K-ADAPTER: Infusing Knowledge into Pre-Trained Models with Adapters
ACL-IJCNLP 2021
분야 및 배경지식
- Injecting knowledge into pre-trained model
- 사전학습된 모델에 지식을 주입하는 연구분야
- 해당 논문은 관련하여 여러 과거 연구들을 나열(ERNIE, LIBERT, SenseBERT, KnowBERT, WKLM, BERT-MK)
문제
- 언어모델이 풍부한 지식을 얻기 위해서는 모델에 지식을 주입하는 것이 필요하나, 다양한 종류의 지식을 주입할 시 과거에 얻은 지식을 잊게 됨
해결책
K-adapter
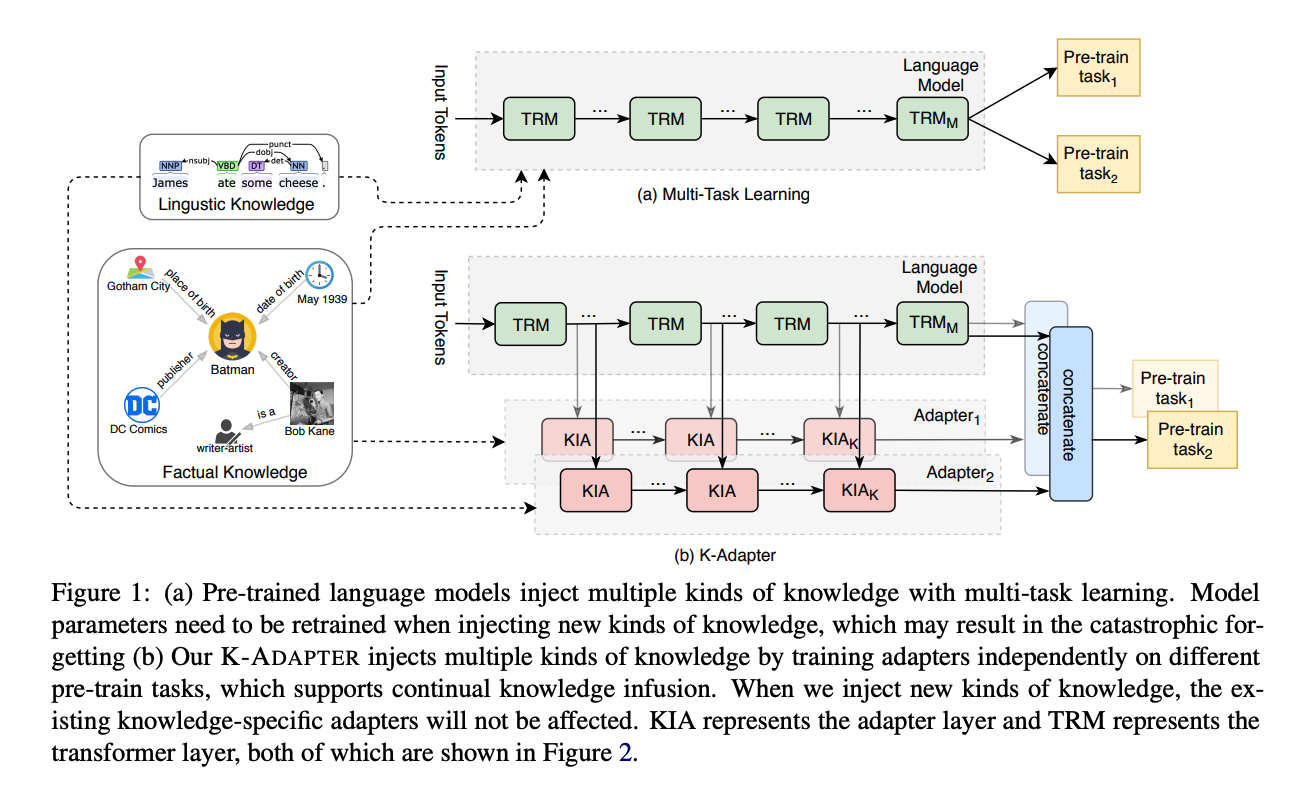
- knowledge-specific adapter
- 다른 종류의 지식들은 별도의 작은 뉴럴 모델을 통해 주입됨 (작은 뉴럴 모델 = adapter)
- outside plug-ins
- 각각의 Transformer layer 안에 삽입되는 다른 어댑터 구조와 달리 사전학습된 모델 바깥에 추가됨
- factual and linguistic
- 사실적 지식을 위한 어댑터와 언어적 지식(=통사론, 의미론)을 위한 어댑터를 별도로 사전학습
- factual adapter 학습을 위해서 sub-dataset T-REx-rc from T-REx를 사용해 개체들 사이의 관계를 파악하도록 사전학습
- linguistic adapter 학습을 위해 Stanford Parser의 off-the-shell dependency parser를 이용해 Book Corpus에서 의존관계 예측(dependency relation prediction)하도록 사전학습
평가
- 태스크
- 개체 유형파악(Entity typing)
- 질의응답(Questiong answering)
- 관계 분류(Relation classification)
- 데이터셋
- OpenEntity, FIGER (개체 유형파악)
- CosmosQA, Quasar-T, SearchQA (QA)
- TACRED (관계 분류)
- 평가지표
- micro F1 score(OpenEntity)
- accuracy, loose macro F1, loose micro F1(FIGER)
- accuracy (CosmosQA)
- ExactMatch, loose F1 (SearchQA, Quasar-T)
- micro F1 (TACRED)
의의
- 사실적 지식(Factual knowledge)뿐만 아니라 언어적 지식(Linguistic knowledge)의 학습 또한 고려
- catastrophic forgetting을 방지하고 연속적인 지식의 주입을 가능하게 함 (Continual Learning; 연속학습 지원)
- 기존 사전학습 모델의 파라미터는 고정, 새로 추가된 adapter에 대해서만 학습
한계
- 모델의 아키텍처 등에서 새로움이나 독창성이 떨어짐
- 성능 실험에서 K-adapter가 보여주는 gain(성능 향상 정도)이 적음
- continual learning(연속학습)의 catastrophic forgetting, 즉 새로운 지식을 배움으로써 과거에 배운 지식을 잊는 현상을 경감하고자 하였으나 CL의 또 다른 중요한 골자인 Knowledge transfer(지식전파)에 대한 고려는 부족

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab