강의 링크 (link)
사전학습

- 언어모델 학습의 첫 번째 단계
- 대량의 코퍼스를 활용해 다음 토큰을 예측하는 방식으로 학습
- 이를 통해 지식을 배운다고 알려짐
- 일반적인 사전학습 모델은 지시사항 (instruction) 등을 잘 따르지 못함
Multi-stage Continual Training
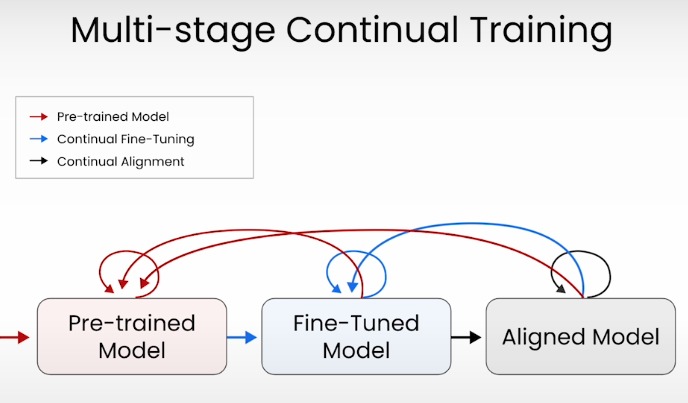
- ChatGPT나 BingSearch 등 사용자에게 제공되는 LLM은 아래와 같이 사전학습 단계 확장
- 사전학습
- 파인튜닝
- 지시사항(instruction, e.g. OO에 대해서 알려줘)을 잘 따르도록 학습
- 사람의 선호에 맞춤 (human preferences alignment)
- 언어모델이 안전하고 유용하게 작동하도록
- 2번과 3번은 모델로 하여금 새로운 행동 방식을 배우게 할 때 유용
- e.g. 특정한 방식으로 요약문을 작성해줘
- e.g. 특정 주제에 대한 답변은 피해줘
- 새로운 도메인에 대한 지식 학습이 필요하다면 1번 (사전학습) 필요
- 언어모델의 지식 습득은 데이터를 통해서 이루어짐
- 파인튜닝으로 지식을 일부 배울 수 있겠지만, 새로운 지식이 기존의 모델에 잘 표현되지 않았을 경우 한계 존재

FYI
- 재현(reproducibility)을 위한 seed 고정
def fix_torch_seed(seed=42):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False- stream 기능을 활용해 응답 생성하기
from transformers import TextStreamer
streamer = TextStreamer(
tiny_general_tokenizer,
skip_prompt=True, # If you set to false, the model will first return the prompt and then the generated text
skip_special_tokens=True
)
outputs = tiny_general_model.generate(
**inputs,
streamer=streamer,
use_cache=True,
max_new_tokens=128, # 최대로 생성되는 토큰 수
do_sample=False, # random output을 원한다면 True
temperature=0.0, # random output을 원한다면 값 변경
repetition_penalty=1.1
)
Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab