InstructGPT
- 프롬프트에 제시된 사용자의 설명(instruction)에 맞춰 자세한 응답을 제공
등장 배경
- 뛰어난 성능을 보이는 GPT-3 언어모델은 별도의 학습 없이 프롬프트를 통해 자연어 태스크를 수행하는 등의 발전을 보였으나, 사실이 아니거나(untruthful), 편향적이거나 해로운 결과(toxic, harmful)를 생성하기도 했음
- 이는 GPT-3가 거대한 인터넷 코퍼스의 다음 단어를 예측하는 방식으로 학습되었기 때문
- 사용자가 원하는 태스크를 안전하게 수행하는 방식으로 학습된 것이 아님 (= model is not aligned with users)
학습 방법
Reinforcement Learning from Human Feedback
- 사람의 선호를 보상 신호로 활용해 모델을 사전학습
- 사람의 선호는 모델의 안전성과 사용자와의 alignment에 중요한 요소
- 이러한 학습방법을 통해 GPT-3가 이미 갖고 있었지만 단순한 프롬프트 엔지니어링으로는 유도하기 어려웠던 능력을 드러낸다고도 이해할 수 있음
- 하지만 이런 학습방법은 사용자의 태스크에 align하려다보니 기존의 학술적인 자연어처리 태스크의 성능이 떨어질 수도 있다는 단점을 가짐 (alignment tax)
- 이를 해결하기 위해 RL-finetuning 시에 GPT-3 사전학습 시 사용했던 본래 데이터의 일부를 섞어서 사용
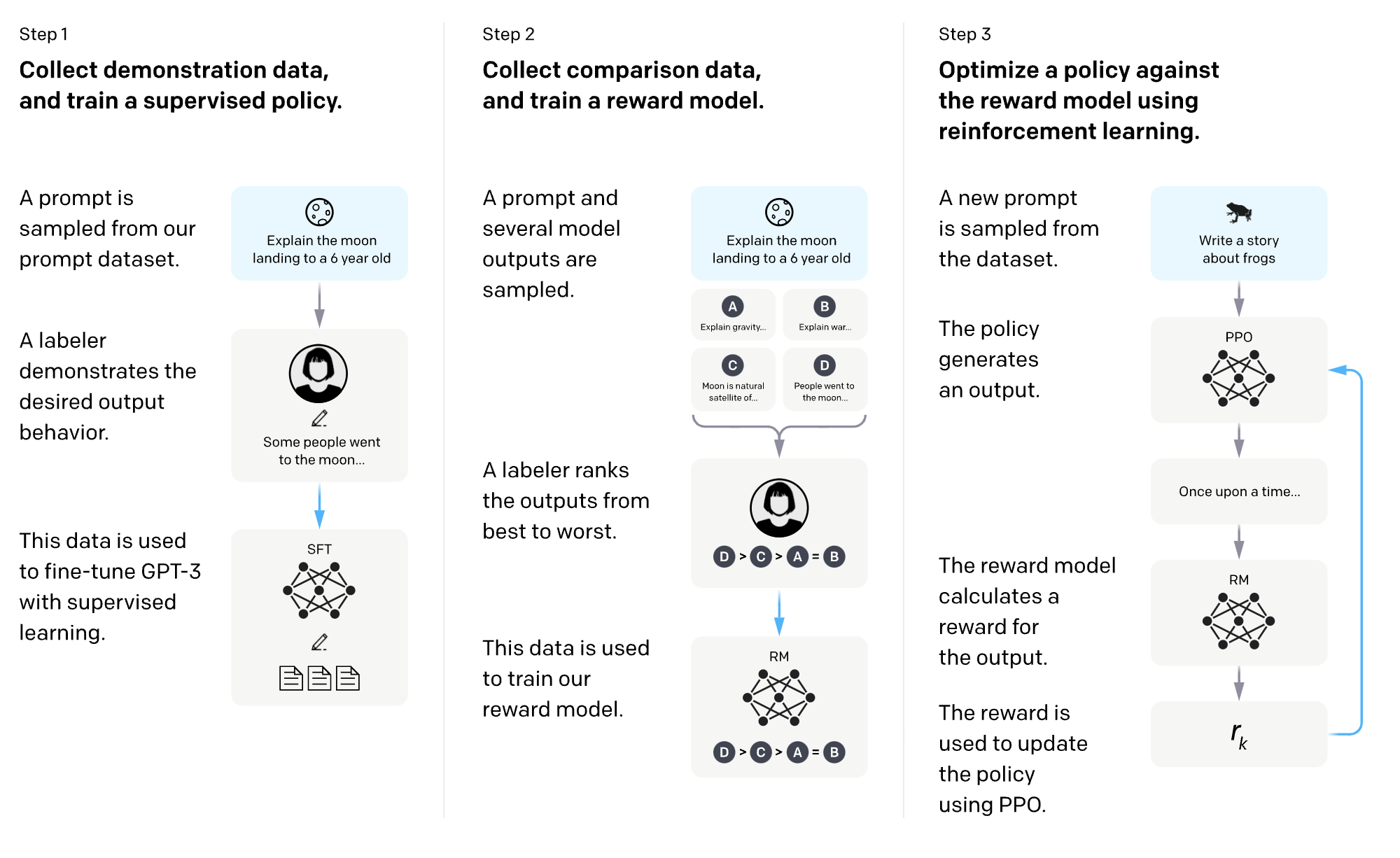
1. 예시(=demonstration) 데이터 수집 및 지도학습 방식으로 policy(=model) 학습
- prompt dataset에서 프롬프트를 샘플링
- e.g. 6살 아이에게 달에 착륙하는 것을 설명하라
- labeler(사람)가 바람직한 결과 예시를 작성
- e.g. 몇몇 사람들은 달에 가고 싶어하였다 ...
- 지도학습 방식으로 GPT-3 policy(model) 파인튜닝
2. 비교 데이터 수집 및 보상(=reward) 모델 학습
- 프롬프트와 모델이 만든 여러 결과를 샘플링
- labeler(사람)가 모델이 만든 결과에 순위를 매김
- 해당 데이터는 보상(reward) 모델을 학습하는 데에 사용
3. 강화학습을 활용해 보상 모델로 policy(model) 최적화
- 데이터셋에서 새로운 프롬프트 추출
- policy(=model)가 결과 생성
- 보상 모델은 해당 결과에 대한 보상(=reward)을 계산
- 보상은 PPO 알고리즘을 활용해 policy를 업데이트하는 데에 사용
개선점
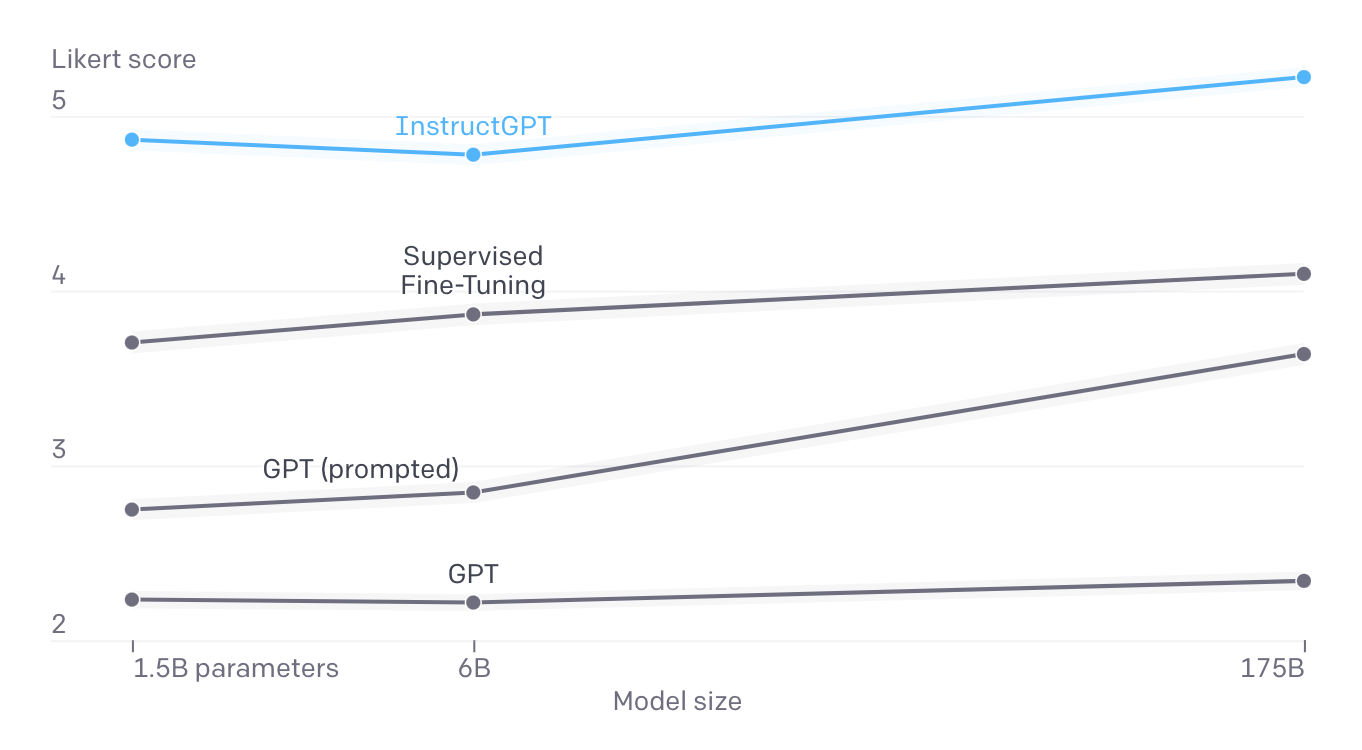
- 명확한 설명(instruction)이 없어도 프롬프트를 통해 내재적으로 정의된 태스크를 이해 (like GPT-3)
- GPT-3에 비해 사용자의 의도를 더 잘 이해
- 175B GPT-3에 비해 훨씬 적은 파라미터 (1.3B)
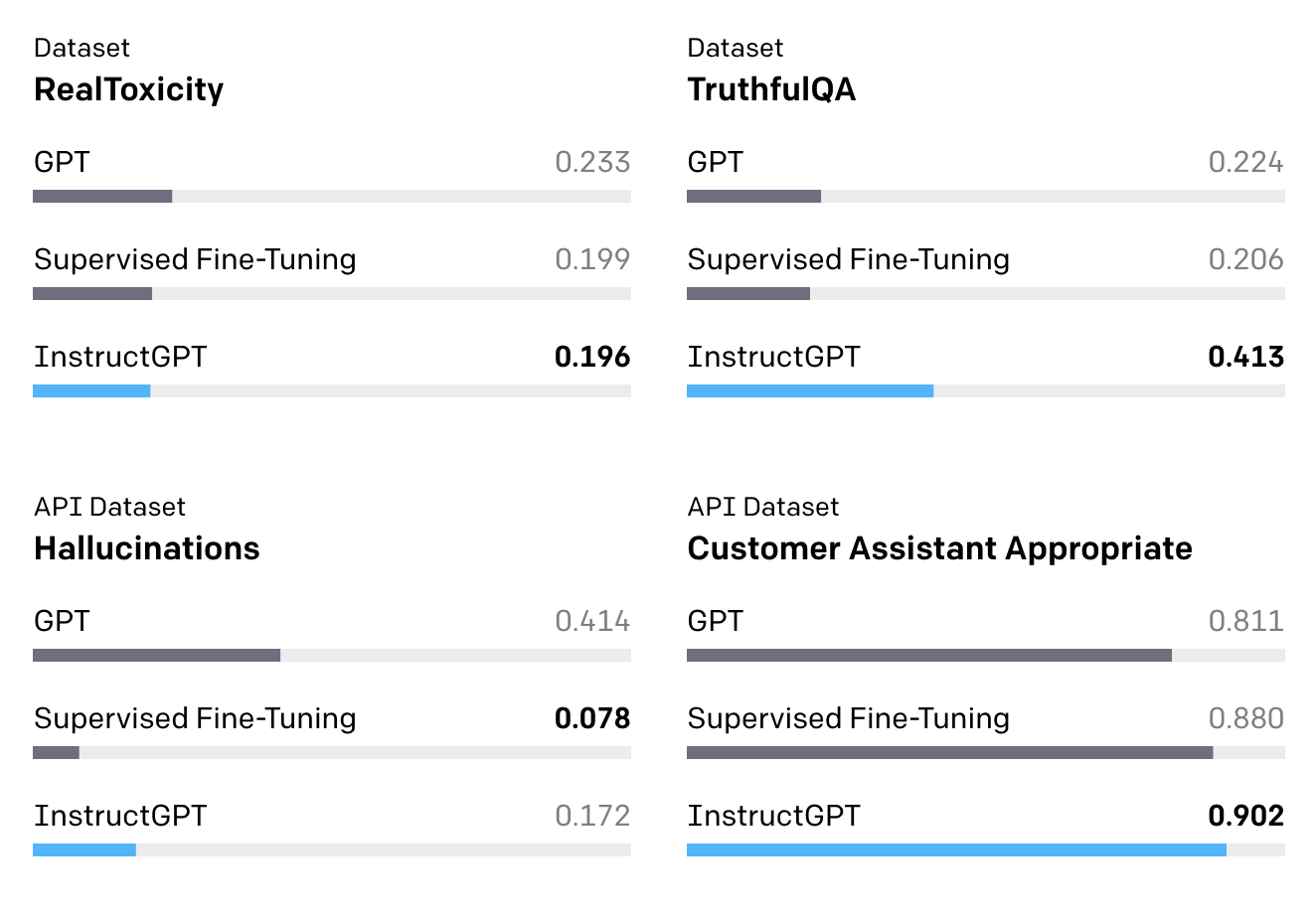
- GPT-3에 비해 사실이 아니거나(untruthful), 편향적이거나(biased), 해로운(toxic) 결과를 덜 생성
- 학술적인 자연어처리 데이터셋을 활용해 설명(instruction)을 따르도록 학습한 FLAN이나 T0 대비 현실성 있는 (practical) 상황에서 유리
한계
- GPT-3 대비 안전성이 높아졌으나, 여전히 해롭거나 편향된 결과를 생성하거나, 없는 사실을 만들어내고, 성적이고 폭력적인 결과를 생성하기도 함
- 사용자의 설명을 따를 수 있도록 모델을 학습하였기 때문에, 사용자가 어떠한 설명(instruction)을 사용하느냐에 따라 오용될 여지 존재
- 평균적인 사용자의 선호에 맞추는 것은 바람직하지 않음
- minority group, non-English-speaking group, ...
ChatGPT
- 대화하는 방식으로 상호작용할 수 있는 모델로, InstructGPT의 형제 모델
- 2022년 초반에 학습된 GPT-3.5를 파인튜닝
학습 방법
Reinforcement Learning from Human Feedback
- InstructGPT와 유사한 학습 방식을 사용하였으나 데이터 수집 단계에서 약간의 차이 존재
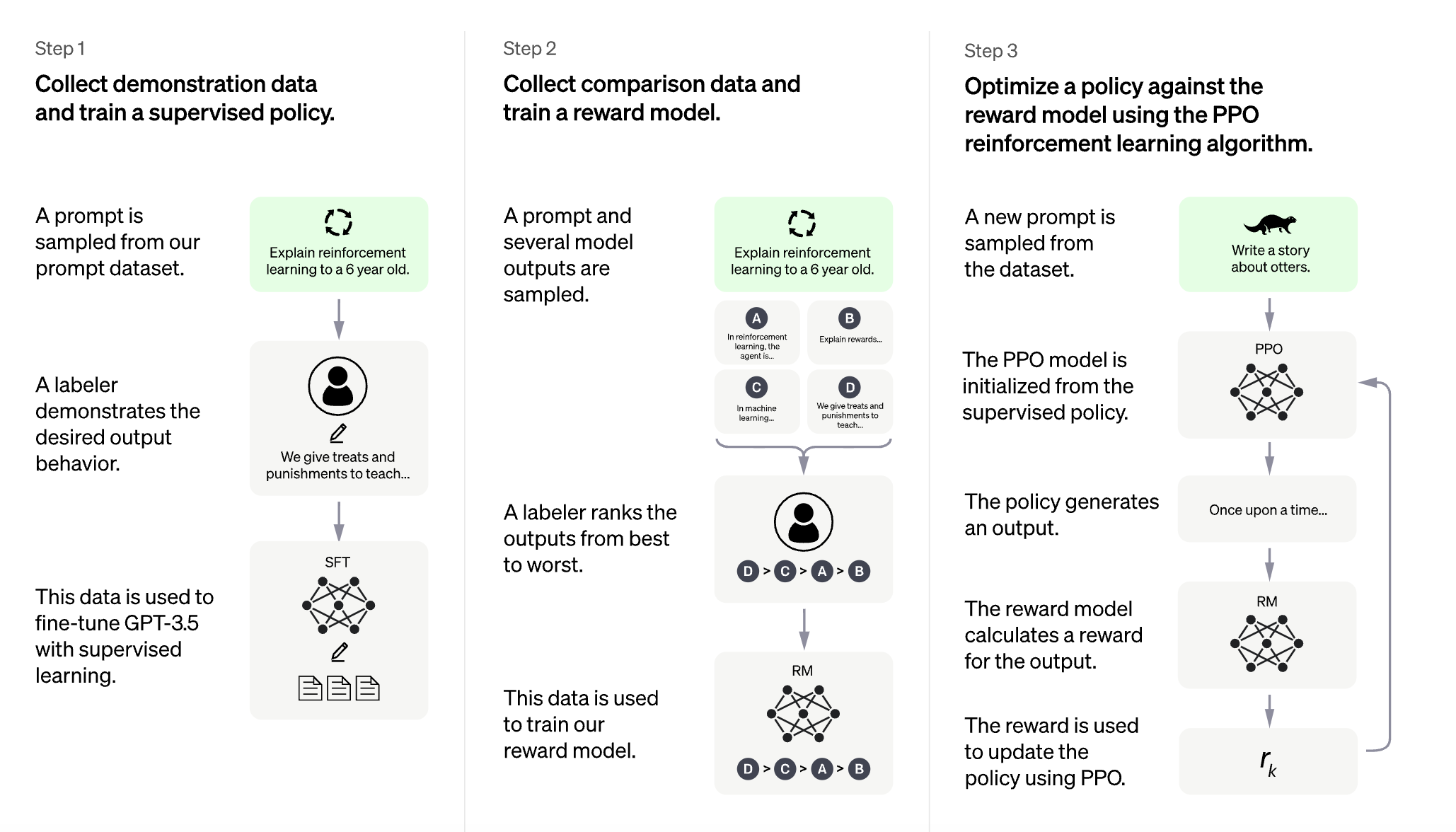
1. 예시 데이터 수집 및 policy 지도학습
- 지도학습을 위해 데이터를 수집할 때 AI 트레이너(사람)가 사용자와 AI assistant 양쪽의 대화를 모두 제공
- 이렇게 만들어진 새로운 대화 데이터셋을 대화형식으로 변경한 InstructGPT 데이터셋과 함께 사용
2. 비교 데이터 수집 및 보상 모델 학습
- 비교 데이터 생성을 위해 AI 트레이너가 챗봇과 대화를 하도록 한 후 랜덤으로 모델이 생성한 메시지를 선택하고, 몇몇 대체재(=alternative completions)를 샘플링
장점
- 연달아 나오는 질문에 응답 가능
- e.g. "it"이 무엇을 지칭하는지 이전 대화를 통해 파악
- e.g. 코드 디버깅 관련 질문에 대해 문제를 명확히 해달라고 요청 후 사용자 발화 뒤 응답
- 실수를 인정
- 옳지 않은 전제에 대해 반론을 제기
- 바람직하지 않은 요청에 대해 반대
- e.g. 불법적인 행동에 대한 질문에 대해 대답하기를 거부
한계
- 그럴듯하게 들리지만 틀리거나 터무니없는 대답을 작성하기도 함
- 이는 1) 강화학습 동안 무엇이 진실인지 알 수 없으며,
- 2) 모델이 더욱 신중해지도록 학습한다면 답을 할 수 있는 질문에 대해서도 대답을 거부하는 일이 발생할 수 있고,
- 3) 지도학습이 (사람이 아는 것이 아니라) 모델이 아는 것을 기반으로 이상적인 대답을 만들도록 잘못 리딩할 수도 있기 때문에 해결이 까다로운 문제
- 인풋을 비틀거나(e.g. paraphrase) 같은 프롬프트를 여러 번 시도할 때 취약
- 때때로 모델이 너무 수다스럽거나 특정 구절을 남용하기도 함
- 사용자가 모호한 쿼리를 제공했을 때 문제를 명확히하는 질문을 던져야 하나 현재 모델은 대개 사용자의 의도를 추측
- 여전히 해로운 질문에 답하거나 편향적인 행동을 보이기도 함

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab