강의 링크 (link)
사전학습 데이터셋 vs. 파인튜닝 데이터셋
- 사전학습 데이터셋
- 많은 양의 비구조화된 데이터를 필요로 함
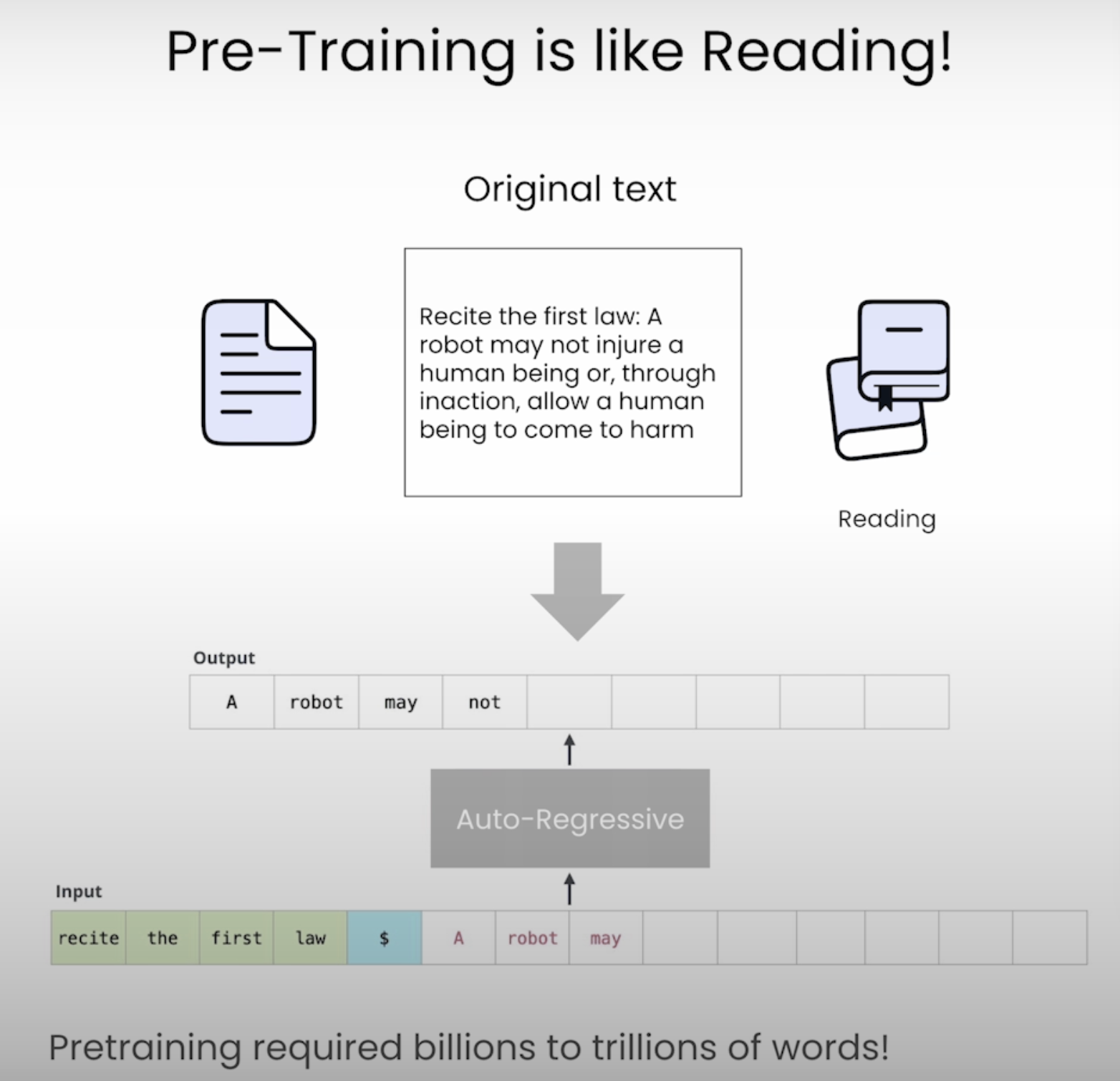
- 이를 이용해 반복적으로 다음 단어를 예측하는 방식, 즉 autoregressive text generation을 학습하고 세상에 대한 지식을 습득
- 책을 읽는 것과 유사
- e.g. 책, 코드, 기사, 위키, 웹문서, ...
- 많은 양의 비구조화된 데이터를 필요로 함
- 파인튜닝 데이터셋
- 구조화된 데이터를 활용
- 파인튜닝의 목적은 모델로 하여금 특정한 방식으로 작동하게 하거나, 특정 태스크를 잘 완수하도록 하는 것
- 시험을 치르는 것과 유사
- e.g. 사람이 작성한 질의응답 데이터셋, LLM이 만든 데이터셋, ...
- 구조화된 데이터를 활용
데이터셋 품질
- 나쁜 데이터
- 중복
- 오탈자
- 일관성 결여
- 환각 (=그럴듯한 거짓말)
- 유해성
- 좋은 데이터
- 유일 (unique, distinct)
- 정확하고 오류가 없음
- 일관성
- 검증됨
- 안전성
데이터 정제

- 중복 제거
- 특정한 패턴이나 예시에 편향성을 갖도록 할 수 있음
- 학습 시간을 불필요하게 늘림
- 품질 필터링
- 언어모델이 학습하고자 하는 지식과 관련된 주제, 학습하고자 하는 언어 등 원하는 품질 설정
- 품질과 관련없는 부분은 제거
- 내용 필터링
- 유해한 내용이나 편향적 내용 제거
- 프라이버시
- 개인정보 관련 내용 제거
- 규칙 기반 정제
- 불필요한 문장부호, 모든 문자 대문자 등의 데이터 규칙에 기반해 정제
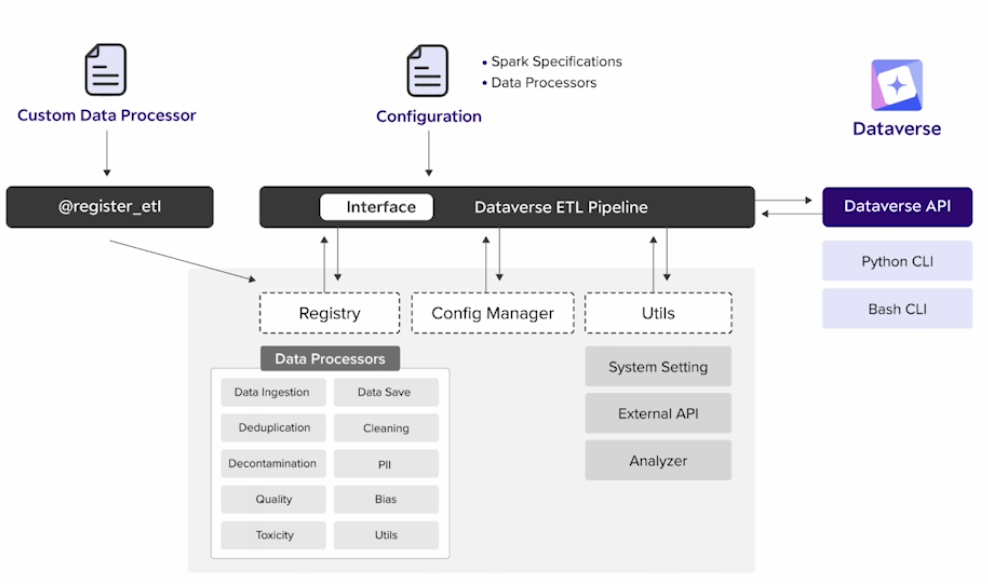
- Dataverse(Opensource)를 이용해 데이터 정제 자동으로 수행 가능
FYI
- 허깅페이스 데이터셋으로 변환하기
import datasets
code_dataset = datasets.Dataset.from_list(code_dataset)- 여러 개의 데이터셋을 하나의 데이터셋으로 합치기
import datasets
dataset = datasets.concatenate_datasets(
[pretraining_dataset, code_dataset]
)- 너무 짧은 데이터 제거
import heapq
import datasets
def paragraph_length_filter(x):
"""Returns False iff a page has too few lines or lines are too short."""
lines = x['text'].split('\n')
if (
len(lines) < 3 # 최소 3줄 이상
or min(heapq.nlargest(3, [len(line) for line in lines])) < 3 # 각 줄에 최소 단어 3개 이상
):
return False
return True
dataset = dataset.filter(
paragraph_length_filter,
load_from_cache_file=False
)- 텍스트 중복 제거 (within each example)
import re
import datasets
def find_duplicates(paragraphs):
"""
Use this function to find the number of repetitions
in the paragraphs.
"""
unique_x = set()
duplicate_chars = 0
duplicate_elements = 0
for element in paragraphs:
if element in unique_x:
duplicate_chars += len(element)
duplicate_elements += 1
else:
unique_x.add(element)
return duplicate_elements, duplicate_chars
def paragraph_repetition_filter(x):
"""
Returns False iff a page has too many repetitions.
"""
text = x['text']
paragraphs = re.compile(r"\n{2,}").split(text.strip()) # Split by paragraphs (2 or more newlines)
paragraphs_duplicates, char_duplicates = find_duplicates(paragraphs) # Find number of duplicates in paragraphs
if paragraphs_duplicates / len(paragraphs) > 0.3:
return False
if char_duplicates / len(text) > 0.2:
return False
return True
dataset = dataset.filter(
paragraph_repetition_filter,
load_from_cache_file=False
)- 텍스트 중복 제거 (from the entire dataset)
def deduplication(ds):
def dedup_func(x):
"""Use this function to remove duplicate entries"""
if x['text'] in unique_text:
return False
else:
unique_text.add(x['text'])
return True
unique_text = set()
ds = ds.filter(dedup_func, load_from_cache_file=False, num_proc=1)
return ds
dataset = deduplication(dataset)- 품질 필터링 (언어)
import urllib
from fasttext.FastText import _FastText
def english_language_filter(ds):
# load language detection model
model = _FastText('./models/upstage/L2_language_model.bin')
def is_english(x):
# Predict language of the text and probability
language, score = model.predict(x['text'].replace("\n", ""))
language = language[0].split("__")[2]
return score > 0.4 and language == "en" # change code here if building a model in another language
ds = ds.filter(is_english, load_from_cache_file=False, num_proc=1)
return ds
dataset = english_language_filter(dataset)- 데이터셋 parquet 형태로 저장
- json, csv 등 다른 형태 저장도 가능하나 빅데이터에서 많이 사용되고 빠르기 때문에 선택했다고 함

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab