KALA: Knowledge-Augmented Language Model Adaptation
NAACL 2022
분야 및 배경지식
- Language Model Adaptation (언어모델 적응): 최근에는 거대한 코퍼스에 모델을 사전학습(pretrain)시키고, downstream task에 대해 파인튜닝(fine-tune)하는 전이학습(transfer learning)이 주를 이룸. 도메인 특화 데이터에 대한 Language Model Adaptation에서는 타겟 도메인(DAPT) 혹은 타겟 태스크(TAPT)에 대한 adaptive pre-training이 제안되기도 함
- Knowledge-aware LM(Language Model): 사전학습 모델에 외부의 지식을 합치려는 다양한 연구들이 진행됨.
- 사전학습 시 개체정보(knowledge graph embedding)를 추가적인 인풋으로 활용하는 ERNIE, KnowBERT
- 사전학습 시 개체 메모리(entity memory)를 활용하는 Entity-as-Experts, LUKE
- 사전학습 시 사실(fact)을 구성하는 entity, relation을 활용하는 ERICA
문제점
- 사전학습모델(pre-trained language model)을 특정 도메인에 맞추어 조정하는 연구 활발
- 단순한 파인튜닝(fine-tuning)은 도메인 특화 태스크에 있어 최적이 아님
- 적응가능한 사전학습(adaptive pre-training)은 도메인 특화 지식을 얻을 수 있으나 많은 비용이 발생할 수 있으며 이전에 학습한 일반적 지식을 잊는 catastrophic forgetting을 겪을 수 있음
해결책
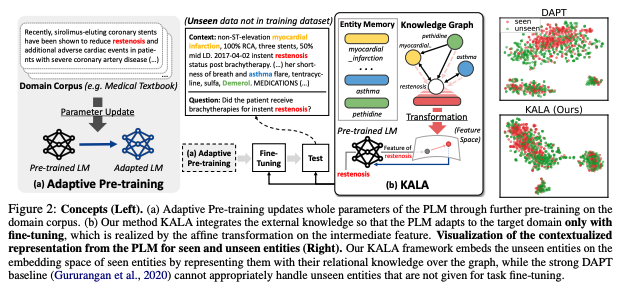
KALA (Knowledge-Augmented Language model Adaptation)
- 개체(entity)와 관계(relation)로 표현되는 도메인 지식을 활용해 사전학습 모델의 intermediate hidden representation을 조절 (언어모델 위에 추가적인 레이어를 쌓는 방식이 아니라, 도메인에 기반한 지식을 언어모델의 사전학습 파라미터에 interleave)
- Entity Memory: 사전학습 모델의 파라미터와는 독립적인 개체 임베딩(entity embedding)의 source. entity를 key로, 개체의 임베딩을 value로 포함하며 EntEmbed 함수를 통해 개체의 임베딩을 return
- Knowledge Graph(KG): 개체(entity) 사이의 사실관계를 표현. factual triplet {(h, r, t)}로 나타내며 h, t는 entity, r은 relation을 의미
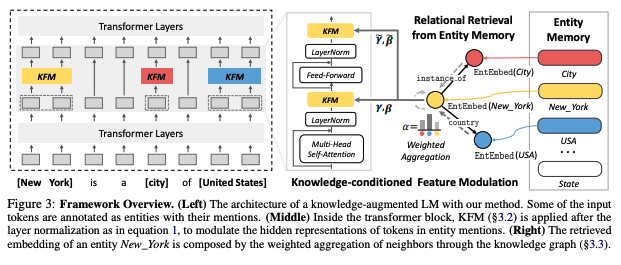
- KFM(Knowledge-conditioned Feature Modulation): retrieved knowledge representation을 이용해 사전학습 모델의 intermediate hidden representation을 조정하고 변화시키는 새로운 레이어
- function h: entity, mention, knowledge graph, trainable param π를 이용해 도메인 지식에 기반해 사전학습모델을augment. 감마, 베타를 return하며 해당 감마, 베타는 layer normalization 이후 KFM에서 사용됨
- 감마, 베타: function h로부터 얻은 학습 가능한 modulation prameter. EntEmbed 함수로부터 얻은 개체의 임베딩을 input으로 사용하며, 각 감마와 베타는 상호 독립적인 h 함수를 사용(h: multi-layer perceptrons)
- relational retrieval: 단순히 entity memory에서 임베딩을 가져오는 것은 모든 unseen entity를 같은 null entity로 여기게 되는 단점 존재. 이를 해결하기 위해, 두 개체 사이의 relational information을 반영한 knowledge graph를 사용. knowledge graph에 존재하는 Entity 사이의 관계를 효과적으로 활용하고 EntEmbed 함수를 개선하기 위해 GNN(graph neural network), attentive scheme을 활용
- 자세한 구현이나 수식, objective 등은 논문 및 github 참고
평가
- QA (Question Answering)
- dataset: NewsQA, EMRQA
- metrics: Exact-Match, F1
- NER (Named Entity Recognition)
- dataset: CoNLL-2003, WNUT-17, NCBI-Disease
- metrics: F1
의의
- 본래의 사전학습 모델 아키텍처를 수정하지 않기 때문에 어느 사전학습 모델에도 적용 가능
- 연산 효율적 (required marginal computational and memory overhead)
- 이전의 knowledge-aware LM 관련 연구들은 사전학습 시를 고려, 해당 연구는 linear modulation layer scheme을 활용해 finetuning, test 단계에서 PLM을 domain specific task에 대해 효율적으로 수정할 수 있도록 함
- KFM의 장점
- multiple tokens associated to the identical entity are affected by the same modulation, which allows the PLM to know which adjacent tokens are in the same entity
- by using relational retrieval with knowledge graph using GNN, richer interactions among entities are considered and unseen entity can be represented
- adaptive pre-training을 뛰어넘는 SOTA 성능
한계
- 해당 논문에서 언급한 knowledge-aware LM의 경우 외부 지식을 언어모델에 통합하려 한다는 점에서 external knowledge edit (memory augmented knowledge model) 쪽 연구와 연관성이 높아보임. 해당 연구분야에서 사전학습 기반의 연구가 주로 행해졌는지 literature search 필요
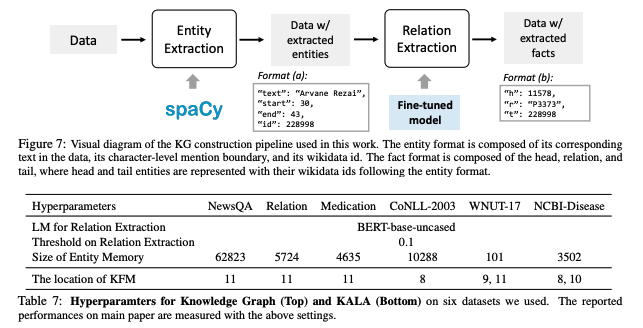
- interleaving method를 설명하는 과정이 다소 복잡하고 비직관적
- entity memory와 knowledge graph는 wikidata 기반으로 구축되어 향후 재사용이 가능하다는 장점이 있으나, appendix를 읽기 전에는 finetuning 시마다 재구축이 필요한지 파악이 어려웠음
- KFM은 attentive GNN을 사용해 reltation을 반영한 entity embedding을 구축하고 이를 input으로 활용해 multi-layer perceptron에서 learnable modulation param인 감마, 베타를 학습. 이 과정이 다소 복잡하게 설명되어 있어서 개괄적 설명이 먼저 있었으면 어땠을까 하는 아쉬움

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab