속성 기반 추론(attribute reasoning), 상식 추론 등
- 약 4,300여 개 데이터로 구성된 다지선다 문제
- K-DTCBench
- 한국어로 된 문서, 표, 차트 기반의 시각적 추론 평가
- 컴퓨터로 생성 혹은 사람 손으로 작성한 경우 모두 포함
- 총 240개 데이터로 구성된 다지선다 문제
- KCSAT 2026 평가 시 확률 통계, 대수, 기하에서 모두 1등급 달성
- 64개의 독립적인 생성을 수행하고 다수결을 통해 최종 정답 결정 (consensus@64)
영어 벤치마크
- SEED-IMG
- SEED-BENCH-2는 결합된(interleaved) image-text 인풋과 각각의 image, text 아웃풋을 평가할 수 있는 벤치마크
- 24,000개의 다지선다 문제로 구성
- 27개 영역 평가 가능 (e.g. 다음 이미지 예측, 인컨텍스트 캡셔닝, 시각적 추론, 차이 인식 등)
- LLaVA-W
- LLaVA-Bench는 COCO와 In-the-Wild로 구성되어 있음
- 내부/외부 풍경, 밈, 그림, 스케치 등을 포함한 24개 이미지와 60개 질문으로 구성
- 각 이미지는 자세하게 작성된 설명이 포함되어 있음
- LLM-as-a-judge로 답변 평가
- TextVQA
- 이미지 내의 텍스트를 읽고 추론할 수 있는지 평가
- 45,336개로 구성, 사람 간 평가 다양성을 고려한 단어 기반 정확성 평가 (VQA accuracy)
- DocVQA
- 120,000개 이상의 문서 이미지로 구성된 50,000개 질문 데이터
- 단순히 텍스트를 읽는 능력이 아니라 문서의 레이아웃/구조 내에서 텍스트를 해석할 수 있는지 평가
- 평가지표로 ANLS (Average Normalized Levenshtein Similarity) 활용
비디오 벤치마크
- Video-MME
- 다양한 비디오 유형 및 시간 길이, 멀티모달 인풋 고려(비디오 프레임, 자막, 오디오 등), 전문가 어노테이션을 특징으로 하는 영상 기반 벤치마크
- 900개 영상(총 254시간) 바탕으로 2,700개 데이터 확보(다지선다)
- 63.4점 달성으로 GPT-4V(59.9)보다 좋은 성능을 보였음
- Qwen3-VL-32B-Thinking(77.3)보다는 낮은 성능
- NAVER TV Content Comprehension
- 내부 벤치마크
- 67.1점 달성으로 에서도 GPT-4V(50.0)보다 좋은 성능
에이전트 벤치마크
- Tau2 Bench
- 통신, 소매, 항공 도메인을 기반으로 멀티턴 상호작용을 통해 목표를 달성할 수 있는지 여부 평가
- 통신 도메인의 경우, LLM을 사용자로 가정 (user-simulator)
- 총 279개 태스크 (통신 114, 소매 115, 항공 50) 기반 평가
- 평가지표로는 pass^k(=k번 실행 시 k번 모두 성공하였는가) 사용
- 통신, 소매, 항공 도메인을 기반으로 멀티턴 상호작용을 통해 목표를 달성할 수 있는지 여부 평가
- Terminal Bench
- 도구향 추론 및 커맨드라인 환경 내 소프트웨어 엔지니어링 역량 측정
- 1.0의 경우 총 80개의 태스크로 구성

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab