Text and Code Embeddings by Contrastive Pre-Training
분야 및 배경지식
- representation learning: 유사한 예시의 경우 가까이 위치하고, 다를 경우 멀리 떨어져 위치하는 임베딩 공간을 학습하는 연구분야
- contrastive learning: 유사한 후보들과 유사하지 않은 후보들이 주어졌을 때 분류하는 문제로 정의되는 경우가 많음
문제점
- 임베딩의 중요성
- 좋은 임베딩은 많은 어플리케이션, downstream tasks에 중요
- 데이터의 시각화에 사용될 수 있음
- 기존 연구의 한계
- 다른 케이스에 대해 다른 모델들을 사용 (다른 데이터셋/학습목표/모델 아키텍처 등)
해결책
Contrastive Pre-training on paired data
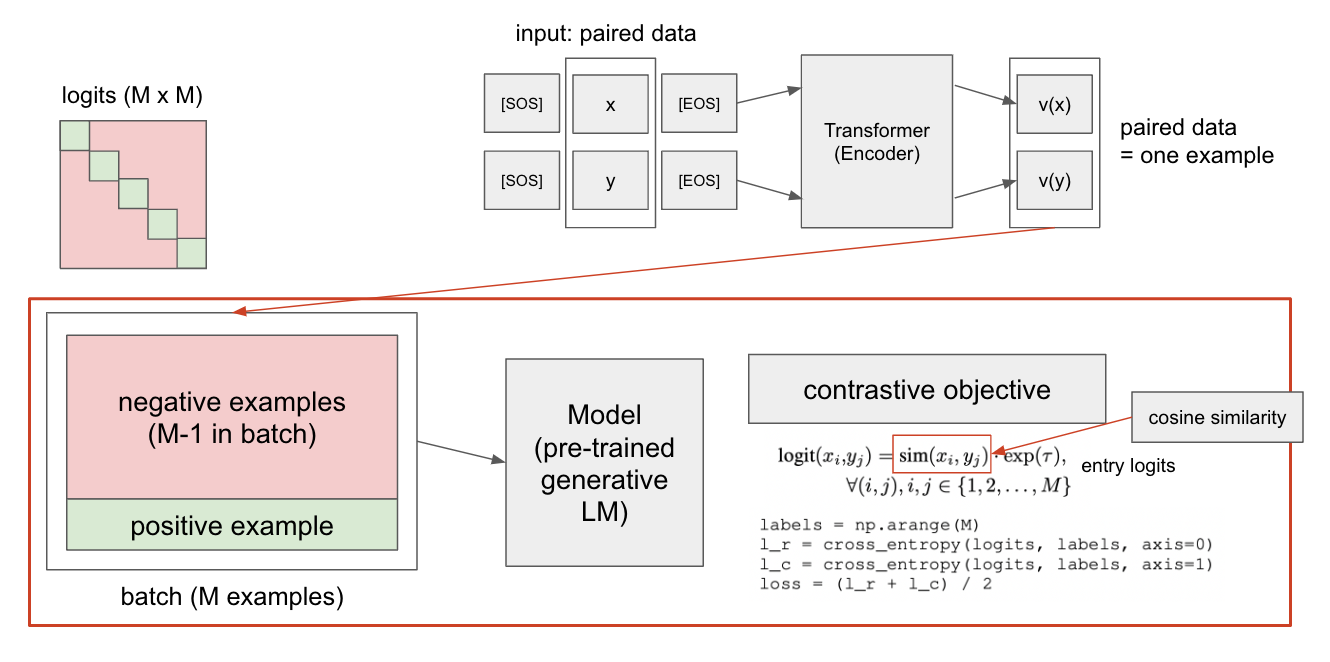
- unsupervised paired data
- text의 경우 인터넷 상에서 근처에 위치한 텍스트들을 positive pair로 취급
- code의 경우 (text, code)를 하나의 쌍으로 취급
- 이해한 바에 따르면, 하나의 paired data가 하나의 example이라고 생각하는 게 맞을 것 같다
- in-batch negatives
- M개의 예시들을 가진 미니배치에서, 자기 자신을 제외한 나머지 예시들(M-1)을 negative examples로 취급
- logit은 M x M의 형태를 띄고 있으며, 해당 행렬의 대각선에 위치한 부분(즉, 자기 자신)만을 positive example로 취급
- large batch
- 배치의 크기가 클수록 성능이 향상됨을 밝힘
- pretrained model for initialization
- 모델의 초기화는 사전학습된 모델로 진행, 텍스트의 경우 GPT / 코드의 경우 Codex
- 이전의 연구들과는 다르게, 동일한 모델이 여러 문장 임베딩 벤치마크에서 좋은 성능을 보임을 밝힘
평가
- 텍스트 임베딩 (SentEval)
- linear-probe classification
- 비지도학습: SOTA
- 전이학습: SNLI, MNLI에 대해 파인튜닝, SOTA
- zero-shot and k-NN classification
- 태스크 및 데이터셋: SST-2 binary sentiment classification task, NLI에 대해 파인튜닝
- zero-shot: 인풋 텍스트 임베딩에 가장 가까운 임베딩을 가진 레이블(정답)을 선택, 데이터셋이 처음 나왔을 때 지도학습으로 학습된 뉴럴 네트워크보다 더 좋은 성능을 보임
- k-NN: 임베딩 공간에서 인풋과 가장 가까운 레이블(정답)을 선택
- sentence similarity
- 기존의 SOTA보다 약한 성능
- 이유 분석 / defense
- 문장의 유사성은 상대적으로 잘 정의된 태스크가 아님 (어떤 문장의 유사성이 더 높다고 판단할 수 있는가?)
- search task와 sentence similarity task에 서로 모순이 존재할 수 있음 (저자들은 모델 학습 시에 search와 classification에 더 높은 가중치를 두었다고 밝힘)
- 이전의 문장 임베딩 search 연구들은 문장의 유사성에 대한 성능을 분석하지 않음
- linear-probe classification
- 텍스트 찾기
- 이전 연구들의 한계
- 특정한 텍스트 찾기 데이터셋에 대해 파인튜닝 필요
- 일반적으로 여러 번의 단계를 거쳐야 함 (cross-attention과 같은 expensive한 마지막 단계를 포함하는 경우가 많음)
- 해당 모델의 강점
- 단일한 임베딩 모델을 사용
- 문서 당 오직 하나의 dense embedding을 계산 (cross-attention이나 re-ranker 없음)
- large-scale search
- 벤치마크: MSMARCO, NQ, TriviaQA
- 논문의 비지도 모델이 기존의 비지도 방식보다 뛰어난 성능을 보일뿐만 아니라, TriviaQA의 경우 파인튜닝한 모델과 유사한 성능
- BEIR search
- 11개의 zero-shot search task
- 논문의 비지도 모델이 MSMARCO 데이터로 지도학습된 기존의 방식들과 유사한 성능, 전이학습의 경우 최고의 성능을 보임
- 이전 연구들의 한계
- 코드 찾기
- Code Search
- 벤치마크: CodeSearchNet
- SOTA 성능
- 텍스트 임베딩이 특히 파이썬에 대해 code search에서 상당히 뛰어난 성능을 보임 (코드 임베딩이 아님에도!)
- Code Search
한계
- 큰 배치 사이즈를 사용, 상당히 큰 컴퓨팅 자원을 필요로 함
- 학습 데이터에 존재할 수 있는 편견에 대한 고려가 없음
의의
- 비지도학습 데이터로 학습한 하나의 모델이 여러 문장 임베딩 태스크에서 좋은 성능을 보임을 밝힘

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab
M개의 sentence끼리 similarity를 계산할때, 자기자신은 반드시 1이 되어서 어떻게 보면 학습 할때, negative samples만 가지고 학습을 하게 되는 셈인데, 제가 이해한게 맞나요?