Time-Aware Language Models as Temporal Knowledge Bases
TACL 2022
분야 및 배경지식
Langauge Model as Knowledge Base
- 언어모델은 세상 지식의 저장소로 알려짐 (linguistic knowledge, factual knowledge를 저장)
- 관련하여 LAMA 논문이 유명 (Language Model as Knowledge Bases?)
문제점
- 대부분의 언어모델은 특정 순간에 수집된 데이터들을 기반으로 학습되나 많은 사실들은 시간에 따라 변화, 유용성에 한계
- averaging: 언어모델은 시간적인 메타데이터를 일반적으로 무시하기 때문에, 시간에 따라 달라지는 사실들을 단순히 평균화시켜(averaging effect) 결과적으로는 옳은 정답에 낮은 confidence를 갖게 됨
- forgetting: corpora가 점차 증가(최신 문서들이 예전 문서들보다 많음)함에 따라 문서가 부족해 상대적으로 덜 대표되는(underrepresented periods of time) 시간동안 유효했던 사실들을 잊어버림
- poor temporal calibration: 시간이 지나도 변하지 않는 사실들과 시간에 따라 자주 변하는 사실들에 대해 모델이 다르게 어려움을 인식해야 함 (시간에 따라 사실이 바뀔지 여부에 대해 모델은 시간감각을 지니고 있지 않음)
해결책
TempLAMA
- 시간이 지남에 따라 변하는 factual knowledge를 언어모델로부터 확인(probe)할 수 있는 진단 데이터셋(diagnostic dataset for evaluation)

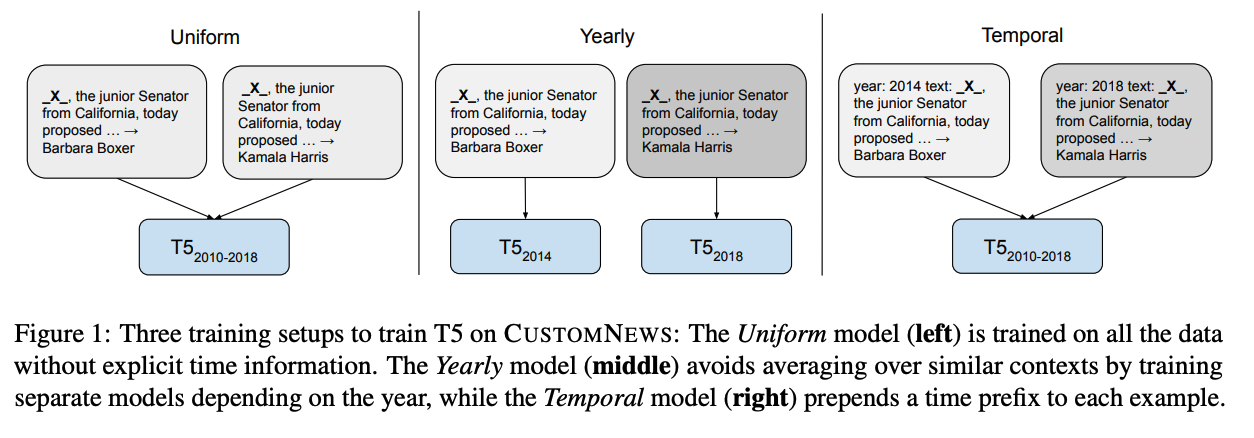
lightweight modification to pretraining
- 타임스탬프와 텍스트를 함께 학습하는 간단한 기법 제안
- Masked Language Modeling objective 사용: 파라미터는 텍스트와 시간의 representation을 학습
- Salient Span Masking: named entity와 date에 해당되는 부분을 salient span y로 두고 masking 및 학습 진행(이는 세상의 지식을 더욱 잘 반영하는 input을 구성하는데 도움을 줌)
- 시간대별로 균일하게 샘플링된 학습 코퍼스의 document로 사전학습 진행 (2010-2018 뉴스 데이터 CustomNews 활용)
- TempLAMA의 쿼리를 잘 이해하기 위해 1/1000의 비율로 TempLAMA 데이터도 함께 학습
- 2019-2020 데이터의 경우 미래 데이터에 대한 성능을 확인하기 위해 테스트에서만 사용
평가
- metrics: token-level F1, multiple target의 경우 max F1
- dataset: CustomNews(pretrain), TempLAMA, CronQuestions(eval)
- 전체 시간에 대해서 text, timespan을 함께 학습한 Temporal Model의 경우 아래와 같은 finding 제공
- 사실이 여러 연도에 걸쳐 존재하는 (사실의 경우 변할 수도, 변하지 않을 수도 있음) TempLAMA 데이터셋에 대해 좋은 성능
- Uniform, Yearly 모델이 가질 수 있는 forgetting, averaging effect 완화
- 모델의 크기가 커질수록 성능이 향상됨
- Better calibration in the future
- 시간 컨텍스트와 함께 학습할 경우 2019-2020년 데이터(unseen)에 대해 더 높은 F1 점수를 보임
- 2019-2020년에 존재하는 바뀌지 않은(unchanged) 사실관계를 더욱 잘 예측
- 평가 데이터에서 학습한 부분과 학습하지 않은 부분 모두에 대해 더 낮은 Perplexity (low perplexity = better performance)
- 여러 개의 답을 갖고 있는 쿼리의 경우 Temporal model의 confidence가 빠르게 감소하는데, 이는 과거에 변화 경력이 있는 사실이 미래에도 변화할 수 있음을 반영한다고 해석할 수 있음
- constant fact에 대해서는 비교적 평평하고 낮은 entropy를 보여주며, 시간이 지남에 따라 자주 변하는 fact에 대해서는 entropy가 높음 (=uncertainty가 높음)
- 시간 컨텍스트와 함께 학습할 경우 2019-2020년 데이터(unseen)에 대해 더 높은 F1 점수를 보임
한계
- pretraining 기법이기 때문에 batch size가 2048, step size가 300K로 굉장한 양의 computation resource 필요 (environment effect)
- 단순한 접근법으로 Novelty가 떨어짐
- TempLAMA는 WikiData를 활용해 synthetic하게 만들어졌기 때문에 불완전하거나 부정확한 사실들을 포함할 수 있음
- ethical issues: 유명한 엔티티에 대한 일반적인 사실만을 모델에게 학습시켰기 때문에 스테레오타입을 강화하거나 공평하지 못한 결과를 야기할 위험 존재
- 연 단위로 시간을 나눴기 때문에 더 긴 혹은 더 짧은 시간 구분에 대한 탐구가 없었으며, during, before와 같은 시간을 내재하는 표현, 시간적 순서 및 사건 등에 대해서는 미고려
의의
- 시간 범주를 포함해 사전학습을 진행했을 경우 이후 데이터가 내재적으로 겹치지 않는 시간대로 나뉘기 때문에 미래의 데이터를 활용해 fine-tuning 시 유리
- 처음부터 새로운 데이터셋까지 모두 포함해 매번 학습을 새로 진행하는 것은 costly
- 새로운 데이터에 대한 단순한 fine-tuning의 경우 이전의 데이터를 잊어버릴 가능성 높음
- 다른 발견들의 경우 대개 normal했지만, fact의 변화주기 또한 PLM이 학습하고 예측할 수 있다는 연구결과가 굉장히 흥미로움

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab